
python爬虫概述
爬虫的使用:爬虫用来对网络的数据信息进行爬取,通过URL的形式,将数据保存在数据库中并以文档形式或者报表形式进行展示。
爬虫可分为通用式爬虫或特定式爬虫,像我们经常用到的搜索引擎就属于通用式爬虫,如果针对某一特定主题或者新闻进行爬取,则属于特定式爬虫。
一般用到的第三方库有urllib、request、BeautifuiSoup。经常用到的框架为Scrapy和PySpider
爬虫的爬取步骤:
- 获取指定的url链接,获得链接网址上的所有代码信息。
- 通过python的正则表达式,将嵌套的HTML代码和数据进行分离。
- 获取数据后,保存在文档或者数据库中。方便后续的展示。
正常的网络传输大致分为Request(请求)和Response(响应)两类。
正常的HTTP请求一般分为get和post方法#
#使用urllib2编写最简单的爬虫代码
from urllib import request as urllib2
#在进行url请求时,应该添加User-Agent头进行识别
header = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Window
s NT 6.1; Trident/5.0;"}
request = urllib2.Request("http://www.baidu.com",headers=header )
response = urllib2.urlopen(request) html = response.read() print (html)
我们爬取的数据可分为结构化和非结构化两种
- 结构化数据:XML\JSON格式文件
- 非结构化数据:文本、图片、HTML文件
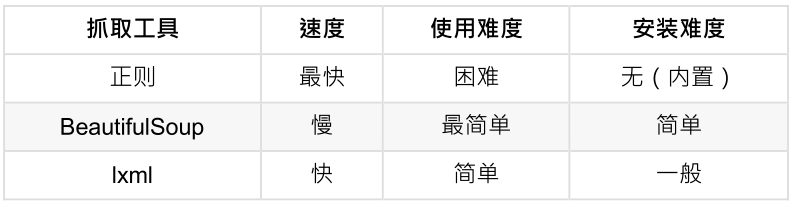
lxml VS BeautifulSoup
lxml为局部遍历,效率较高。而BeautifulSoup为全局遍历,基于HTML DOM的,性能较差。
#使用requests编写爬虫代码
import requests r = requests.get("http://www.baidu.com") print(r.status_code) #输出状态码 print(r.text) #输出返回文本 print(r.json) #输出json格式文件 print(r.url) #输出访问的url地址
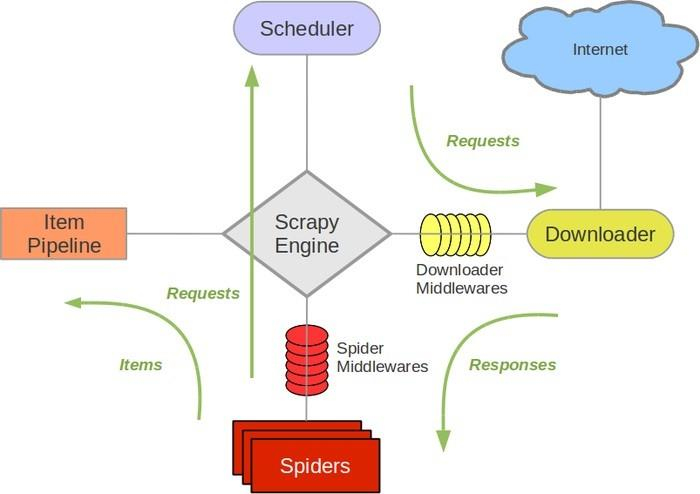
Scrapy架构图
Engine:负责其他组件的运转流程调度。
Scheduler:接收引擎发过来的request请求,并对其进行整理排列。当需要时返还。
Downloader:下载引擎所发送的Requests请求,并将获得的Response交给引擎,由Spider来处理。
Spider:负责从Response中提取Item中需要的数据,并将其他的URL提交给引擎,再转交给Scheduler。
Item PipeLine:负责处理Spider中的Item,并进行后期处理。
Downloader Middlewares:扩展下载功能组件
Spider Middlewares:扩展引擎和Spider通信的功能组件
Scrapy不支持分布式,Scrapy-redis提供了以redis为基础的组件
反爬虫策略:
- 动态设置User-Agent(浏览器识别)
- 禁用cookies
- 使用VPN和代理IP
反爬虫科普:https://segmentfault.com/a/1190000005840672

 浙公网安备 33010602011771号
浙公网安备 33010602011771号