
scrapy爬虫框架和selenium的配合使用
scrapy框架的请求流程
scrapy框架?
Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。
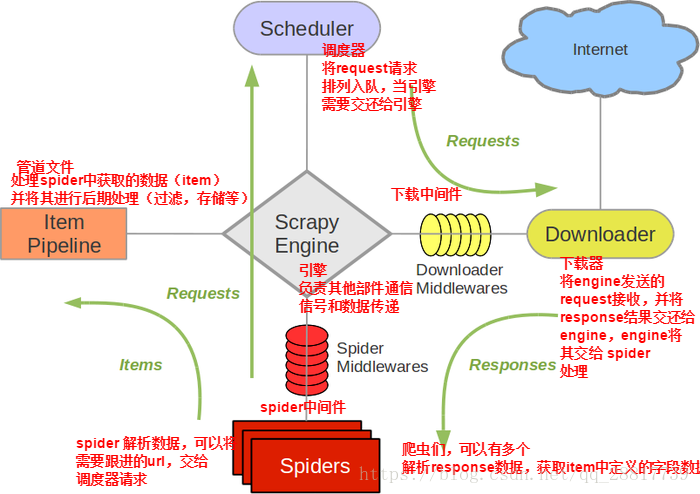
1、引擎(EGINE) 引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。 2、调度器(SCHEDULER) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 3、下载器(DOWLOADER) 用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的 4、爬虫(SPIDERS) SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求 5、项目管道(ITEM PIPLINES) 在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作 下载器中间件(Downloader Middlewares)位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response, 6、爬虫中间件(Spider Middlewares) 位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
安装和创建: https://www.cnblogs.com/pyedu/p/10314215.html
scrapy框架+selenium的使用
1 使用情景:
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值
2 使用流程
1 重写爬虫文件的__init__()构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次).
2 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象,该方法是在爬虫结束时被调用.
3 重写下载中间件的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据.
4 在settings配置文件中开启下载中间件
3 使用案例: 爬取XXX网站新闻的部分板块内容
爬虫文件:
from selenium import webdriver from selenium.webdriver.chrome.options import Options # 使用无头浏览器 无头浏览器设置 chorme_options = Options() chorme_options.add_argument("--headless") chorme_options.add_argument("--disable-gpu") class WangyiSpider(scrapy.Spider): name = 'wangyi' # allowed_domains = ['wangyi.com'] # 允许爬取的域名 start_urls = ['https://news.163.com/'] # 实例化一个浏览器对象 def __init__(self): self.browser = webdriver.Chrome(chrome_options=chorme_options) super().__init__() def start_requests(self): url = "https://news.163.com/" response = scrapy.Request(url,callback=self.parse_index) yield response # 整个爬虫结束后关闭浏览器 def close(self,spider): self.browser.quit() # 访问主页的url, 拿到对应板块的response def parse_index(self, response): div_list = response.xpath("//div[@class='ns_area list']/ul/li/a/@href").extract() index_list = [3,4,6,7] for index in index_list: response = scrapy.Request(div_list[index],callback=self.parse_detail) yield response # 对每一个板块进行详细访问并解析, 获取板块内的每条新闻的url def parse_detail(self,response): div_res = response.xpath("//div[@class='data_row news_article clearfix ']") # print(len(div_res)) title = div_res.xpath(".//div[@class='news_title']/h3/a/text()").extract_first() pic_url = div_res.xpath("./a/img/@src").extract_first() detail_url = div_res.xpath("//div[@class='news_title']/h3/a/@href").extract_first() infos = div_res.xpath(".//div[@class='news_tag//text()']").extract() info_list = [] for info in infos: info = info.strip() info_list.append(info) info_str = "".join(info_list) item = WangyiproItem() item["title"] = title item["detail_url"] = detail_url item["pic_url"] = pic_url item["info_str"] = info_str yield scrapy.Request(url=detail_url,callback=self.parse_content,meta={"item":item}) # 通过 参数meta 可以将item参数传递进 callback回调函数,再由 response.meta[...]取出来 # 对每条新闻的url进行访问, 并解析 def parse_content(self,response): item = response.meta["item"] # 获取从response回调函数由meta传过来的 item 值 content_list = response.xpath("//div[@class='post_text']/p/text()").extract() content = "".join(content_list) item["content"] = content yield item
下载中间件中篡改响应数据
需要导入 HtmlResponse类, 这个类是用来将响应数据包装成符合HTTP协议形式.
from scrapy.http import HtmlResponse
class WangyiproDownloaderMiddleware(object): # 可以拦截到request请求 def process_request(self, request, spider): # 在进行url访问之前可以进行的操作, 更换UA请求头, 使用其他代理等 pass # 可以拦截到response响应对象(拦截下载器传递给Spider的响应对象) def process_response(self, request, response, spider): """ 三个参数: # request: 响应对象所对应的请求对象 # response: 拦截到的响应对象 # spider: 爬虫文件中对应的爬虫类 WangyiSpider 的实例对象, 可以通过这个参数拿到 WangyiSpider 中的一些属性或方法 """ # 对页面响应体数据的篡改, 如果是每个模块的 url 请求, 则处理完数据并进行封装 if request.url in ["http://news.163.com/domestic/","http://war.163.com/","http://news.163.com/world/","http://news.163.com/air/"]: spider.browser.get(url=request.url) # more_btn = spider.browser.find_element_by_class_name("post_addmore") # 更多按钮 # print(more_btn) js = "window.scrollTo(0,document.body.scrollHeight)" spider.browser.execute_script(js) # if more_btn and request.url == "http://news.163.com/domestic/": # more_btn.click() time.sleep(1) # 等待加载, 可以用显示等待来优化. row_response= spider.browser.page_source return HtmlResponse(url=spider.browser.current_url,body=row_response,encoding="utf8",request=request) # 参数url指当前浏览器访问的url(通过current_url方法获取), 在这里参数url也可以用request.url # 参数body指要封装成符合HTTP协议的源数据, 后两个参数可有可无 else: return response # 是原来的主页的响应对象 # 请求出错了的操作, 比如ip被封了,可以在这里设置ip代理 def process_exception(self, request, exception, spider): print("添加代理开始") ret_proxy = get_proxy() request.meta["proxy"] = ret_proxy print("为%s添加代理%s" %(request.url,ret_proxy), end="") return None # 其他方法无需动
中间件文件里设置UA池:
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware user_agent_list = [ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 " "(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 " "(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 " "(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 " "(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 " "(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 " "(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 " "(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 " "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 " "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" ] class RandomUserAgent(UserAgentMiddleware): # 如何运行此中间件? settings 直接添加就OK def process_request(self, request, spider): ua = random.choice(user_agent_list) # 在请求头里设置ua request.headers.setdefault("User-Agent",ua)
settings配置文件中:
DOWNLOADER_MIDDLEWARES = { 'WangYiPro.middlewares.WangyiproDownloaderMiddleware': 543, 'WangYiPro.middlewares.RandomUserAgent': 542, }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号