

玩一玩pandas
1. 构造供pandas使用的DataFrame数据
import pandas as pd lst = [ ["susan", 25, "male", "北京"], ["merry", 36, "female", "杭州"], ["jake", 23, "male", "苏州"], ["mali", 12, "female", "上海"], ["wus", 42, "male", "武汉"], ] dfcols = ["name", "age", "gender", "live"] # 只含有列名的空 DataFrame(简称 DF) df = pd.DataFrame(columns=dfcols) # 两个 DF上下合并, ignore_index=True: 忽略行索引在原 DF基础上继续增加行索引 df = df.append(pd.DataFrame(data=lst, columns=dfcols), ignore_index=True) print(df)

2. 从 Excel 或 csv 文件读取数据

3. 基本的DF查询数据
df.values # type: "<class 'numpy.ndarray'>" df.values.tolist() # type: "<class 'list'>" df["name"] # 获取到name 这一列的值 df.loc["index的行索引"] # 显式索引, 获取到行索引为xx的这一行数据 df.iloc[1] # 隐式索引, 获取到第2行的数据 df.loc[2, "name"] # 第2行数据的 name 值 df.loc[0:3] # 第1行 到 第3行的数据
4. DF添加一行数据 (行数据为 Series 一维数组)
df = df.append(pd.Series(["lee", 32, "female", "西安"], index=dfcols), ignore_index=True) print(df)

5. DF按条件过滤数据
# 过滤出年龄大于 30岁 的人 df[df["age"] > 30]
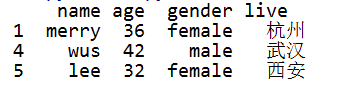
# 第2行数据的age值改为空值 df.loc[3, "age"] = None print(df)
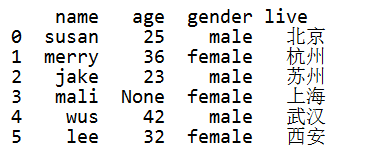
# 删除有空值的行数据 print(df[df["age"].notnull()]) # 在pandas的drop系列函数中, axis=0表示x轴数据(行数据), 1表示y轴数据(列数据) print(df.dropna(axis=0)) 上面两种方式都一样

6. groupby()分组
参数: as_index -- 默认值为True, 用于聚合输出. 当 as_index=True 时返回以分组名作为索引的对象(即分组后的DF行索引为分组名)
当 as_index=True 时, DF 查询数据时既可以用显式索引也可以用隐式索引; 当 as_index=False 时表示使用原来的行索引, 所以 DF 查询数据只能使用隐式索引.
result1 = df.groupby(df["gender"]).sum() result2 = df.groupby(df["gender"], as_index=False).sum()
对比 result1 和 result2:
result1: 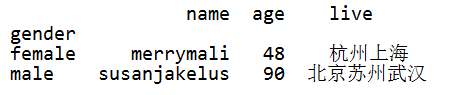 result2:
result2: 
# 支持显式和隐式索引 result1 = df.groupby(df["gender"]).sum() print(result1.iloc[0]) print(result1.loc["female"]) # 仅支持隐式索引 result2 = df.groupby(df["gender"], as_index=False).sum() print(result2.iloc[0])
7. 非常好用的agg()方法
# 对某一列执行一个聚合函数: 执行agg()参数的聚合函数, 在参数中如果是内置函数则需要加"", 非内置函数不需要加"" print(df.groupby(df["gender"])["age"].agg("sum"))
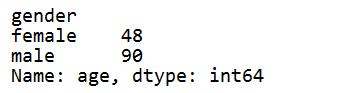
# 对某一列执行多个聚合函数, 前后聚合函数是解耦合的(不是在 sum 的基础上求 std) print(df.groupby(df["gender"])["age"].agg(["sum", "std"]))

# 如果agg()传入的是(name, func)元组组成的列表, 则 name 为聚合之后的列名 print(df.groupby(df["gender"])["age"].agg([("年龄总和", "sum"),("年龄标准值","std")]))

# 对多列执行多个相同的聚合函数 print(df.groupby(df["gender"])["age", "work_times"].agg(["count", "sum", "std"]))

# 对多列执行对应的聚合函数 print(df.groupby(df["gender"]).agg({"age": "sum", "work_times":"std"}))

# 对多列执行对应的聚合函数, 并且自定义列名 print(df.groupby(df["gender"]).agg({"age": [("年龄总和", "sum")], "work_times":[("工作年限标准值", "std")]}))

# 这两种方式结果大同小异, 都可以用来解决问题 result1 = df.groupby(df["gender"])["age"].agg("sum").rename("sum_age").reset_index() print(result1.iloc[0].sum_age) result2 = df.groupby(df["gender"])["age"].agg([("sum_age", "sum")]) print(result2.iloc[0].sum_age)

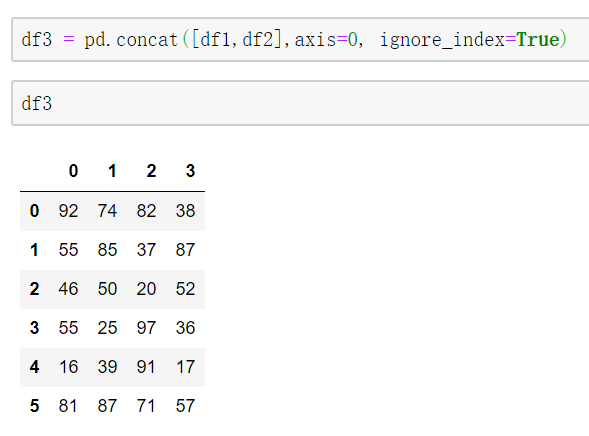
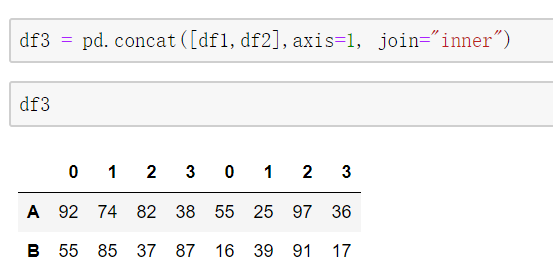
8. concat()
ignore_index: 连接后再重新赋值index(len(index))
join: "outer" 会将所有的项进行级联, 不管匹配或不匹配; 而 "inner" 只会将所有匹配到的项进行级联,不匹配的不级联



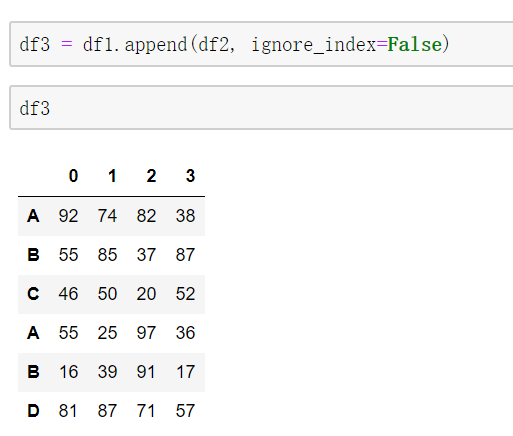
9. append()
ignore_index: 参数意义同 concat
注: append() 方法和Python的list中的append()方法不一样, 前者不是在原来的 DataFrame 基础上进行添加, 而是得需要有一个新的变量去接收。
10. merge()
merge与concat的区别在于,merge需要依据某一共同的列来进行合并。
使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
注意每一列元素的顺序不要求一致。
参数: how:{'left', 'right', 'outer', 'inner'}, default 'inner'。 "out"取并集, "inner"取交集, "left"以左边为准, 保留左边DF信息, "right"反之亦然。
on: on的值为一个列索引或列表或, 当有多列相同时可以使用on来指定使用哪些列进行合并。
suffixes:对相同列进行重命名。
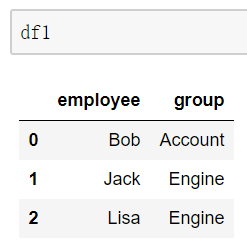
简单合并

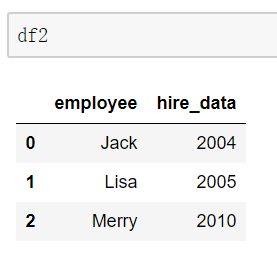

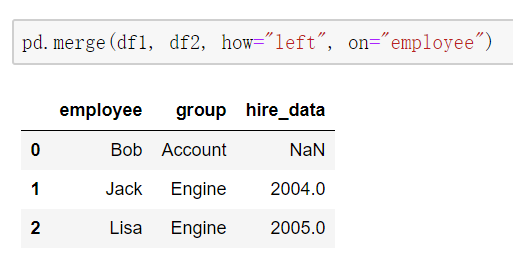
当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个列作为key,其余相同列会被命名为列_x, 列_y。配合suffixes指定冲突列名 (on不指定时,哪个表在前就用前面表相同列(联合起来)作为key)

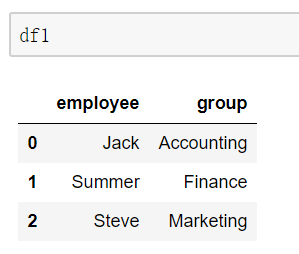
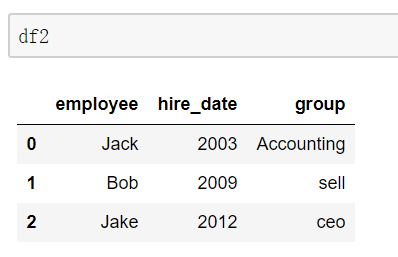
suffixes的使用:
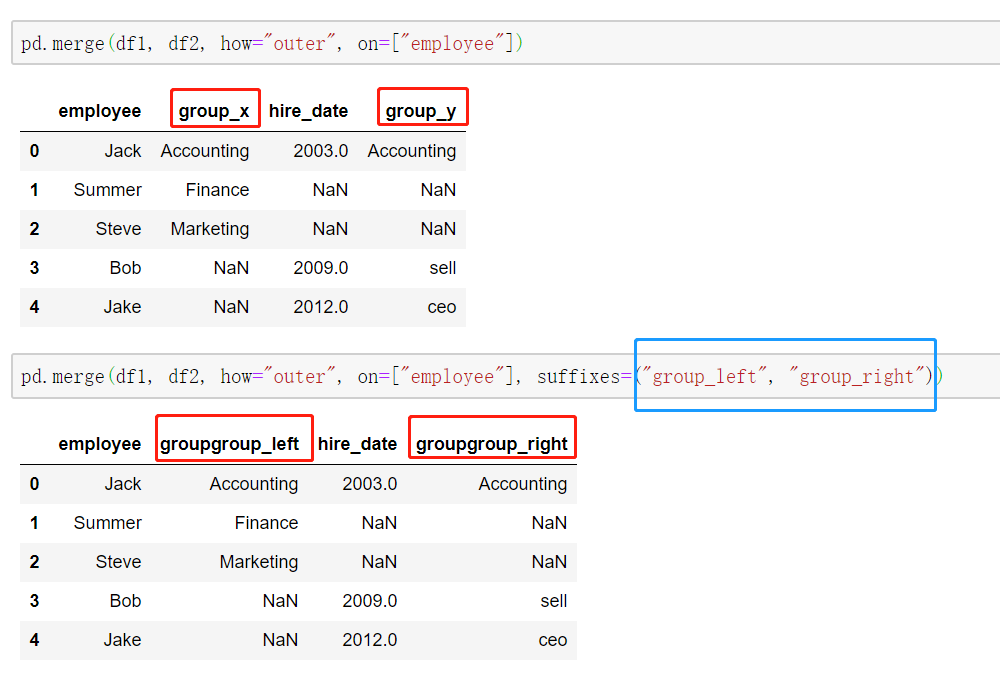
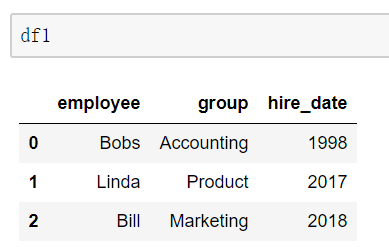
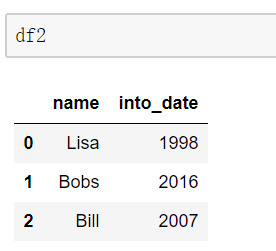
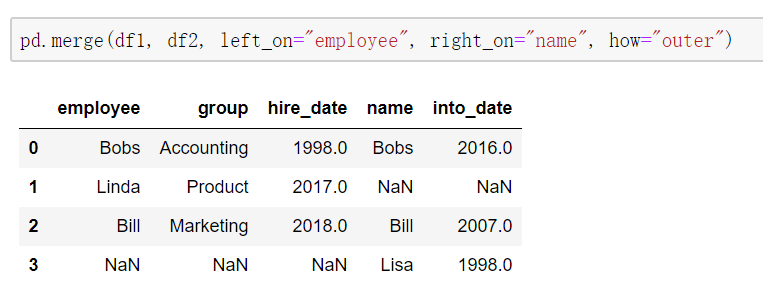
当两张表没有可进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列列作为连接的列

待补充...

