1.mysql架构
mysql架构
-
mysql的基础架构图
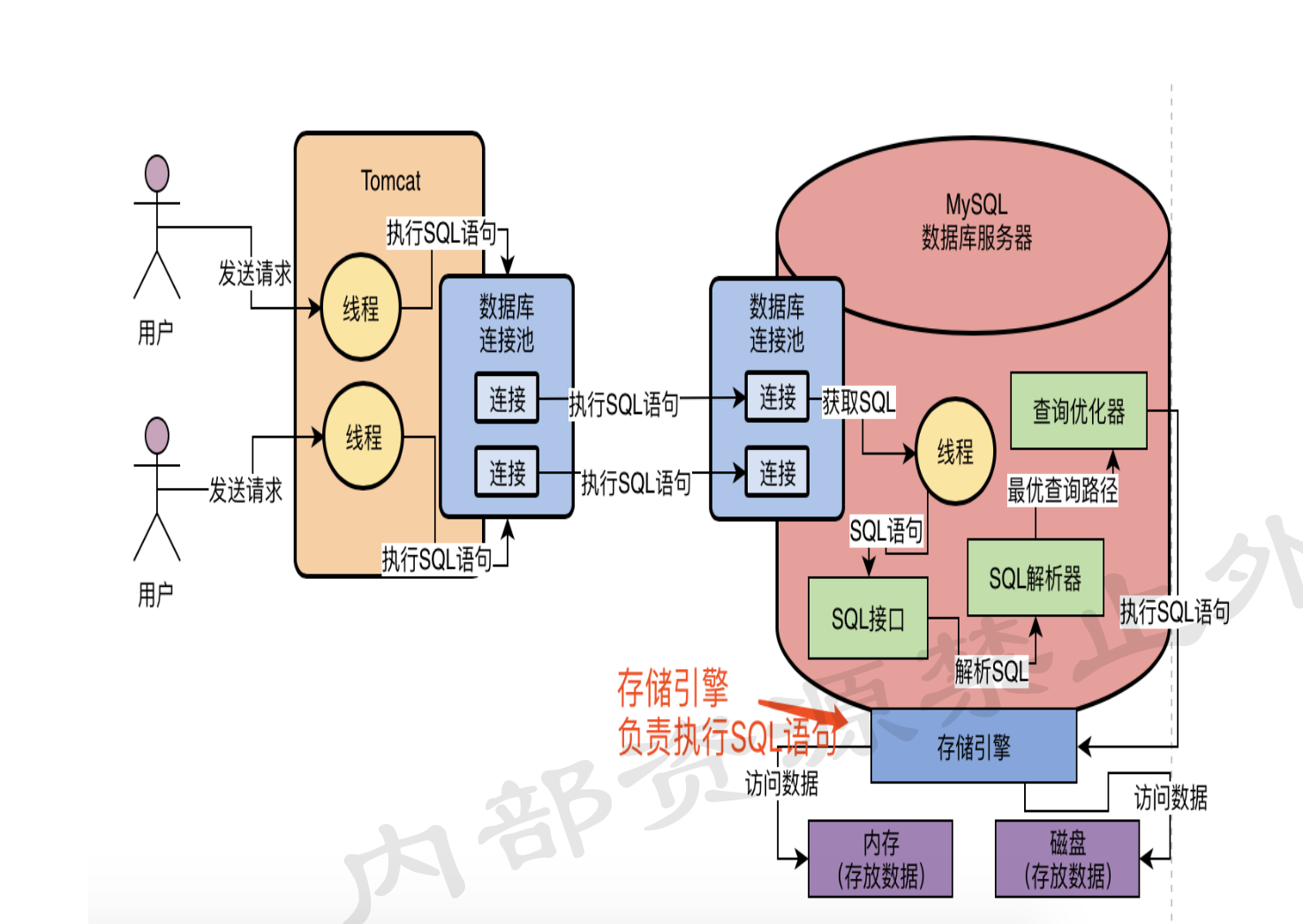
- 连接器
- 建立连接,管理连接,校验身份
- 查询缓存(8.0去掉了)
- 查询语句是否命中则直接返回,否则继续执行下去
- 解析SQL
- 对SQL查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块获取表名、字段、语句类型,不会检测表或字段是否存在
- 执行SQL
- 预处理阶段:检
- 检查表或字段是否存在,将
select *中的*符号扩展为表上的所有列
- 检查表或字段是否存在,将
- 优化阶段:
- 基于查询成本的考虑,选择查询成本最低的执行计划
- 执行阶段:
- 根据执行计划执行SQL查询语句,从存储引擎读取记录,返回给客户端
- 预处理阶段:检
- 连接器
-
说一下数据库的三大范式
- 第一范式
- 确保每列的原子性(即列不能再分为其他几列)
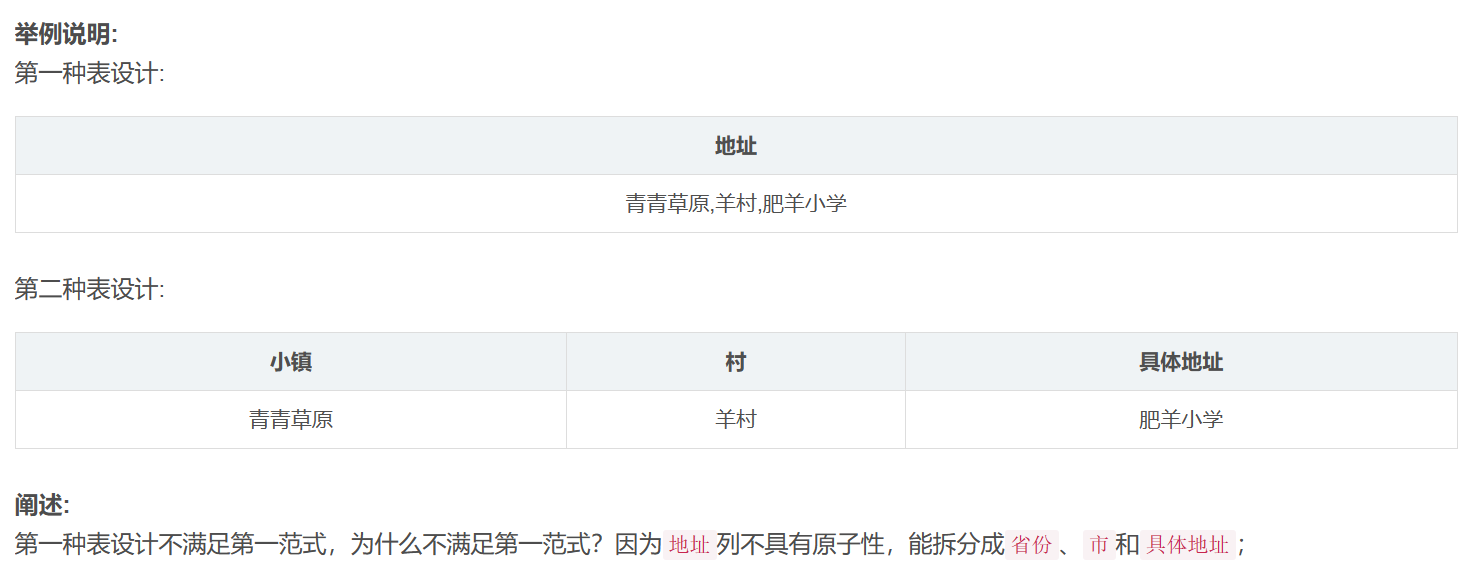
- 第二范式
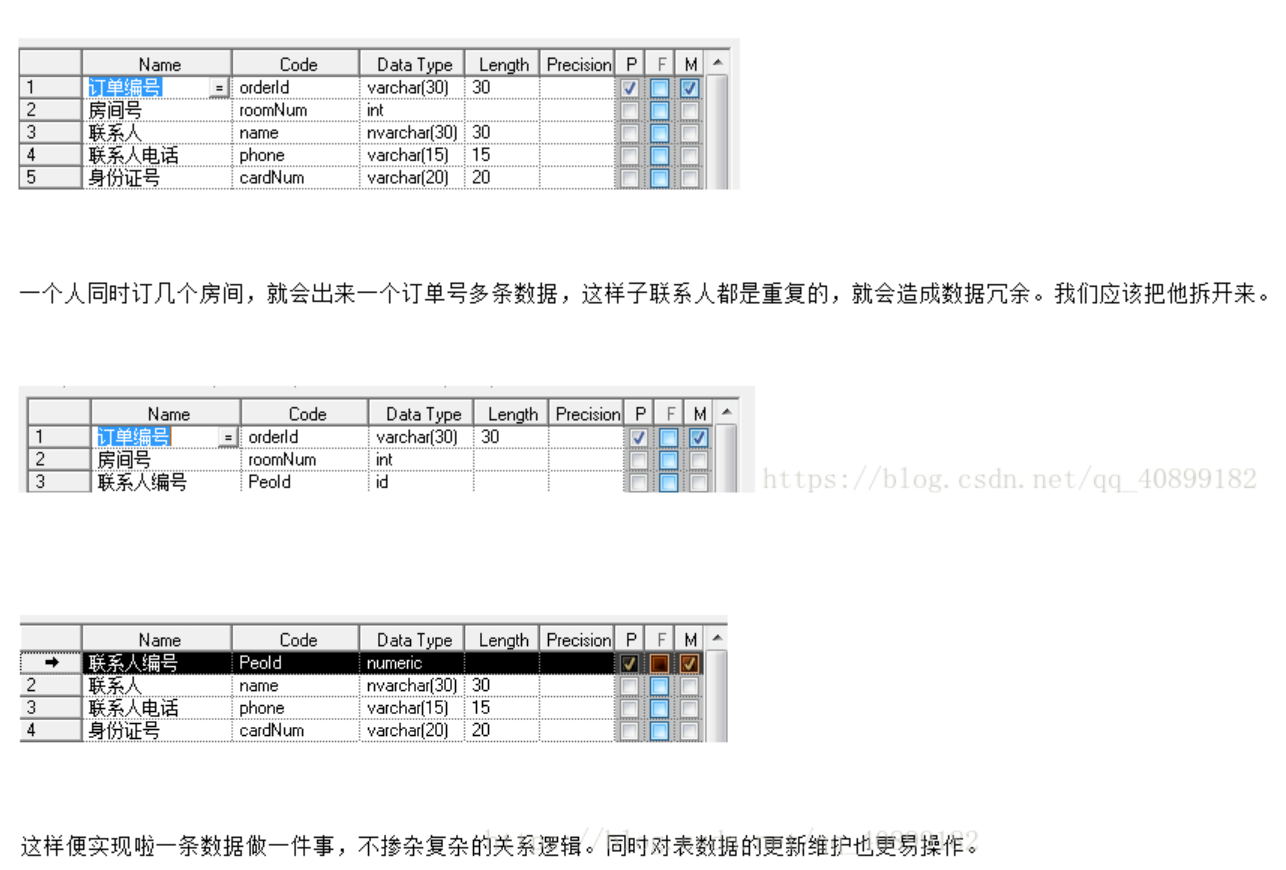
- 是在第一范式上建立起来的,即满足第二范式必须满足第一范式
- 要求确保每个数据表每列与主键相关,而不能只与主键的某个部分相关(主要针对联合主键)(每一行的数据只能与其中的每一列相关,即一行数据做一件事)
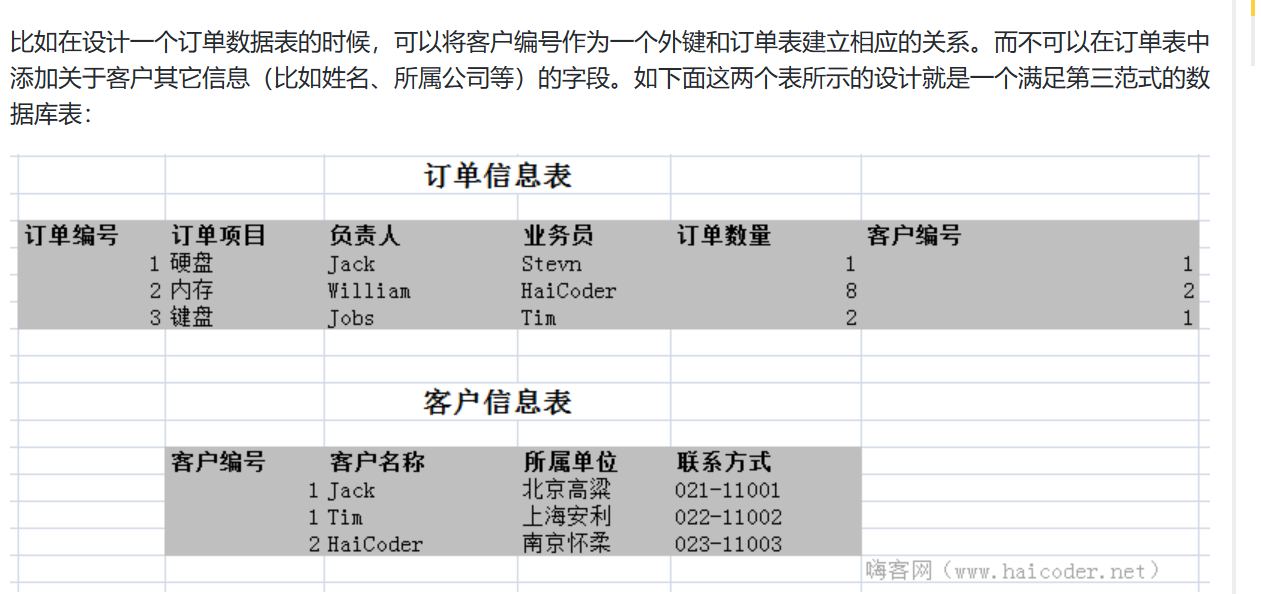
- 第三范式
- 确保数据表中每一列数据都与主键直接相关,而不是间接相关
- 第一范式
-
mysql有关权限的表是哪几个
- user:记录允许连接到服务器的用户账号信息,里面的权限是全局的
- db:记录各个账号在各个数据库的操作权限
- table_priv:记录数据表级的操作权限
- columns_priv:记录数据列级的操作权限
- host:配合db权限表对给定主机上数据库级操作权限作更细致的控制
- Mysql访问控制流程过程:
- 用户连接检查阶段:
- 当用户连接时,先从user表中的Host,User,Password这三个字段中判断连接的ip,用户名,密码是否存在,匹配不到则拒绝该连接
- 检查user表的max_connections和max_user_connections,如果超过上限则拒绝连接
- 检查user表的ssl安全连接,如果有配置ssl则需要确定用户提供的证书是否合法,只有上面3个检查都通过后,服务器才建立连接,连接建立后,当用户执行sql语句时,做sql语句执行检查
- 执行SQL语句时的检查
- 从user表里检查max_question和max_updates,如果超过上限则拒绝访问,下面几步是权限检查
- 通过身份认证,进行权限分配,按照user,db,tables_priv,columns_priv 的顺序进行验证,即先检查全局权限表user,如果user中对应的权限为Y,则此用户对数据库的权限都为Y,将不再检查db
- Mysql检查权限是一个复杂的过程,启动会将这5张权限表加入到内存
- 用户连接检查阶段:
-
innoDb引擎的4大特性,区别
-
插入缓冲(Insert buffer/Change Buffer)
- 产生的原因:索引存在在磁盘,主键索引由于天然自增,无须磁盘的随机IO,只需要不断追加,但普通的索引大概率无序,默认情况下需要进入随机磁盘IO操作,效率差(为了解决普通索引插入效率低下)
- 提升插入性能,Change Buffer是Insert buffer的加强,insert buffer 只针对 insert 有效,Change Buffer对Insert,delete、update(delete+insert)、purge 都有效
- 对于普通索引(非聚集索引)不是直接插入到索引页,而是先判断插入的非聚集索引页是否存在缓存池中,如果在直接插入,否则放入Insert buffer对象中,然后以一定频率和辅助索引页子节点进行合并操作,通常能将多个插入合并到一个操作中,提升插入性能
- 条件:1. 普通索引(非聚簇索引),2. 非唯一索引如果要保证唯一,每次操作还的去判断当前索引值是否存在,又涉及磁盘随机io)
-
二次写
-
自适应哈希(AHI)
- 该属性通过 innodb_adapitve_hash_index开启,也可以通过 —skip-innodb_adaptive_hash_index参数关闭
- InnoDB会监控对表上二级索引的查找,如果某二级索引被频繁的访问,则该索引数据会自动被生成到hash索引里面去,自适应哈希索引通过缓冲池的B+树构造而来,
- 缺点: 1. 会占用Innodb_buffer_pool,只适合搜索等值的查询,例如
select * from table where index_col='xxx',而对于其他查找类型,如范围查找是不能使用的
-
预读
- 线性预读
- 随机预读
-
-
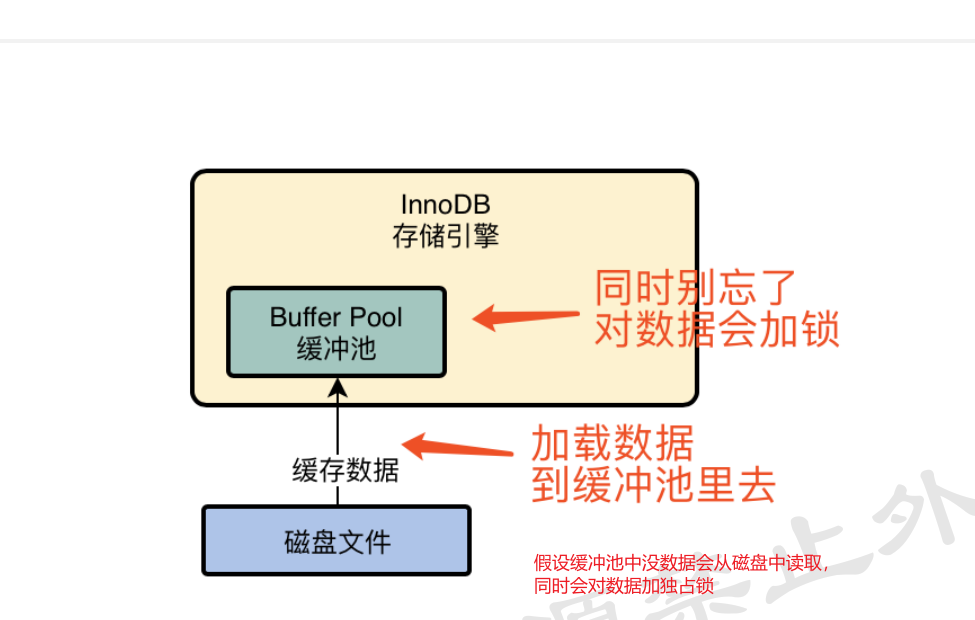
Innodb缓冲池(放在内存中的组件)
- Innodb引擎里面存在一个放在内存中的组件缓冲池,里面缓存很多数据,便于查询时,有数据从缓冲池中读取,否则去查磁盘(一个放在内存中缓存数据的组件)
- 操作过程:
-
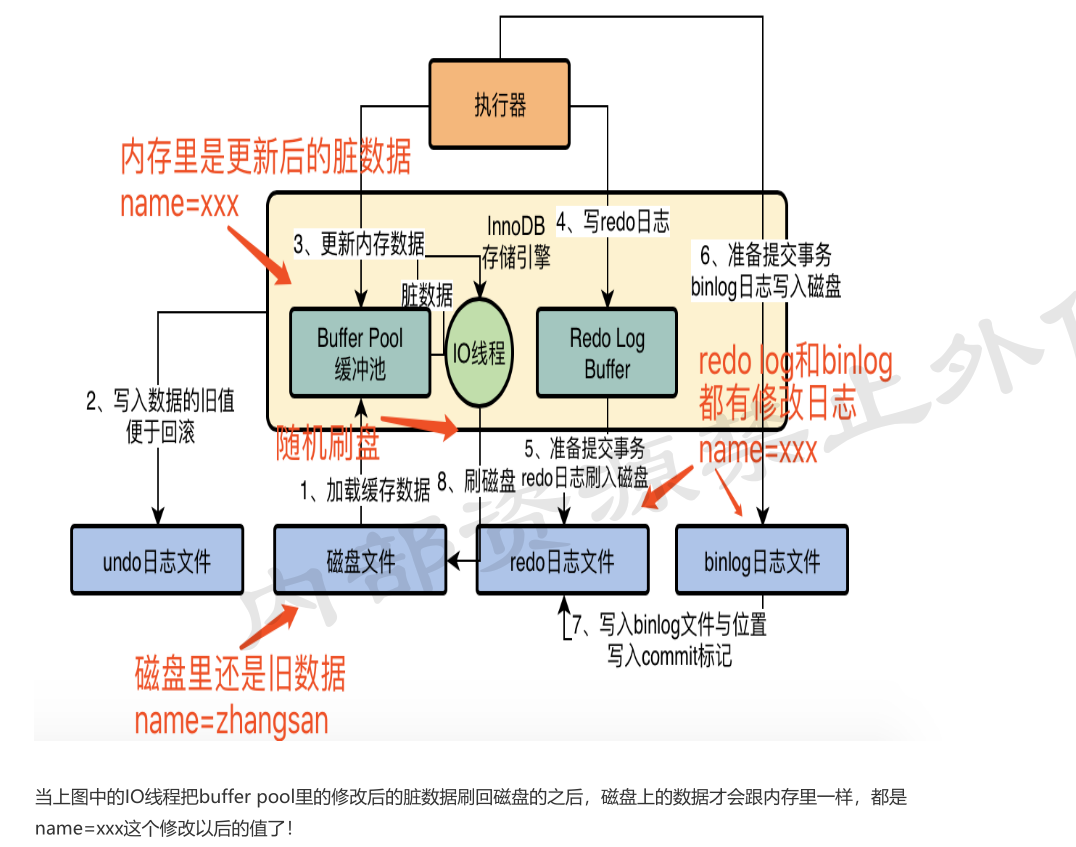
更新数据的操作流程(Innodb)
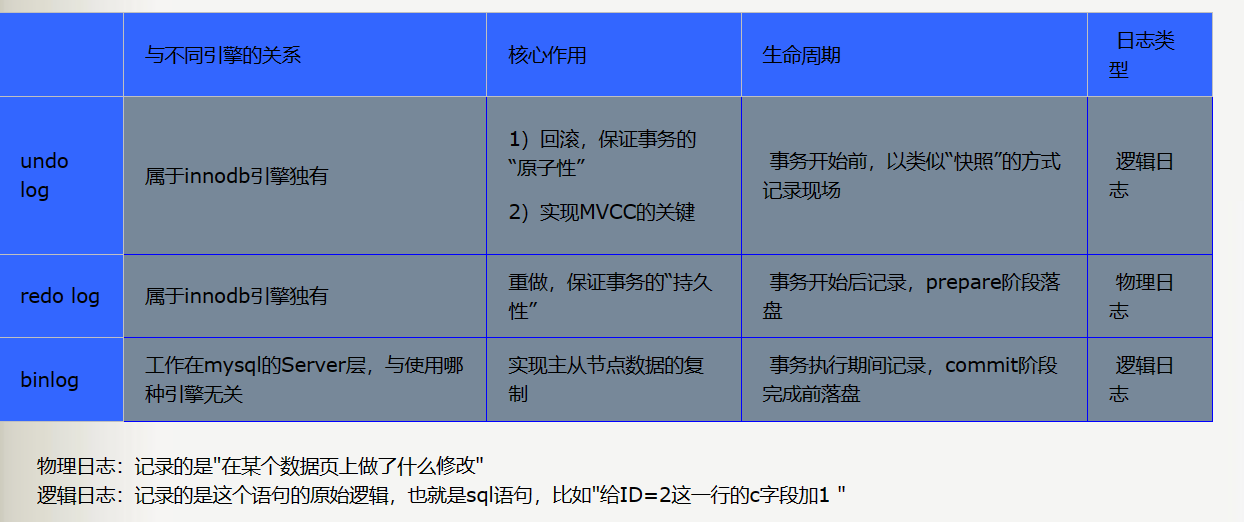
- mysql日志文件类型
- redo log(重做日志)
- 用于保持事务持久性
- undo log(回滚日志)
- 是事务原子性和隔离性实现的基础
- binlog (二进制日志)
- error log(错误日志)
- slow query log(慢查询日志)
- general log(一般查询日志)
- relay log(中继日志)
- 区别:
- redo log(重做日志)
- mysql日志文件类型
-
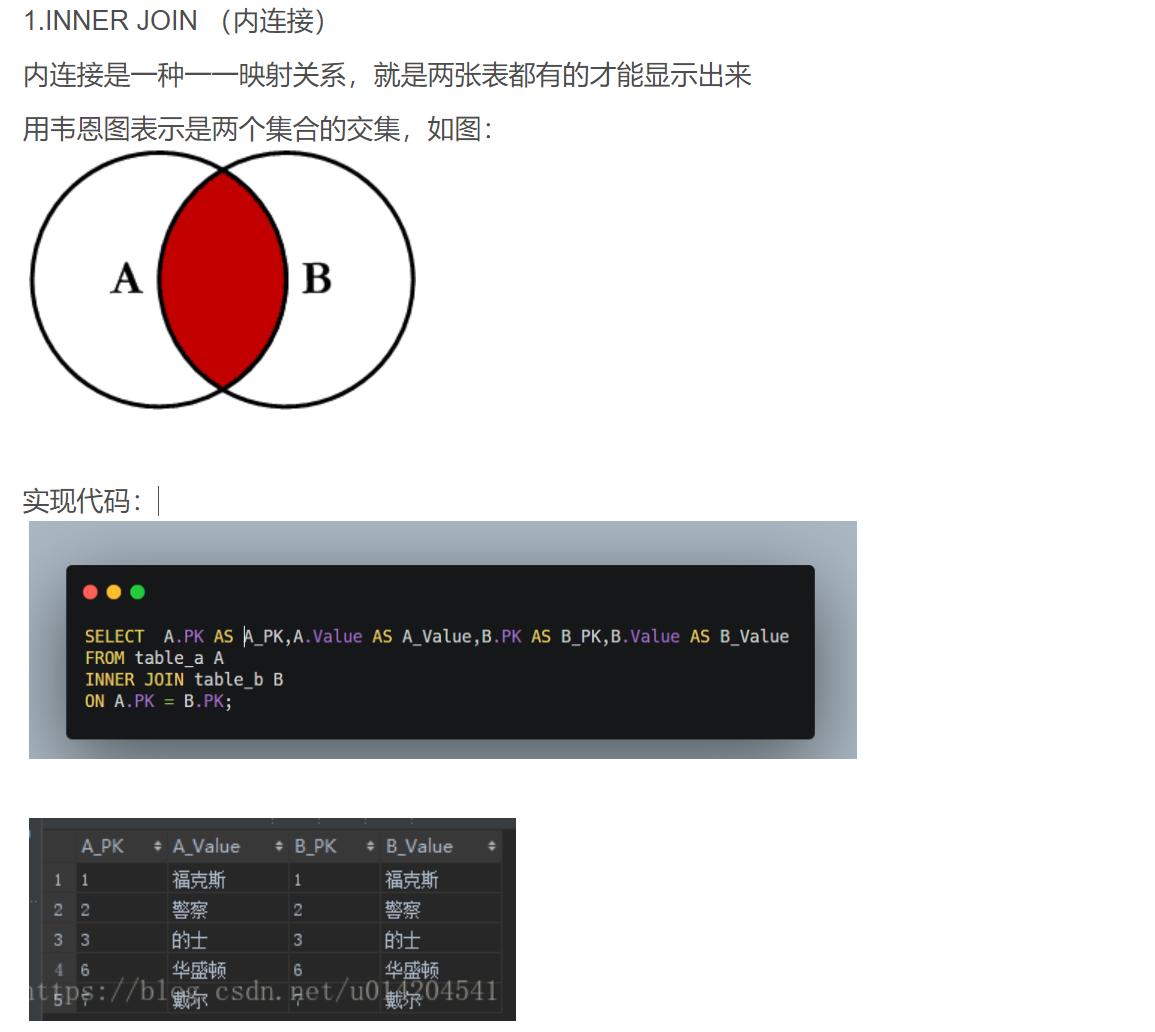
什么是内连接,外连接(左连接,右连接),全连接,外连接,笛卡尔积
- 内连接
- 左连接
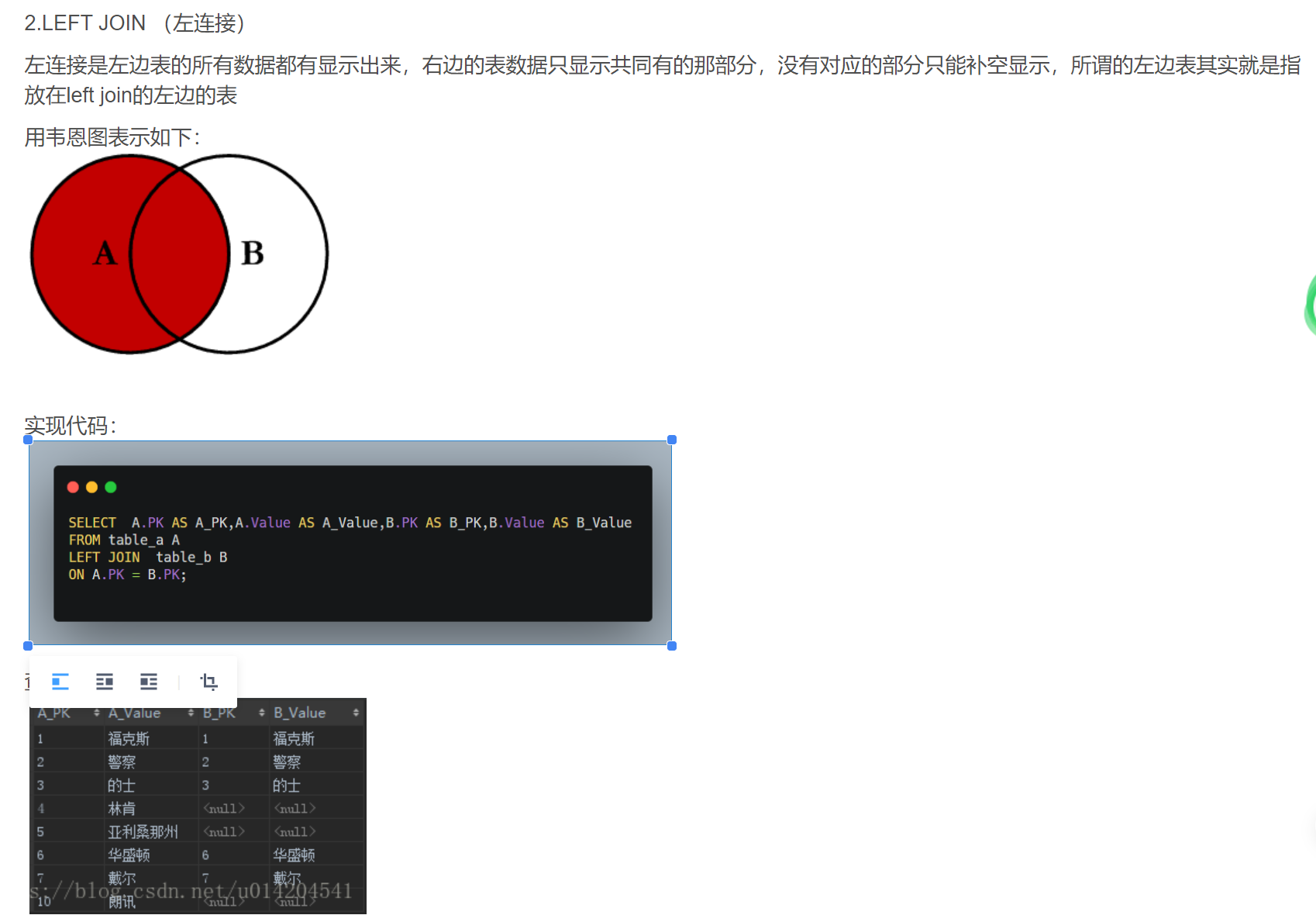
- 右连接
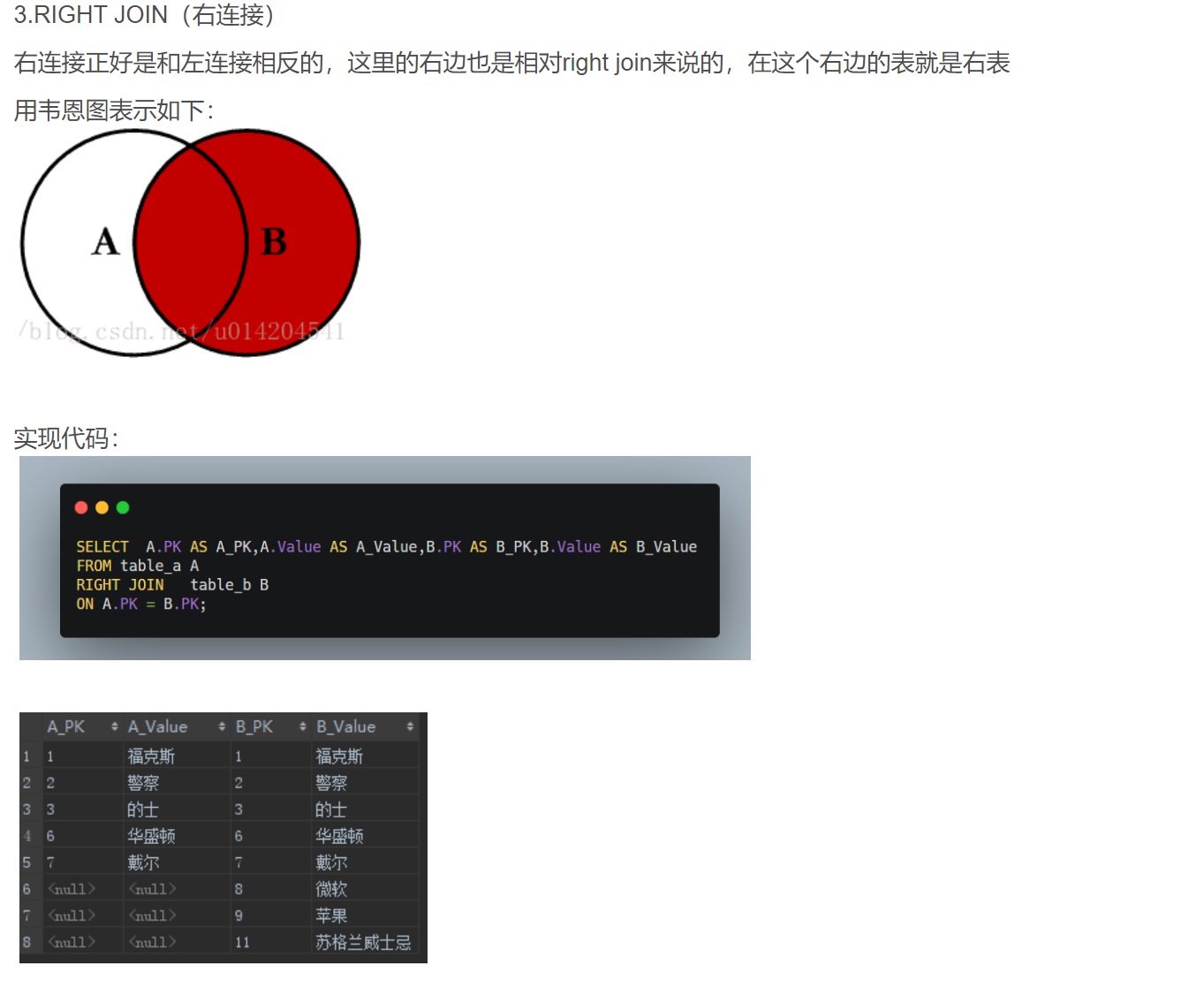
- 全连接,外连接
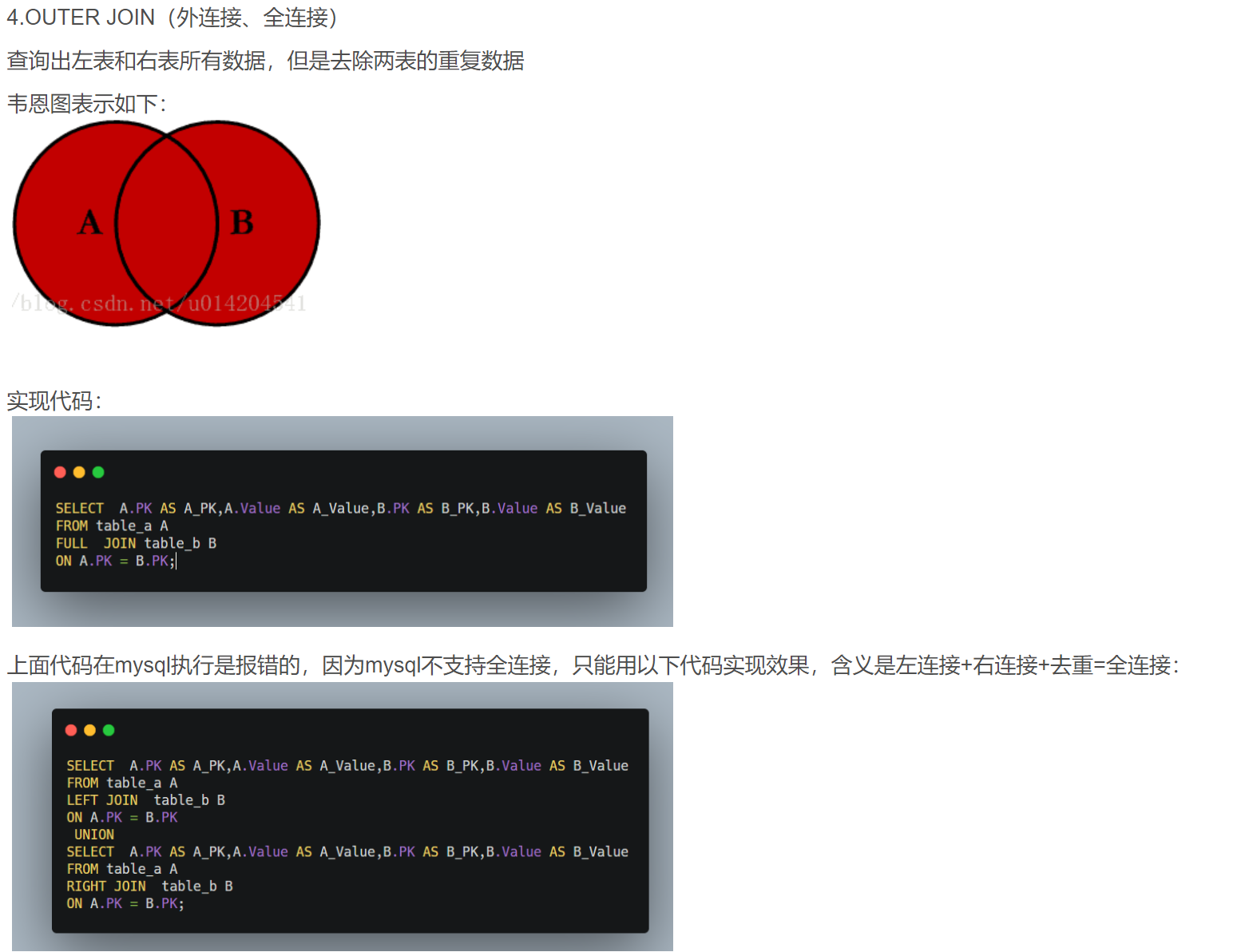
- 笛卡尔积
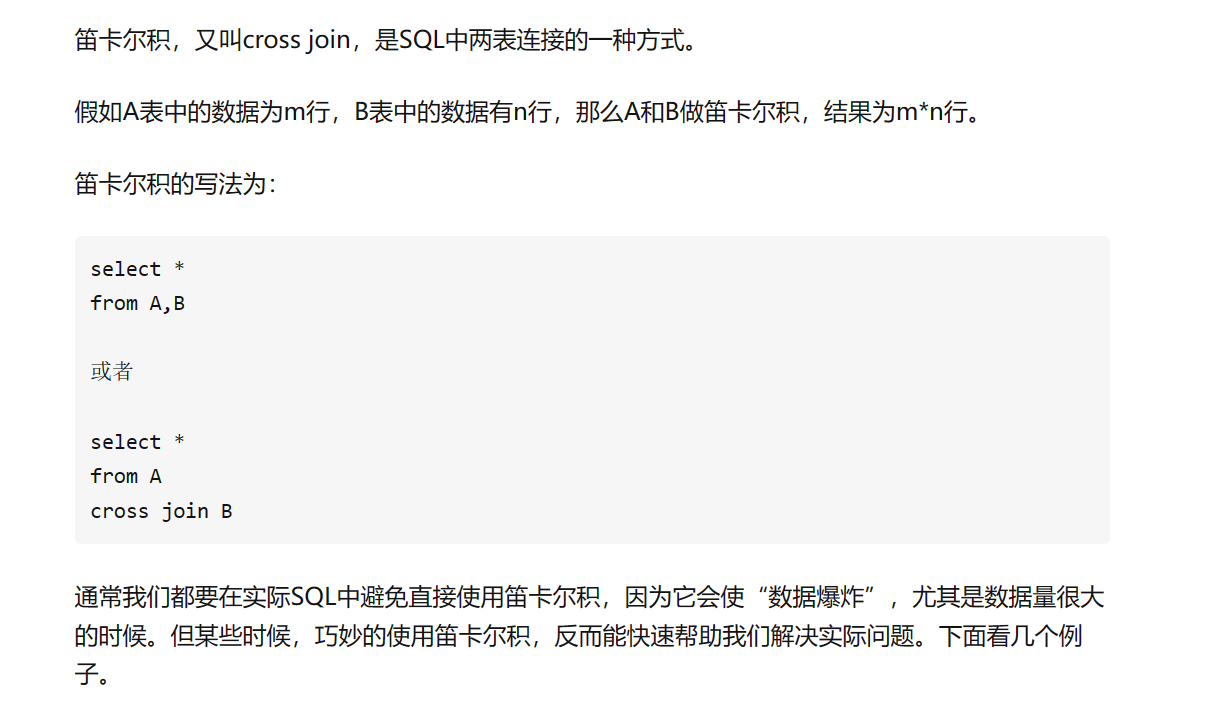
-
链接:
https://haicoder.net/note/mysql-interview/mysql-interview-mysql-normal-form.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号