
占顺杨---第一次个人编程作业
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | 回顾数据采集与基本预处理,学习词云图 |
| 作业源代码 | https://github.com/zsygithub123/first-personal-work |
| 学号 | 211806193 |
| 模块 | 时间 |
|---|---|
| 数据采集 | 3h |
| 数据处理 | 6h |
| 可视化(词云图) | ∞ |
| git管理 | 3h |
| 项目 | |
|---|---|
| 代码行数 | 89 |
| 需求分析时间 | 2h |
| 编码时间) | 3h |
1.记录自己的代码行数,需求分析时间,编码时间。
代码是用python编写的,代码总行数89行;看到题目后发现题目中要用到的知识有一部分是已经学过的,同时也有一部地方是新的知识,要自己查阅相关资料;作业是多次完成的,所以时间比较零散。
2.分解需求的思路,分解成多个模块,并阐述为什么这么分,优势在哪,可以附上代码片段。
1.打开腾讯视频并搜索《在一起》,在后面可以看到相关的评论,点击以后就跳到了一个网址为https://coral.qq.com/5963120294的网页,在网页的下面就是《在一起》的评论,即为我们要获取的评论,下一步就是要将所有的评论采集下来并且保存到本地。将右侧的滑条拉到最下面发现在其底部有一个这样的  按钮,点击以后可以显示另外的评论,可以点击很多次,这种结构的网页可以用selenium来模拟人来点击,但是我点击了许久发现有很多,说明有很多页评论(在后面得到了证实),由于要获取所有的,所以用selenium的效率比较低。为了提高效率,后来就对网页进行分析,准备总网址这里来打开突破口。
按钮,点击以后可以显示另外的评论,可以点击很多次,这种结构的网页可以用selenium来模拟人来点击,但是我点击了许久发现有很多,说明有很多页评论(在后面得到了证实),由于要获取所有的,所以用selenium的效率比较低。为了提高效率,后来就对网页进行分析,准备总网址这里来打开突破口。
2.按F12后发现第一,二,三页的网址分别为 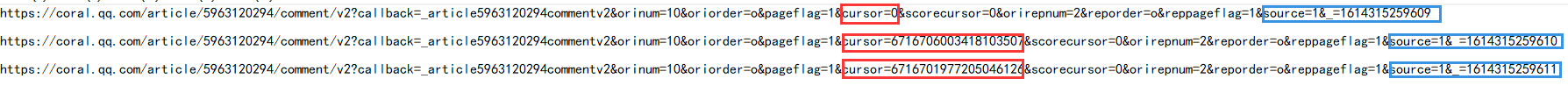
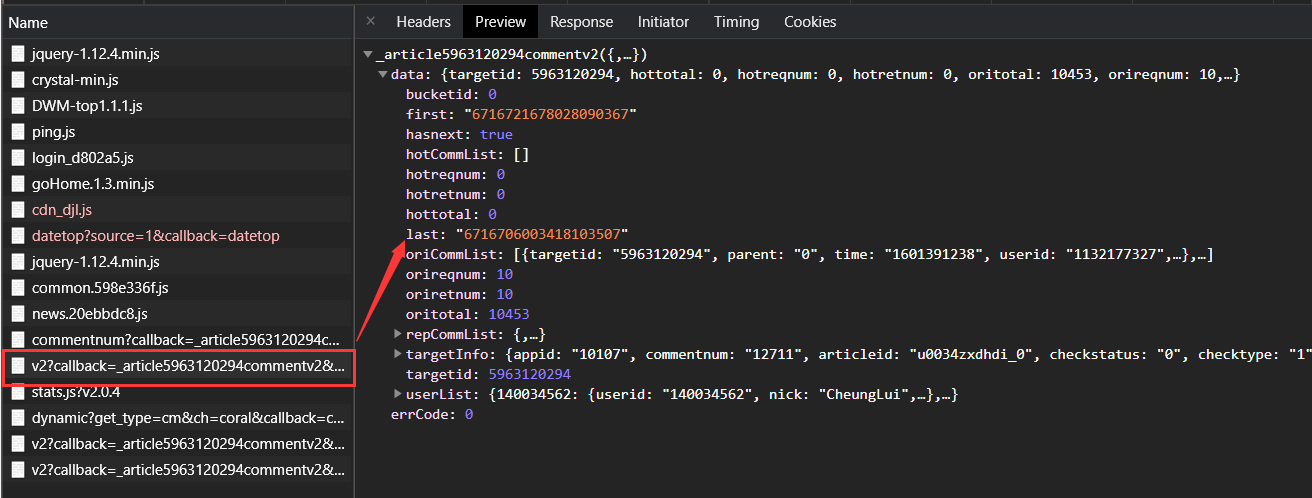
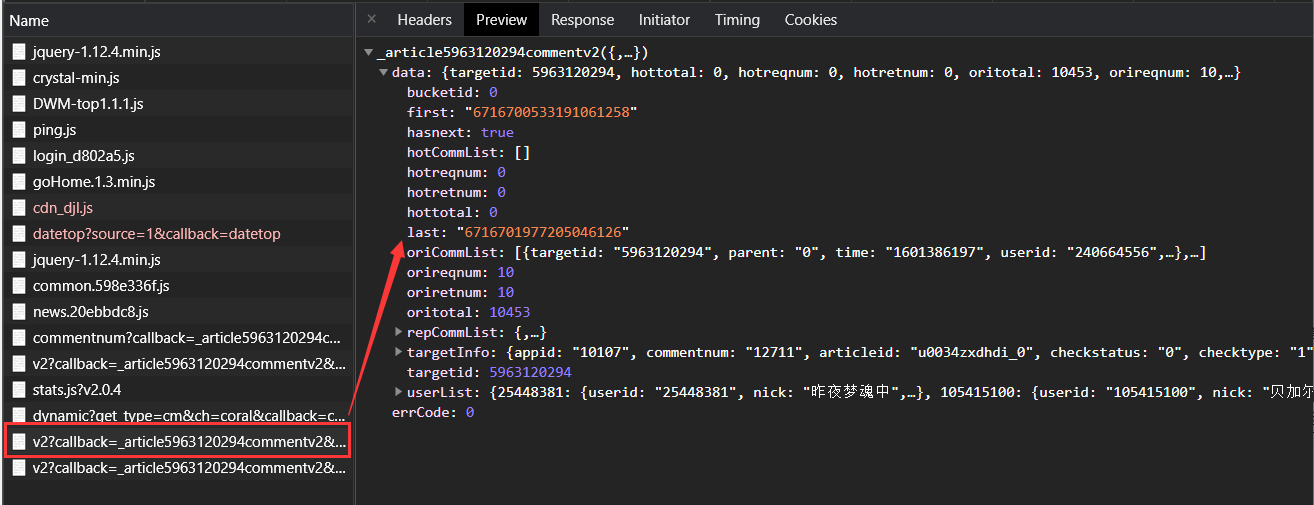
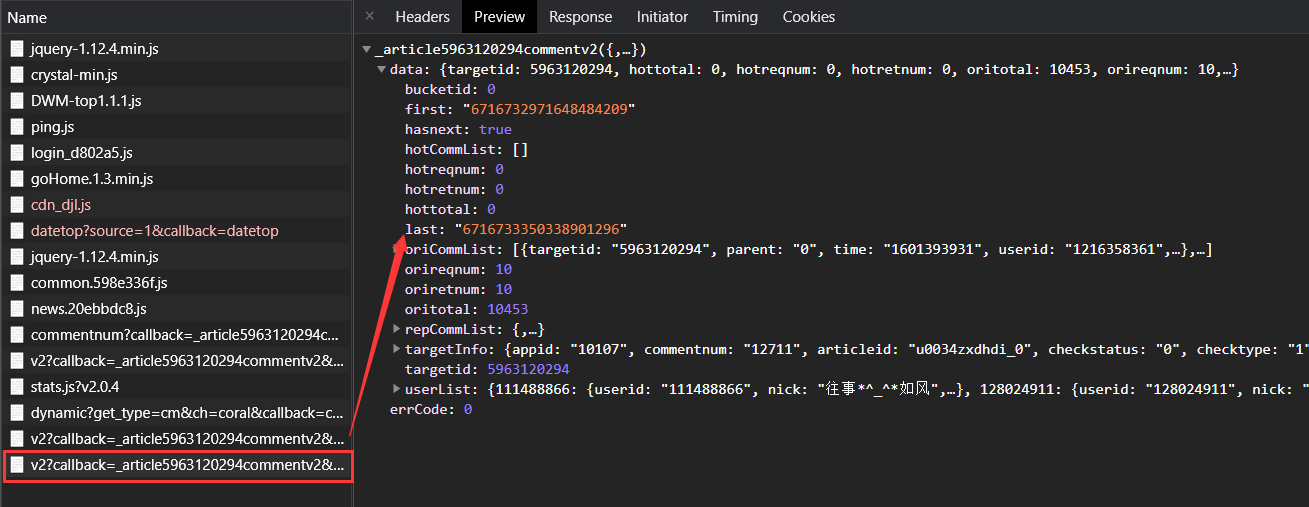 ,通过比较分析发现,网址中只有两个地方不一样,即cursor和source,除第一页外,其他的前一页的last即为后一页的cursor,第一页的source为1614315259609,后面的每一页在此基础上+1.找到了url的规律,现在就可以来拼接url从而获取每一页的源码。
,通过比较分析发现,网址中只有两个地方不一样,即cursor和source,除第一页外,其他的前一页的last即为后一页的cursor,第一页的source为1614315259609,后面的每一页在此基础上+1.找到了url的规律,现在就可以来拼接url从而获取每一页的源码。
3.每一页的源码是json格式,将其转换为字典格式,然后通过键值对的方式来获取需要的信息(last的值,content的值),last用来拼接下一页的网址(zyq_dact["data"]["last"]),content的值就是每个用户的评论(zyq_dact["data"]["oriCommList"][i]["content"])。这样就完成了所有评论的获取,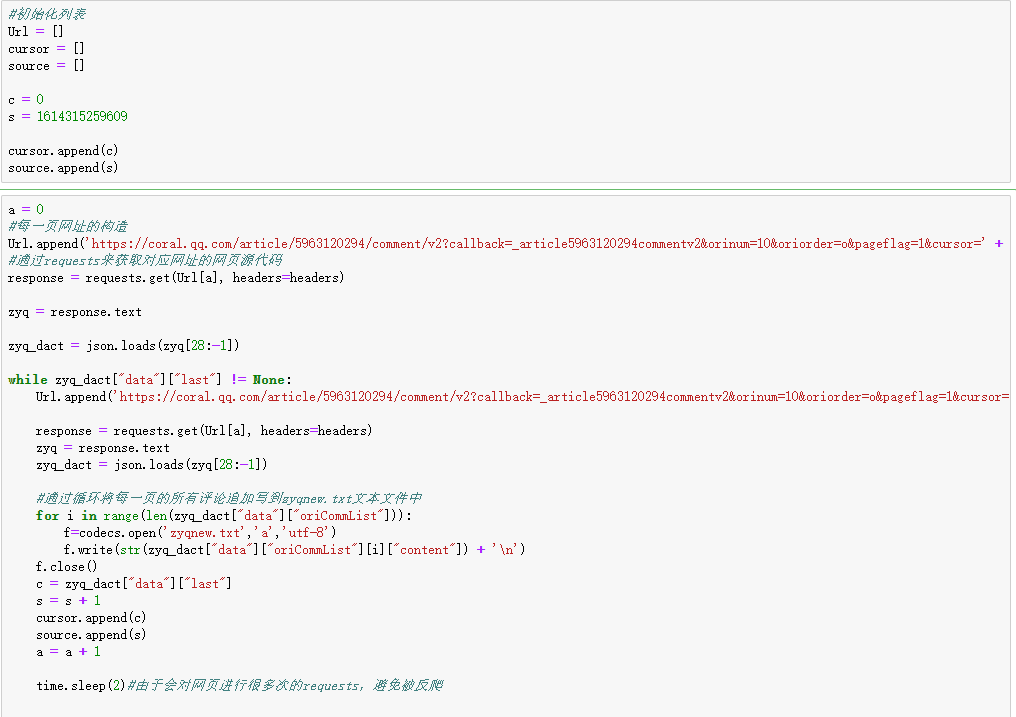 。
。
3.记录不会的知识的学习过程、记录修改优化的过程
4.jieba中文分词,由于这是新的知识,通过视频进行了粗略的学习,能够使用代码将刚刚获取的所有评论进行处理  。
。
5.WordCloud词云图,通过视频进行了学习,在开始的时候没有使用font_path(字体路径)这个参数,制作出来的词云图无法显示中文,后来加上font_path = 'C:\Windows\Fonts\STFANGSO.TTF'就可以显示中文。
