GO的逃逸分析
逃逸分析
前言
指的就是由编译器决定内存分配的位置,不需要由程序员来指定。函数中申请一个新的对象,其目的是为了提高程序的性能,减少内存分配和垃圾回收的开销。
- 分配在 栈 中, 则函数执行结束则可自动将内存回收
- 分配在 堆 中, 则函数执行结束可交给GC(垃圾回收)处理
go语言的逃逸分析遵循下面的两个不变性:
- 指向栈对象的指针不能存在于堆中
- 指向栈对象的指针不能在栈对象回收后存活
逃逸策略
每当函数中申请新的对象时,编译器会根据该对象是否被函数外部引用来决定是否逃逸:
- 如果函数外部
没有引用,则优先放到栈中 - 若函数外部
存在引用,则必定放到堆中
🔔注意: 像函数外部没有引用的对象,也有可能放到堆中,比如内存过大超过栈的存储能力
逃逸场景
指针逃逸
go可以返回局部变量指针,这就是一个典型的变量逃逸案例,如下:
package main
type Student struct {
Name string
Age String
}
func StudentRegister(name string, age int) *Student {
s := new(Student) // 这个局部变量s逃逸到堆中去了
s.Name = name
s.Age = age
return s
}
func main() {
StudentRegister("Lockly", 20)
}
通过编译参数 -gcflags=-m 可以验证编译过程中的逃逸分析:第9行显示”escapes to heap”,代表该行内存分配发生了逃逸现象
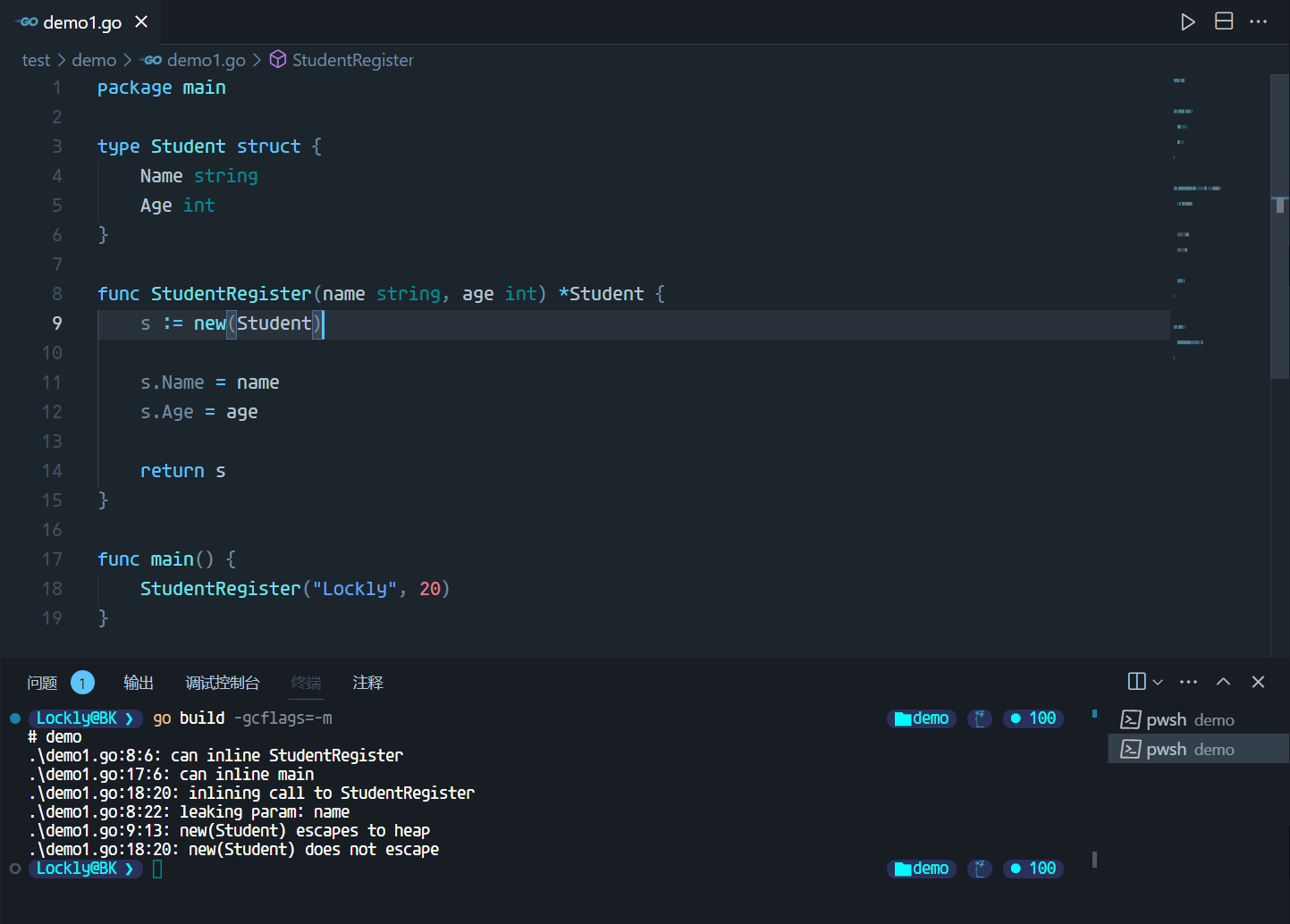
这里s会逃逸到堆上,是因为他的类型Student是一个结构体,而结构体的大小是不确定的,这个取决于他的字段。而编译器在编译期间无法确定结构体的大小,所以会将它分配到堆上,来避免栈溢出或者栈扩容的开销。这是一种保守的做法但就是为了确保内存安全。
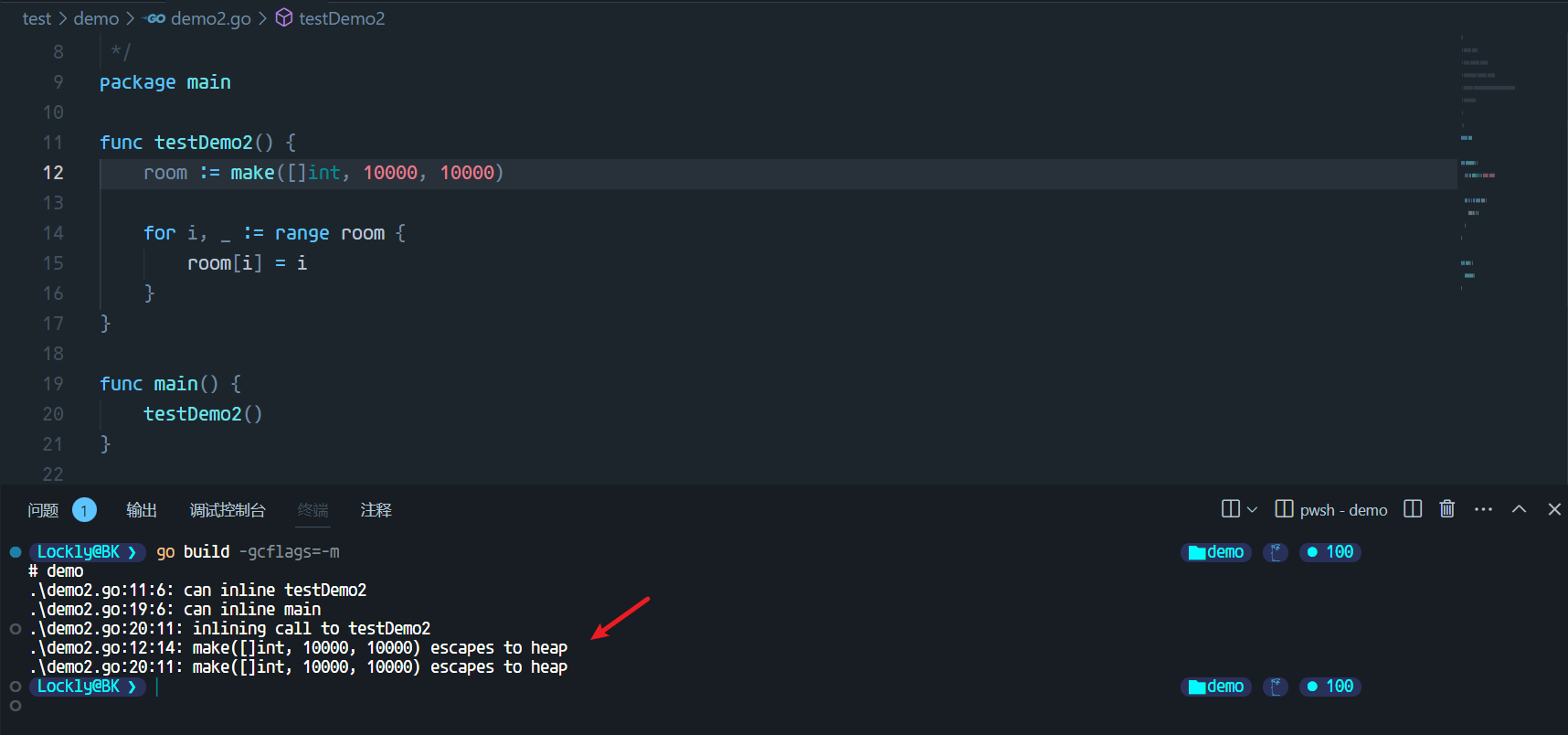
栈空间不足逃逸
这里分配了一个10000个长度的切片,可以看到编译提示中已经发生了逃逸。实际上就是当栈空间不足以存放当前对象时,或者无法判断当前切片长度时会将对象分配到堆中
动态类型逃逸
这里用编译参数去查看会发现s逃逸了,是因为他被作为参数传入fmt.Println(),这个函数的参数类型是interface{},这时编辑器无法在编译期间确定其具体类型,所以就会被分配到堆上。这是一种变量类型不确定的逃逸情况。
pacakge main
import "fmt"
func main() {
s := "Escape"
fmt.Println(s)
}
// 编译结果
Lockly@BK ❯ go build -gcflags='-m -l'
# demo/escape
.\demo3.go:7:13: ... argument does not escape
.\demo3.go:7:14: s escapes to heap
闭包引用对象逃逸
这里定义的闭包函数fibonacci返回了一个匿名函数func() int, 这个匿名函数引用了外部变量a, b,所以他们不能在栈上面分配,而必须在堆上分配。这是一种 变量生命周期不确定导致的逃逸情况。
package escape
import "fmt"
func fibonacci() func() int {
a, b := 0, 1
return func() int {
a, b = b, a+b
return a
}
}
func main() {
f := fibonacci()
for i := 0; i < 5; i++ {
fmt.Printf("result: %d\n", f())
}
}
决定变量是在栈上还是堆上虽然很重要,但这是一个定义相对清晰的问题。可以通过编译器统一做出决策。为了保证内存的绝对安全,编译器可能会将一些变量错误的分配到堆上面,就像上面的例子那样,但是因为这些堆也会被垃圾收集器处理,所以不会造成内存泄漏以及悬挂指针等安全问题,节省了coder的工作量。
Tips
- 尽量使用值传递而不是指针传递, 除非需要修改参数的值或者参数本身很大
- 尽量避免使用interface{}类型,会导致变量类型不确定的逃逸。
- 尽量避免使用闭包函数,会导致生命周期不确定的逃逸
- 尽量避免使用反射,会导致变量类型不确定的逃逸。
- 尽量使用局部变量而不是全局变量,因为全局变量会导致变量生命周期不确定的逃逸。
- 尽量使用固定大小的数组而不是切片,因为切片可能会导致动态内存分配和逃逸。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号