
Cookbook—函数
1. 编写可接受任意数量参数的函数
1.1 接受任意数量的位置参数,使用以 * 开头的参数,例如:
def avg(first, *args): print(args) return (first + sum(args)) / (1 + len(args)) print(avg(1, 2)) 1.5 print(avg(1, 2, 3, 4, 5)) 3.0
args是一个元组,包含所有传过来的位置参数,代码在之后的计算中会将其视为一个元组序列来处理。
1.2 接收任意数量的关键字参数,使用以 ** 开头的参数,例如:
def func(name, **kwargs): print(kwargs) age = kwargs.get("age") or 18 return f"name: {name}, age: {age}" print(func("ming", gender="female")) # name: ming, age: 18 print(func("ming", gender="female", age=22)) # name: ming, age: 22
kwargs是一个字典,包含所有传过来的关键字参数,代码中要是用到相关参数,可通过字典的方式取值。
一个函数想要同时接收任意数量的位置参数和关键字参数,只要联合使用 * 和 ** 即可,所有的位置参数都会放置在元组args中,所有的关键字参数都会放置在字典kwargs中。
1.3 在定义函数时,以 * 打头的参数后仍然可以跟其他参数,这种参数只能作为关键字参数使用,称为keyword-only参数。
def func2(*args, name): pass func2("a", "b", "c", "d") # TypeError: func2() missing 1 required keyword-only argument: 'name' func2("a", "b", "c", name="d")
2. 将元数据信息附加到函数参数上
我们在编写好一个函数后,希望为参数附加上一些额外的信息(即函数的参数注解),这样其他人可以对函数的使用方法有更多的了解。
函数注解只会保存在函数的__annotations__属性中。
def func3(x: int, y: int=20) -> int: return x + y print(func3(60)) # 80 print(func3("a", "b")) # ab print(func3.__annotations__) # {'x': <class 'int'>, 'y': <class 'int'>, 'return': <class 'int'>}
上述函数注解即:x,y为int类型参数,y的默认值为20,输出的结果类型为int类型。
python 解释器应不会附加任何语法意义到这些参数注解上,他们既不是类型检查也不会改变Python的行为,所以即使声明形参x,y为int类型,但是调用函数的时候实参为字符串,函数也能正常执行。
尽管可以将任何类型的对象作为函数注解附加到函数定义上(比如数字,字符串,实例等),但是通常只有类和字符串才显得最有意义。
3. 定义带有默认值参数的函数
3.1 如何定义?只需要在定义函数参数时为参数赋值,并确保默认值参数出现在形参最后即可。
def func4(a, b=50): return a + b print(func4(10)) print(func4(10, 100))
给默认参数赋值时的值一定是不可变对象,比如 None,True,False,数字或者字符串或者元组。否则默认值在函数体之外被修改了,那么这种修改会对参数的默认值产生持续影响。
def func5(a, score_list=[]): return score_list result1 = func5(25) print(result1) # [] result1.append(50) result1.append(100) result2 = func5(25) print(result2) # [50, 100] 因为result1和score_list的内存地址一样,result1添加值导致score_list也被修改了,所以result2再次调用函数时,对应的score_list已经是修改过的了,已经不再是空[]了
3.2 如果默认值是可变容器(list,set,dict)时,此时应该把None作为默认值,在函数体里面再对默认参数处理。
在函数体对默认参数处理时一定是使用 is 操作符,如果使用 if not score_list: pass,那么输入值为空list,空dict,空字符串也会被判定为False。
def func6(score_list=None): if score_list is None: score_list = [] return score_list
这样 result1=func6(),实际上result1的内存地址对应的是函数体里面重新赋值的空 [] 的内存地址,不会对参数的默认值产生影响。
3.3 如果不打算提供默认值,只是想检测可选参数是否被赋予了某个特定的值,可以用object()创建一个私有实例。
_no_value_var = object() def func7(score_list=_no_value_var): if score_list is _no_value_var: print("there is no varies!") func7()
在函数中检测是否对可选参数提供了某个特定值,我们不能用None,0,False等作为默认值来检测用户是否提供了参数,因为这些值都是完全合法的参数,用户极有可能把它们当做入参使用。这时我们可以用object()创造一个独特的私有变量,因为对用户来说把这个实例变量作为入参是几乎不可能的,所以它就成为了一个恶意用来安全比较的值。
4. 匿名函数中绑定变量的值
4.1 定义匿名函数时,给定默认值:就行普通函数的默认值参数一样。
f = lambda x, y=10: x + y print(f(10)) # 20 print(f(10, 40)) # 50
4.2 我们在定义匿名函数时,希望对某个变量进行绑定。
func_list = [lambda x: x+n for n in range(5)] for f in func_list: print(f(0))
仔细思考一下,输出的结果是什么?为什么是5个4呢?这是因为lambda表达式中用到的n是一个自由变量,n只有在执行时才进行绑定而不是定义的时候绑定,所以上面的func_list的5个元素都是x+n,在for循环遍历func_list时,n已经等于4了,所以每一次for循环都是return 0+4!如果我们在定义匿名函数时进行变量绑定,将某个值作为默认参数和变量进行绑定,这样匿名函数在定义时就能捕获到n的值了,如下:
func_list2 = [lambda x, n=n: x+n for n in range(5)] for f in func_list2: print(f(0))
在每次遍历 range(5) 时,都把变量n的值作为默认参数赋值给匿名函数,匿名函数中的变量n的内存地址指向该次遍历值得内存空间,所以得到的结果就为0,1,2,3,4
5. 让带有N个参数的可调用对象能够以较少的参数个数调用
对下面一组数据进行排序(如果值小于20就加100)。
info = {'lilee': 25, 'age': 24, 'phone': 12}
def add_val(x):
return x[1] + 100 if x[1] < 20 else x[1]
print(sorted(info.items(), key=add_val)) # [('age', 24), ('lilee', 25), ('phone', 12)]
上面的100是我们规定好了的,如果让用户自己输入值呢?那就在add_val函数中再增加一个参数,但是在sorted函数中就会报错,因为sorted()方法可接受一个key参数用来做自定义的排序处理,但是这个key只能和接受单个参数的函数一个工作,因此不能在add_val中添加第二个参数!
如果需要减少交互函数的入参个数,应该使用 functools.partial(),函数partial()允许我们给一个或多个参数指定固定的值,以此减少需要提供给交互函数的参数数量。上面的排序就可以重新实现:
def add_val_2(x, y, z): return x[1] + y + z if x[1] < 20 else x[1] info = {'lilee': 25, 'age': 24, 'phone': 12} from functools import partial print(sorted(info.items(), key=partial(add_val_2, y=50, z=100)))
例1:以多进程异步方式计算某个结果,并将这个结果传递个给一个回调函数,还毁掉函数可接受这个结果以及一个可选的日志参数:
import logging from multiprocessing import Pool from functools import partial logging.basicConfig(level=logging.DEBUG) log = logging.getLogger("test") def add(x, y): return x + y def output_result(result, log=None): if log is not None: log.debug(f"Get result: {result}") else: print(f"Get result: {result}") if __name__ == '__main__': p = Pool() # p.apply_async(add, args=(3, 4), callback=output_result) p.apply_async(add, args=(3, 4), callback=partial(output_result, log=log)) p.close() p.join()
用 partial() 就可以继续给回调函数传多个参数(log对象或其他参数),非常实用!
注意:有时候使用lambda表达式也可以来代替 partial(),所以上面的表达式也可以这么写:
sorted(info.items(), key=lambda x: add_val_2(x, y=0, z=100)) p.apply_async(add, args=(3, 4), callback=lambda x: output_result(x, log=log))
这些代码也可以正常运行,但是却显得非常啰嗦,让人读起来特别地费解。使用partial()会使你的意图更加明确,partial()即为某些函数的参数提供默认值。
6. 用函数替代只有单个方法的类
class PerInfo: def __init__(self, name): self.name = name def get_name(self): return self.name p = PerInfo("ming") name = p.get_name()
我们使用单个方法(不包括__init__()方法)的类的唯一原因就是保存额外的状态给类的方法使用。但是一个类里只有一个方法是不是有点大题小做了?使用嵌套函数或者说闭包常常会显得更加优雅。
def person_info(name, baseage=15): def get_age(): return f"{name} age is {baseage}" return get_age() age = person_info("gang") print(age)
闭包就是一个函数,但是它还保存着额外的变量环境,是的这些个变量可以在函数中使用。闭包的核心特性就是他可以记住定义闭包时的环境。所以在编写代码中遇到需要附加额外的状态给函数时,我们可以考虑使用闭包。
7. 访问定义在闭包内的变量
7.1 为函数添加属性
函数定义好之后,我们能否继续为这个函数添加一些属性?
def func(): return "123" func.name = "get_123" print(func()) # 123 print(func.name) # get_123
显然是可以的,这是因为我们在定义函数时,关键字def 有两个功能:它可以创建一个函数对象;然后把这个函数对象赋值给一个变量(即我们的函数名)。函数的属性以字典的形式存储,key为属性名,value为属性值,可以在定义函数的同时定义属性,也可以在定义函数完成之后再定义函数属性(函数属性可以用过__dict__()查看所有属性)
def func(): return "123" print(func.__dict__) # {} func.name = "get_123" print(func.__dict__) # {'name': 'get_123'}
7.2 访问并修改闭包内的变量
在闭包内层定义的变量对于外界来说是完全隔离的,但是可以通过编写存取函数(如下示例的 get_n,set_n)并将它们作为函数属性附加到闭包上来提供对内存变量的访问支持,如下:
def sample(): n = 0 def func(): print(f"n={n}") def get_n(): return n def set_n(value): nonlocal n n = value func.get_n = get_n func.set_n = set_n return func f = sample() f() print(f.get_n()) # 0 f.set_n(100) print(f.get_n()) # 100
这里主要用到了两个特性:nonlocal声明使得编写函数来修改内层变量成为可能;将存取函数以属性的方式附加到闭包函数上,使闭包函数可以直接调用。
8. 在回调函数中携带额外的状态参数
我们在编写使用回调函数的代码时,希望回调函数可以携带额外的状态参数以便在回调函数内部使用。
def apply_async(func, args, callback=None): result = func(*args) callback(result) def add(x, y): return x + y def print_result(result): print(f"the final result is {result}") apply_async(add, args=(2, 5), callback=print_result)
上述的回调函数的入参只能是add()的返回结果,无法携带第二个或多个参数,有多种方式可以解决这个问题。
1. 使用partial() 或 lambda匿名函数来为回调函数提供多个参数,详细内容可参考上述第5条;
2. 在回调函数时使用绑定类实例方法:
def apply_async(func, args, callback=None): result = func(*args) callback(result) def add(x, y): return x + y class ResultHandler: def __init__(self, n): self.multi_value = n def handler(self, result): final_result = result * self.multi_value print(f"the final result is {final_result}") n = int(input("input multi_value: ")) hd = ResultHandler(n) apply_async(add, args=(2, 5), callback=hd.handler)
3.作为类的替代方案,也可以使用闭包来捕获状态:
def apply_async(func, args, callback=None): result = func(*args) callback(result) def add(x, y): return x + y def result_handler(n): multi_value = n def result_multi(result): nonlocal multi_value multi_value += 1 final_result = result * multi_value print(f"the final result is {final_result}") return result_multi n = int(input("input multi_value: ")) # 10 handler = result_handler(n) apply_async(add, args=(2, 5), callback=handler) # 77 apply_async(add, args=(2, 5), callback=handler) # 84 apply_async(add, args=(2, 5), callback=handler) # 91
4. 利用生成器的方式实现(yield关键字用法参考 https://www.cnblogs.com/wushuaishuai/p/9212812.html):
def apply_async(func, args, callback=None): result = func(*args) callback(result) def add(x, y): return x + y def func_count(): sequence = 0 while 1: result = yield sequence += 1 print(f"times:{sequence}, result value is {result}") handler = func_count() next(handler) apply_async(add, args=(2, 5), callback=handler.send) # times:1, result value is 7 apply_async(add, args=(2, 5), callback=handler.send) # times:2, result value is 7
首先实现一个生成器,然后调用next()方法,使程序执行到 result=yield这句,因为是一个yield语句,所以整个执行过程被挂起,next()的返回值为yield后面的内容,即None;然后在执行send()方法时,将表达式yield的返回值定义为send()方法的参数值(即经过add()计算后的result值),即程序中的result=add()返回值,然后程序继续执行后面的语句,+=1...print...
注意:在使用生成器的send()方法时,一定要先对其调用一次next(),使程序运行到yield处然后挂起。
9. 内联回调函数
我们在编写使用回调函数代码时,总是担心小型函数在代码中大肆泛滥,程序的控制流就会因此而失控,比如下面的这几段代码。
# 回调函数功能:将计算出的结果打印出来 def apply_sync(func, args, callback): result = func(*args) callback(result) def add(a, b): return a + b def printout(result): print(result) apply_sync(add, args=(2, 3), callback=printout)
我们希望能够有某种方法使代码看起来更像一般的过程式步骤,如何实现?我们可以通过生成器和协程将回调函数内联到一个函数中:
from functools import wraps from queue import Queue class Async: def __init__(self, func, args): self.func = func self.args = args def apply_sync(func, args, callback): result = func(*args) callback(result) def add(a, b): return a + b def inline_async(func): @wraps(func) def wrapper(*args): result = func(*args) result_queue = Queue() result_queue.put(None) while True: result_from_queue = result_queue.get() try: a = result.send(result_from_queue) apply_sync(a.func, a.args, callback=result_queue.put) except StopIteration: break return wrapper @inline_async def test(): r1 = yield Async(add, (2, 3)) print(r1) r2 = yield Async(add, ("hello", "world")) print(r2) test()
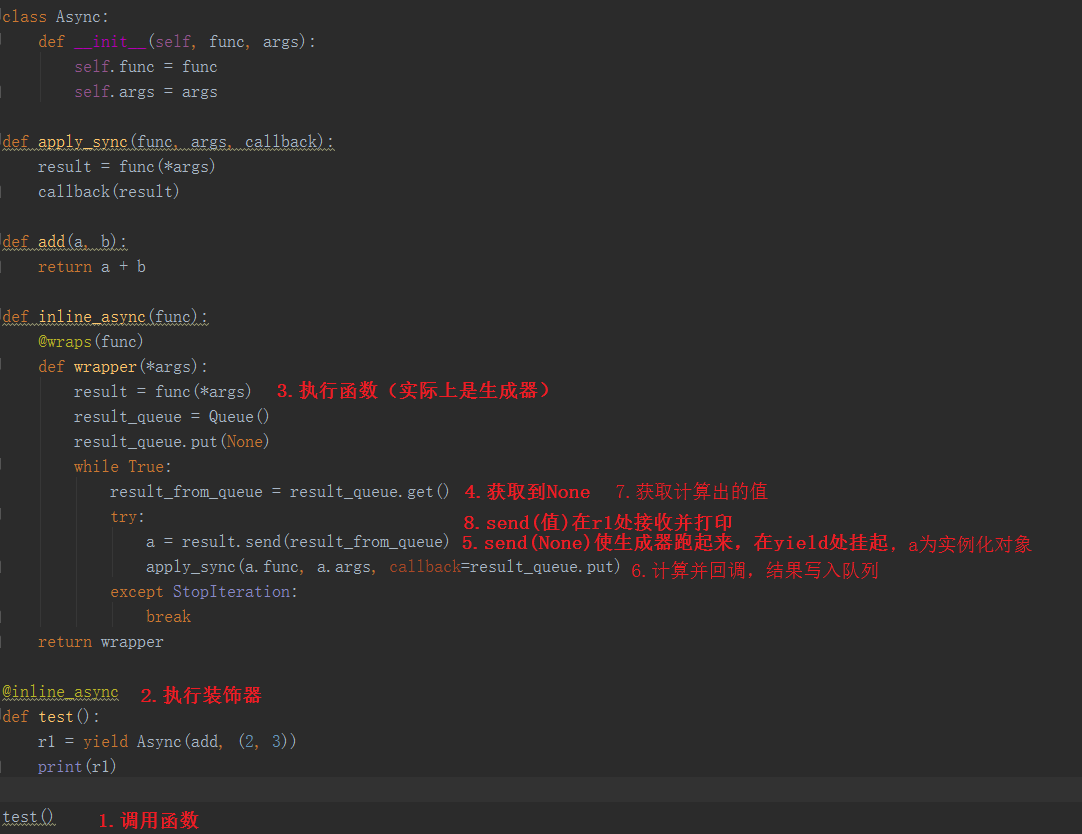
除了上面特殊的装饰器和对yield的使用外,我们发现代码中根本没有出现回调函数(它们事不过隐藏在装饰器里而已)。
程序的核心点在inline_async()装饰器函数中:对于生成器函数的所有yield语句,装饰器都会逐条进行跟踪,一次一个。我们创建了一个队列来保存结果,初始值我们用None来填充,当执行到send(None)时, 生成器函数开始执行并在yield处挂起,然后用变量a来接收yield后面的值(即Async的实例),紧接着执行spply_sync(),并将结果put入队列里,之后通过循环将结果从队列中取出,然后send()发送给生成器,生成器紧接着执行yield表达式并将yield表达式的返回值定义为取出来的结果,用变量接收,然后打印出来,实现回调函数的功能;如果从队列中什么都没有get()到,操作就会阻塞,等待之后某个时刻会有结果到来。至于结果如何产生就取决于apply_async()主体函数的实现了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号