mysql小结——基础篇
如有需求,也可查看如下小结:mysql小结——忘记密码、修改密码
首先记住三个概念:
1.数据库(Database)是按照数据结构来组织、存储和管理数据的建立在计算机存储设备上的仓库。
2.SQL :结构化查询语言(Structured Query Language)
3.MySQL:关系型数据库管理系统
database中存储着各种数据,sql语句用于从database中找出我们需要的数据,mysql是一种应用软件,通过语句对database进行操作。
MySQL我使用的是5.6版本,通过管理员身份打开cmd后,启用mysql服务为:net start mysql56,关闭服务为:net stop mysql56。登录:mysql -h localhost -u root -p 回车后输入密码:123456(用户名和密码在安装时进行设置)
本篇小结有如下几点:
->数据类型,约束,字段属性
->索引,对数据操作(insert,update,replace,delete),对表操作(alter)
->联合查询(cross/inner/left/right join ,union),不重复(distinct),取别名(alias),偏移量(limit),子查询,模糊查询,排序查询
4.函数
->avg,count,max,min,sum
->ucase,lcase,mid,round,日期
数据定义语言(DDL):
英文原名:数据库模式定义语言DDL(Data Definition Language),是用于描述数据库中要存储的现实世界实体的语言。
就如同字面意义,这些语言就是与对数据进行定义相关的。
与其有关的有:
1.数据类型(常用):
整型:tinyint,smallint,int;
浮点型:float,double,decimal(M,N);
字符型:char,varchar;
日期类型:date,time,year,month,day等
ps:每个类型都有自己默认的范围(默认占用的字节空间,也就代表了所能接收的最大值),同时也可以在定义时指定占用大小。比如 id int(6)
ps2:更详细的数据类型信息可以通过 菜鸟教程 的介绍了解 http://www.runoob.com/mysql/mysql-data-types.html
ps3:decimal(M,N): M最多取65,D最多取30。在建表时使用decimal,可写成 price decimal(6,2) ,6表示字段的总长度,2表示小数的长度。例如 5555.12
ps4:varchar 必须指定长度,即类似 name varchar(10),因为varchar默认大小是1个字节
ps5:存出生日期时常用date类型,但是要计算多少岁时需要用year,year无法直接从date中取出来,这时候就可以利用 date_format() 方法
2.约束:
primary key(主键):约束唯一标识数据库表中的每条记录
foreign key(外键):foreign key就是表与表之间的某种约定的关系,从一个表指向另一个表
unique:约束用于限制加入表的数据的类型
主键:
主键是需要我们选取一个字段(定义的id、name之类的)作为这张表中,每一行(每一条数据)的标识,主键是唯一的。就如同我们的身份证,姓名、年龄、出生地等全部可以相同,但是身份证号是唯一的。主键虽然可以不定义,但是理论上每张表都应该有一个主键。
主键的特点:唯一、非空、不自增。并且一般情况下都用于id(int型数据)
唯一:一个字段中(也就是一列数据里),一个值只能出现一次
非空:通俗来讲是指 在插入数据时 能不能不进行赋值
自增/不自增:(用于整型,即tinyint,int等)在插入数据时,如果不进行赋值,会自动赋值比当前表中该字段最大的值大1的数(没有的话会从1开始)。
主键的两种定义: create table test( id int primary key, name varchar(10) ); create table test( id int, name varchar(10), primary key(id) ); 给主键命名:利用 constraint create table test( id int, name varchar(10), constraint isKey primary key(id) ); 以及建表时未定义,在后来添加主键: alter table test add primary key(id); 删除主键: alter table test drop primary key;
unique:primary key=unique + not null
unique用于给一个字段添加 "唯一" 约束,同样是一个字段里一个值只能出现一次。
unique的特点:唯一
用法:与主键相同,只需将primary key 换成 unique即可
创建:
1.create table test(id int unique;
2.create table test(id int,unique(id));后期加入约束:alter table test add unique(id); ————同时属于唯一约束
撤销约束:alter table test drop index id;
ps:如果写法为alter table test add unique(id,name);那么不能出现id和name同时相同的情况但是可以分开出现相同——id=001,name=张三 ,id=001,name=李四 可以同时出现
外键:foreign key 用于指向另一个表中的 primary key
作用:①为了一张表记录的数据不要太过冗余。②保持数据的一致性、完整性。
举个例子:比如学生信息中的学生id为主键,这时另一张学生的成绩表中,(成绩表)学生id可以作为 外键 指向 学生信息表中的学生id。
特点:在外键所在的表中插入数据时,外键所对应的主键必须要有相应的值才可以插入。例如:学生信息表中id为001,则在成绩表中stu_id也必须为001,不然插入失败。错误编号1022
创建学生表,id是主键 create table Student( id int primary key, name char(10) ); 创建成绩表,id是主键(与学生表中的id指的并不是一个意思) stu_id是学生id,在第四行代码中将其作为外键与学生表的主键相关联 //constraint i 是在给外键命名为 i ,这样便于删除外键 create table Score( id int primary key, stu_id int,name char(10), constraint i foreign key(stu_id) references Student(id) ); 以及建表时未定义,在后来添加外键: alter table Score add foregin key(stu_id) constraint i references Student(id); 删除外键约束格式: alter table 表名 drop foreign key 外键名 如果外键名未定义是有默认值,通过 show create table 表名 可以查看
3.字段属性
1.unsigned(无符号型),只能用在数值型字段————比如tinyint类型可以存储-128~127范围的数字,使用unsigned后,存储范围变成0~255.
2.zerofill(自动补零),只能用在数值型字段,前导零,同时该字段自动式UNSIGNED。————按照类型,自动向前填充0,例如插入时写的是 12,实际存进去的是 0000000012
3.AUTO_INCREMENT(自动增长),也就是之前写的 自增/非自增。————通常情况下只在主键上,顺序只能是 id int auto_increment primary key
4.NOT NULL:强制约束列不守NULL值,即不添加数值就无法插入数据,也就是之前写的 非空
5.缺省值(default):给数据一个默认值(系统默认值是NULL),不能与auto_increment同时用于一个字段上
ps:写法均为:create table test(id int 字段属性);
DML(数据操作语言):
0.建表/删表
create table test( id int primary key, name varchar(10) );
drop table test;
1.索引:
现在只了解了怎么使用以及简单原理,以后再进行深入了解。
这里引用一下 WorthWaitingFor的文章,帮助自己理解了索引:
MySQL索引原理以及查询优化
简单地说:
假设数据库内容是一本字典,索引就如同这本字典的拼音表。有拼音表的字典,我们可以通过查拼音找这个字直接翻到对应页数。不然我们只能一页一页的翻字典对比这个字的读音进行对比。
但是!如果有拼音表的字典,我们只知道偏旁部首而不知道拼音,同样只能一页一页翻。也就是如果我们给 id 创建了索引,但我们 select 时 where 条件是 name='xxx',同样不能加速查询。
Q:什么时候使用索引?
A:数据量大(一般10W以上),查询频繁
Q:什么字段适合作为索引?
A:不会频繁更新的字段,会经常出现在where子句中的字段,占用空间少的字段(如整型)
Q:索引有哪些类型?
A:
1.普通索引index :加速查找
2.唯一索引
主键索引:primary key :加速查找+约束(不为空且唯一)
唯一索引:unique:加速查找+约束 (唯一)
3.联合索引
-primary key(id,name):联合主键索引
-unique(id,name):联合唯一索引
-index(id,name):联合普通索引
4.全文索引fulltext :用于搜索很长一篇文章的时候,效果最好。
5.空间索引spatial :了解就好,几乎不用
创建:create index 索引名 on 表名(字段); create index i on test(id); 删除:drop index 索引名; drop index i;
2.对数据操作:
insert(插入):
插入单独数据:insert into 表名 字段1、字段2... values(值1、值2...);
插入默认数据:insert inro 表名 values(值1、值2...);
单条插入 insert into test(id,name) values(008,'周星星'); 多条插入,用逗号隔开即可 insert into test values(001,'星爷'),(002,'9527'); ps:非数字类型的值需要用单引号括起来,时间类型比较特殊,比如date型需要写成"2018-7-30"
update(修改、更新):修改(更新)数据:update 表名 set 字段=新值 where 列名称=某值
更新一条数据 update test set name='詹姆斯' where id=008; 修改多条数据: update test set name=case id when 001 then 'qwe' when 002 then 'asd' end where id in(001,002);
replace(批量更新数据)(也可用于数据添加):replace into 表名(字段1、字段2...) values(值1、值2...)
replace的本质是对应primary key,
有:将此条数据删除,输入更改的数值,且默认为null
无:添加数据。 删除主键后用replace便会所有操作都是添加数据而不存在修改数据
replace into test(id,name) values(002,'777'); 未添加的数据会默认为null
批量更新(通过update):可以用于“删除”一行内容中一个字段的值
同样是通过对应primary key进行修改,无法更改primary key对应的数据
insert into test(id,name) values(001,'i am 001'),(002,'i am 002') on duplicate key update id=values(id),name=values(name);
ps:假设代码写成 value(001,'null'),那就会等同于删除这个值。删除的本质就是修改人类的本质就是复读机!
delete删除数据(一条):delete from 表名 where 条件
delete from test where id=001;
3.对表操作——alter
[ ]之中的内容表示 可添加。
修改表名:alter table 旧表名 rename as 新表名;
alter table test rename as father;
修改字段的数据类型:alter table 表名 modify 字段名 数据类型 [first/after];
只进行修改 alter table test modify id char(10); 修改后改变顺序 first:第一位 after 字段名2:将字段名1放在字段名2之后 alter table test modify id char(10) after name;
会将id字段放在name字段后面 也就是查询后会显示成 name id 不会对主键进行影响
修改字段名:alter table 表名 change 字段名 新字段名 数据类型;
alter table test change name address char(50);
如果建表时没有主键,可以在最后加上primary key将其设置为主键 非空、缺省等字段属性同理 字段同时有了auto_increment和primary key时,若想删除primary key,需要先通过change取消auto_increment,再删除primary key (复习一下,只有主键时,删除主键是:alter table test drop primary key ————主键也是一个索引) 原理:通过改变名字、数据类型,会取消auto
增加字段:alter table 表名 add 字段名1 数据类型 [完整性约束条件][first/after];
alter table test add address char(30); 完整性约束条件是指是否添加 外键 和 unique (复习一下:之前写的添加外键: alter table Score add foregin key(stu_id) constraint i references Student(id); )
删除字段:alter table 表名 drop 字段名;
alter table test drop address;
*DQL(数据查询语句select): select * from 表名
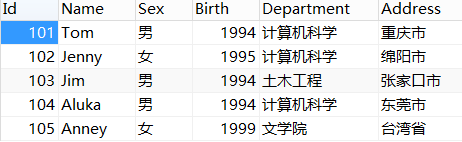
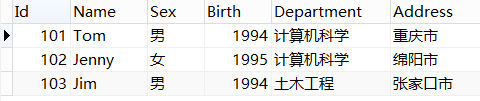
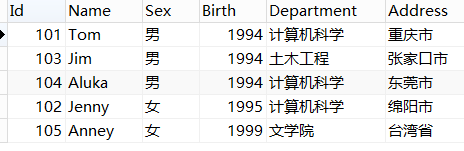
图1:student
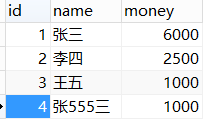
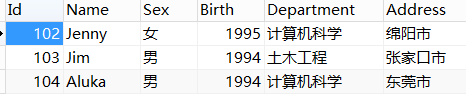
图2:student2
1.交叉查询:select 表1.字段,表2.字段 from 表1,表2;
或 select * from 表1 cross join 表2;
这里会有两种情况: 1.两张表拥有相同的字段: 需要写成 表名.字段 进行区分: SELECT student.name,student2.name FROM student,student2; 2.两张表各自独有的字段: 直接写字段名即可: SELECT Address,money FROM student,student2;
结果(没截全):
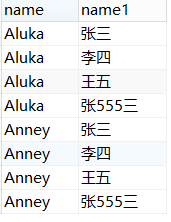
会根据 写在前面的那张表的字段的值,与后面张表的字段的每一个值都对应显示,显示结果总共是 m*n个(笛卡尔积)。
多表联合查询:select 表1.字段,表2.字段 from 表1,表2 where 表1.id=表2.id;
select * from student,student2 where student.id=student2.id;
显示出来的将会是两边id对应相等的值
这里是空值,因为我两张表的id并没有对等。

join连接查询:select 字段 from 表1 inner/left/right join 表2 on 表1.字段=表2.字段;
inner jor(内连接):类似于与直接查询,差别只在于条件子句 直接查询用where,join连接用on
select * from student,student2 where student.id=student2.id; 等同于select * from student INNER JOIN student2 on student.Id = student2.id;
如果没有符合条件的结果,查询结果为空
如果三个(或更多个)表相连:select * from 表1 inner join 表2 on 表1.字段=表2.字段 join 表3 on 表1.字段=表3.字段;
left join(左连接):select * from student LEFT JOIN student2 on student.Id = student2.id;
没有值是因为id不同,但是 会有查询结果,即左边的表显示
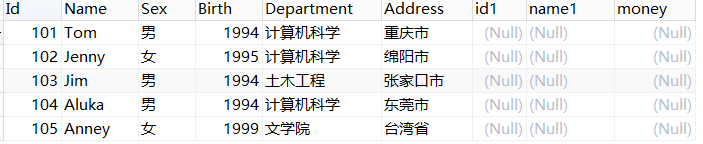
right join(右连接):同左连接,会将右边的表显示
full join(全连接)(mysql不支持全连接)
union(联合查询):select *from 表1 union select *from 表2;
ps:表的格式必须相似(指的是int与tinyint这种可以相似,别的必须相同),因为他们 联合 出来的是向下的数据,并不会显示在同一水平面
ps2:union默认选取不同的值,如果想显示相同值就写成union all
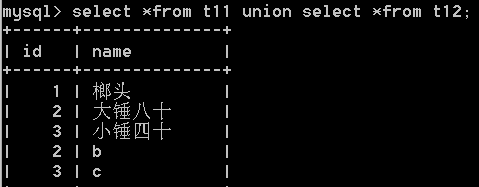
2.查询不重复的数据:select distinct 字段 from 表名;
select distinct name from test; 用于查询非唯一的字段,毕竟他们可能有重复的数据,这个时候就可以通过distinct关键字进行不显示重复字段查询
3.取别名alias(常用于自连接):select * from 表名 as 别名;
select b.* from student as a,student as b where a.name='Aluka' and a.id > b.id; 此处先将student表取别名为 a 和 b ,然后给条件:找到 name 为 'Aluka'的人,再找到'Aluka'的 id 所大于 其他人id的人————也就是所有比'Aluka' id要小的人的所有信息 实际操作也就是可以用于,我知道一个人是谁,但是我不知道他的id是多少,同时我以他作为标准,所有成绩在他之下的人,都不算合格。这种类似的情况。 如果用子查询,可以获得相同的结果(注意这里用的是 < ): SELECT * from student where student.Id < (SELECT Id FROM student where name='Aluka');
4.limit(偏移量):
查询前n条数据:select *from 表名 limit n;
查询前n条数据后的i条数据:select *from 表名 limit n,i;
select * from student LIMIT 1,3; 注意:计算机的计算大多是从0开始的,所以1指的是第二条
5.子查询:select 字段 from 表名 where 字段 in/some/all/any( select ...... ); 配合 = , < , > , >= , <= , != 使用。
注意: in 的后面可以直接加上数据,比如 select * from student where id in (1,2,3);
但是剩余的关键字需要严格使用子查询:select * from student where id = any(select * from student where id > 1 ); 这种格式
IN:查询的结果,在in后面的值之中
select * from student2 where id in (1,2,3);
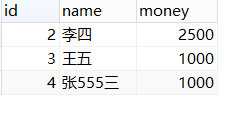
select * from student2 where id in (SELECT id from student2 where id>1);
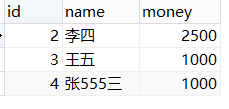
SOME/ANY:some的作用和any相同。都是只要符合其中一个的条件就行(和or也类似)(也就是 || (java))
select * from student2 where id >= ANY(SELECT id from student2 where id>1); 此处结果集为{2,3,4},此时只需从 >=2 的结果开始就行 select * from student2 where id > ANY(SELECT id from student2 where id>1); 此时虽然结果集同样是{2,3,4}但是选取的是需要 >2 所以查出来的结果是从 3开始
结果1: 结果2: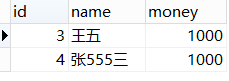
ALL:必须满足条件里的所有值(也可简单的认为是最大值)(也就是 && (java))
select * from student2 where id >= ALL(SELECT id from student2 where id>1); 结果集同样是{2,3,4},但选取的结果就不同了,必须 >= 4
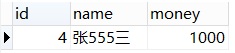
6.like(用于where子句中搜索列中的指定模式):select 字段 from 表名 where 字段 like 表达式;
也就是模糊查询
%:表示0~多个字符
_:表示一个字符
经常有这些用法: 1.姓王的人: 王% 2.姓名是王某的人:王_ 3.名字里带王的人:%王% SELECT * from student where name like 'J%';
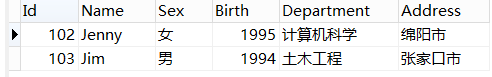
7.order by(排序):select 字段 from 表名 order by 字段(排序方式) [desc](使用倒序排列)
group by(分组排序):select 字段 from 表名 groupby 字段(排序方式) [desc](使用倒序排列)
排序: SELECT * from student ORDER BY Birth; 在末尾加 desc ,表示倒序(正序默认为从小到大)————复习:查询表的结构:desc 表名
分组排序: SELECT * from student GROUP BY Birth;
分组排序如果直接使用会使得 多个相同数据只显示排在最前的一个,所以 group by 经常与函数联合使用(count,avg等)
排序:![]() 分组排序:
分组排序:![]()
 分组排序:
分组排序: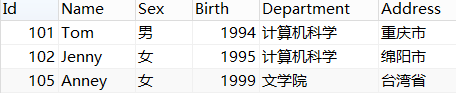
函数:
1.合集函数:操作面向一系列的值,并返回一个单一的值
写法都相同:
查询某列的平均值:select avg(字段) from 表名;
返回某列的行数:select count(字段) from 表名;
查询某列最大值:select max(字段) from 表名;
查询某列最小值:select min(字段) from 表名;
返回某列总和:select sum(字段) from 表名;
分组显示总和:select sum(字段) from 表名 group by 字段;
举几个可能用得上的例子:
查询一个id值,那个值在id中最大: SELECT MAX(Id) from student;
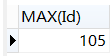
查询id中最大的那个人的所有信息: SELECT *,MAX(Id) from student;

查询比 平均生日-1的值 要大的人的所有信息: select * from student where birth > ((SELECT avg(Birth) from student)-1);

计算有多少个生日的值(这一列有多少值): select COUNT(birth) from student;

将生日的值进行分组,计算不同组有多少值,并且给COUNT(birth)取名为 总数 select Birth,COUNT(birth) '总数' from student GROUP BY Birth;
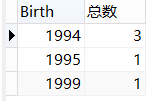
2.标量函数:操作面向某个单一的值,并返回基于输入值的一个单一的值
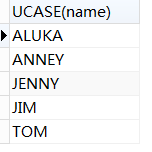
ucase(把字段的值转换为大写):select ucase(字段) from 表名;
lcase(把字段的值转换为小写):select lcase(字段) from 表名;
select UCASE(name) from student;
mid(提取字符):mid(字段,起始,结束):
select mid(name,2,3) from student;
左图是查询结果,右图是源结果。
作对比,此时并没有从0开始计数,写的起始值是几,就从第几个字符开始。同时结束字符是在结束值+1的字符结束
左: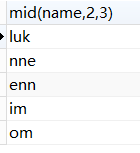 右:
右: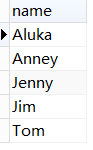
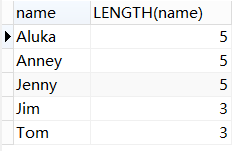
len(返回文本长度):select length(字段) from 表名;
select name,LENGTH(name) from student;
round(把数值四舍五入,并保留相应小数位):select round(字段,数字) from 表名;
表中加了一个float类型的num字段 如果不在后面写数字,默认为整数 select *,ROUND(num) from student;

数字写几,就保留几位小数 select *,ROUND(num,1) from student;

now()(查询当前时间):select now();
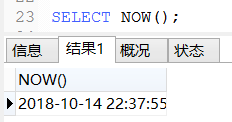
但是,同样与日期有关的还有date,year,day等等,在w3cschool中有详细介绍 http://www.w3school.com.cn/sql/sql_dates.asp
此处只举一个可能会用到的例子:
此时我添加了一个生日字段:
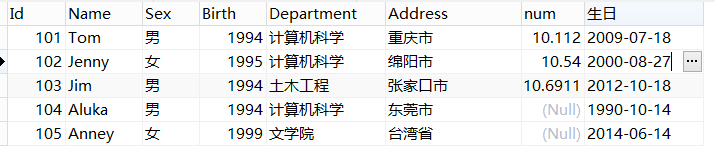
select * from student where (year(NOW())-DATE_FORMAT(生日,'%Y')) BETWEEN 10 AND 18; year(now()):获取当前年份, xxxx 格式 date_format():将 生日 字段的数据格式化输出,此处是获取 xxxx 格式的年份 整段代码的作用:查找年龄在10~18岁的人

基础知识总结完毕~,后面随着不断学习会不断整合、添加。
如果有不足之处或疑问,欢迎到留言区留言。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号