

Pandas
一、安装
pip install pandas
二、系统环境
import pandas as pd
Series对象包装的是numpy中的一维数组,实际上是将一个一维数组与一个索引名称捆绑在一起了。
DataFrame 是 Pandas 中的一个表格型的数据结构,有行索引也有列索引。
三、Series:一维数组
用值列表生成 Series 时,Pandas 默认自动生成整数索引 。
pandas中两个重要的属性: values 和index
values:是Series对象的原始数据
index:对应了Series对象的索引对象
例:使用列表创建:
四、DataFrame对象创建
DataFrame 是 Pandas 中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame 即有行索引也
有列索引,可以被看做是由 Series 组成的字典。
将两个series对象作为dict的value传入,就可以创建一个DataFrame对象。
DataFrame创建:
例:
population_dict=
{'beijing':3000,'shanghai':1200,'guangzhou':1800}
area_dict=
{'beijing':300,'shanghai':180,'guangzhou':200}
import pandas as pd
population_series=pd.Series(population_dict)
area_series=pd.Series(area_dict)
citys=pd.DataFrame({'area':area_series,'population':population_series})
列表创建:
用字段形式创建
index 一般为索引 , columns一般为列名
Pandas中的Index,其实是不可变的一维数组
五、导入excel 文件
Pandas中的Index,其实是不可变的一维数组
使用Pandas模块操作Excel时候,需要安装openpyxl
pd.read_excel('stu_data.xlsx')
导入.xlsx文件时,指定导入哪个Sheet
导入.xlsx文件时,通过index_col指定行索引
导入.xlsx文件时,通过header指定列索引
导入.xlsx文件时,通过usecols指定导入列
导入csv文件时除了指明文件路径,还需要设置编码格式。
导入.csv文件,文件编码格式是gbk
导入.csv文件,指明分隔符
导入.txt文件用得方法时read_table(),read_table()是将利用分隔符分开的文件导入。DataFrame的通用函数。它不仅仅可以导入.txt
文件,还可以导入.csv文件。
导入.txt文件
导入.csv文件,指明分隔符
六、了解数据
head()与 tail():
#浏览前几条记录info():info()可以输出整个表中所有列的数据类型。
df.info()
shape()方法会以元组的形式返回行、列数。注意 shape 方法获取行数和列数时不会把索引和列索引计算在内。
修改变量列:
columns
df.columns =新的名称 list
df.columns
rename()
df.rename(columns =新旧名称字典:{旧名称,:新名称},
inplace = False :是否直接替换原数据框)
df.rename(columns ={'newname':'name','newname2':'name2'},
删除变量列:
df.drop(index / columns =准备删除的行/列标签,多个时用列表形式提供
inplace = False :是否直接更改原数据框 )
添加变量列
根据新数据添加
df[cloumn] = pd.Series([val,val2,val3],index=[c1,c2,c3])
根据原数据添加
df[cloumn] = df[c2]+df[c3]
七、变量类型的转换
df.dtypes :査看各列的数据类型
#将df里所有的列转换成str八、引用和修改索引
引用索引:索引仍然是有存储格式的,注意区分数值型和字符型的引用方式
df.index
修改索引:
修改索引名:
例:df = pd.DataFrame({ 'name':['zs','ls','ww'],'level':['vip1','vip2','pm']})
修改索引值:df1.index = ['a', 'b', 'c']
更新索引:
reindex 则可以使用数据框中不存在的数值建立索引,并据此扩充新索引值对应的索引行/列,同时进行缺失值填充操作。
df.reindex(
labels :类数组结构的数值,将按此数值重建索引,非必需
copy = True :建立新对象而不是直接更改原 df/series 缺失数据的处理方式
例:import pandas as pd
df = pd.DataFrame({'name':['zs','ls','ww'],'level':['vip1','vip2','pm'] })
df.reindex([0,1,3])
df.reindex([0,1,2,3],method='ffill')
df.reindex([0,1,2,3],fill_value="test")
九、Series的索引和切片
loc函数:通过行索引 "Index" 中的具体值来取行数据及根据普通索引获取。(如取"Index"为"A"的行)
iloc函数:通过行号来取行数据,及根据位置索引获取。
十、DataFrame的索引和切片
选择列:
当想要获取 df 中某列数据时,只需要在 df 后面的方括号中指明要选择的列即可。
如果是一列,则只需要传入一个列名;如果是同时选择多列,则传入多个列名即可(注意:多个列名 用一个 list 存放)
例:#获取一列
df[col]
#获取多列
df[[col1 , col2]]
按行列索引选择:df.loc[普通行索引,普通列索引]
df.iloc[位置行索引,位置列索引]
loc与iloc获取: import numpy as npimport pandas as pd
data=pd.DataFrame(np.arange(12).reshape(3,4),index=list('abc'),columns=list('ABCD'))
#获取行为'b'的行
data.loc['b']
#使用iloc获取,行为'b'的行,行号为1
data.iloc[1]
获取'A'列所有行: data.loc[:,'A']
data.iloc[:,0]
获取部分行部分列: #获取a bc行,A B列
data.loc[['a','b','c'],['A','B']]
data.iloc[[0,1,2],[0,1]]
获取满足条件的行: df[df[“支出”]>10]
df[(df[“支出”]>10) & (df[“性别”]=='女')]
isin()选择:
df.isin(values) 返回结果为相应的位置是否匹配给出的 values
values 为序列:对应每个具体值
values 为字典:对应各个变量名称
values 为数据框:同时对应数值和变量名称
df.col.isin([1,3,5])
df[ df.col.isin([1,3,5])]
df[ df.col.isin(['val1','val2'])]
df[ df.index.isin(['val1','val2'])]
query()的使用:
使用boolean值表达式进行筛选
df.query(
expr:语句表达式
inplace=False;是否直接替换原数据框
)
十一、排序
用索引排序
df.sort_index(
使用变量值排序
df.sort_values(by='身高')
十二、计算新变量
axis = 0 :针对行还是列逬行计算0 ' index':针对每列进行计算
1' columns ':针对每行逬行计算
在指定位置插入新变量列
df.insert(
loc :插入位置的索引值,0 <= loc <= len (columns)
column :插入的新列名称
value : Series 或者类数组结构的变量值
allow_duplicates = False :是否允许新列重名
)#该方法会直接修改原 df
例: # 指定位置增加新列
十三、数据分组
dfg = df.groupby ('开设')
分组汇总
使用df.agg()函数进行汇总
可以直接使用的汇总函数
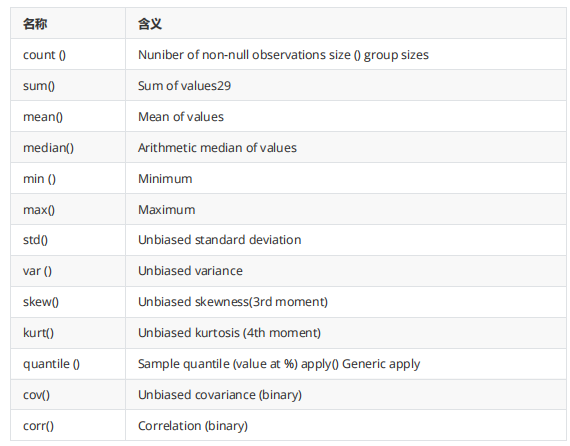
十四、引用自定义函数
# 使用自定义函数


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通