


数组、链表等常用数据结构和集合浅解(java)
------数据结构:
是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。
1.集合
数据结构中的元素之间除了“同属一个集合” 的相互关系外,别无其他关系;
2.线性结构
数据结构中的元素存在一对一的相互关系;
3.树形结构
数据结构中的元素存在一对多的相互关系;
4.图形结构
数据结构中的元素存在多对多的相互关系。
常用数据结构:数组、栈、队列、链表、树、图、堆、散列表
------简单介绍如下:
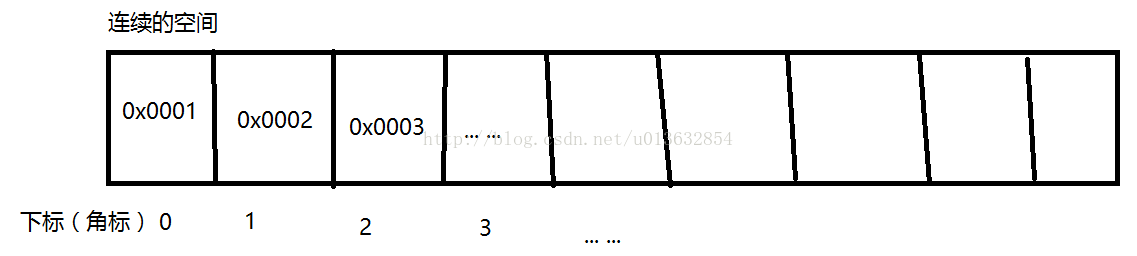
------数组:
数组是在内存中开辟一段连续的空间,并在此空间存放元素。就像是一排出租屋,有100个房间,从001到100每个房间都有固定编号,通过编号就可以快速找到租房子的人。
数组的特点是:
元素类型是固定的、长度是固定的、通过角标查询,查询快,增删慢。
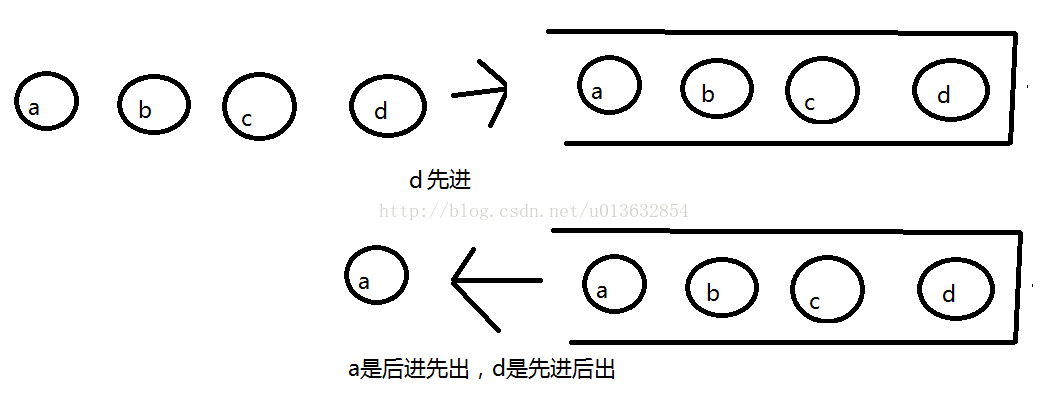
------栈:
线性结构。就像是坐电梯,只有一个口,有顺序地进出,并且只能一端进与出,称为LIFO,先进后出或者后进先出,顾名思义就是先进去的就后出来,类似坐电梯,先进去的人会被后进去的人给不断的挤到后边去,此举称之为压栈。底层是用LinkedList来实现的。
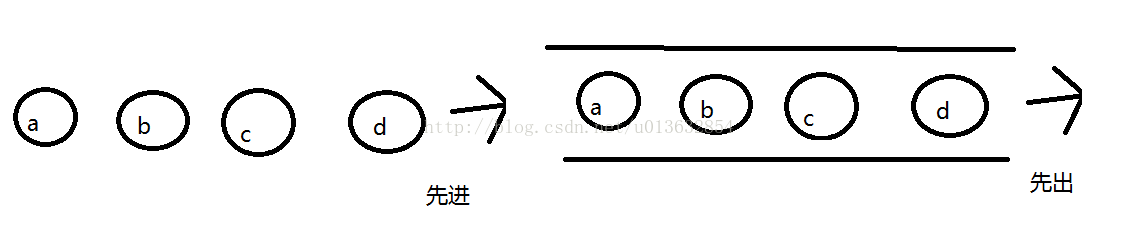
------队列:
线性结构。就像是一条水管,有两端,有顺序地进出,并且只能一端进另一端出,称为FIFO,先进先出,顾名思义就是先进去的就先出来,如果你要删除,只能从出口端,一个一个的顺序删除,同理,要增加,也只能通过入口端顺序地添加进去。底层是用LinkedList来实现的。
------链表:
链表的类型有多种:单链表,双链表,有序链表
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。
可以这样理解:
有一条街,小明住在街中一角,他有小红的地址,然后小红也是住在这条街,她有小花的地址,同样小花也有别人的地址。某天我想找小红玩,但是我不知道她住哪里,我可以问小明,就知道小红住在哪里了。那么小明小红小花这些人之间的关系就组成一个链表。
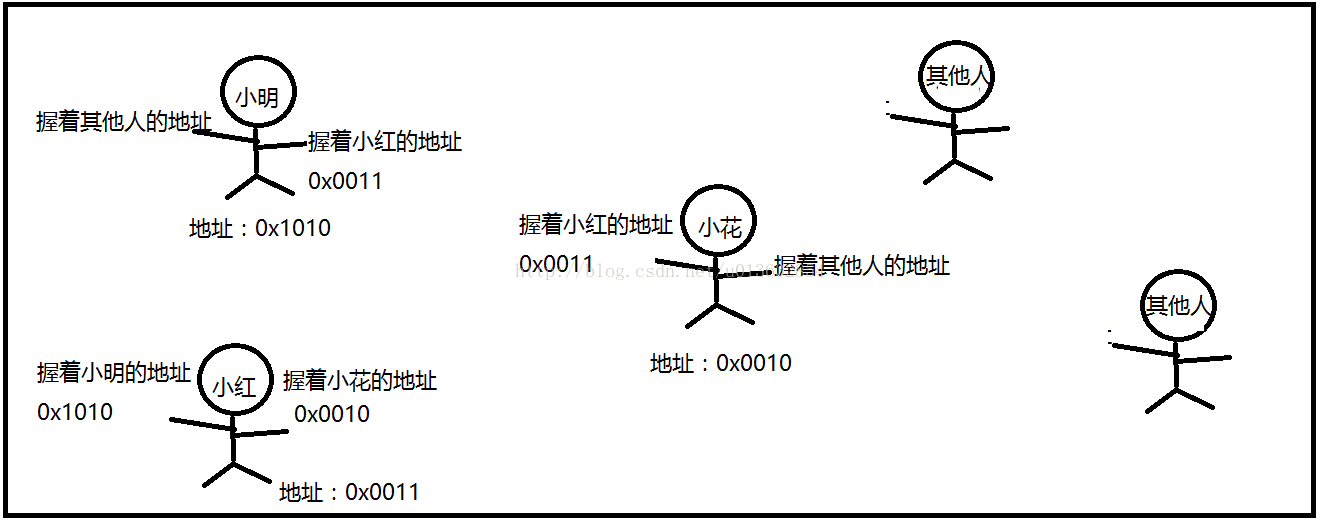
单链表:
就是小明只是右手握着小红的地址,他只有小红一个人的地址
双链表:
就是小明左手握着小白的地址,右手握着小红的地址,他有两个人的地址
循环链表:
就是小明握有小红的地址,小红握有小花的地址,而小花又握有小明的地址,这样就形成了一个循环
有序链表:
以某个标准,给链表的元素排序,比如比较内容大小、比较哈希值等
链表与数组比较:
优点:链表不需要确定长度大小,也不需要连续的内存空间,
缺点:由于不是连续的空间,所以查找元素比较吃力;相比数组只存储元素,链表的元素还要存储其它元素的地址,内存开销相对增大。
------二叉树:
这个...额...用语言描述有点词穷,还是看图比较清晰(下图盗自百度)
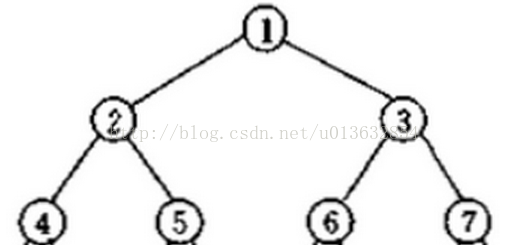
二叉树是每个节点最多有两个子树的树结构。顶上的叫根结点,两边被称作“左子树”和“右子树”。二叉树常被用于实现二叉查找树和二叉堆。
遍历是对树的一种最基本的运算,所谓遍历二叉树,就是按一定的规则和顺序走遍二叉树的所有结点,使每一个结点都被访问一次,而且只被访问一次。由于二叉树是非线性结构,因此,树的遍历实质上是将二叉树的各个结点转换成为一个线性序列来表示。
二叉树的遍历大概分为四种,分别是前序遍历,中序遍历,后序遍历,按层遍历
以上图为例:
前序遍历:根-->左-->右(1-->2-->4-->5-->3-->6-->7 )
中序遍历:左-->根-->右(4-->2-->5-->1-->3-->6-->7)
后序遍历:左-->右-->根(4-->5-->2-->6-->7-->3-->1)
按层遍历:从上到下,从左到右(1-->2-->3-->4-->5-->6-->7)
二叉树与树的区别:
1、二叉树,顾名思义就是每个结点最多只有两个分支,可以有一个,但最多两个;树就没有这个规则,树的一个结点可以有不确定个分支
2、二叉树的结点有左右之分;树的结点没有左右之分
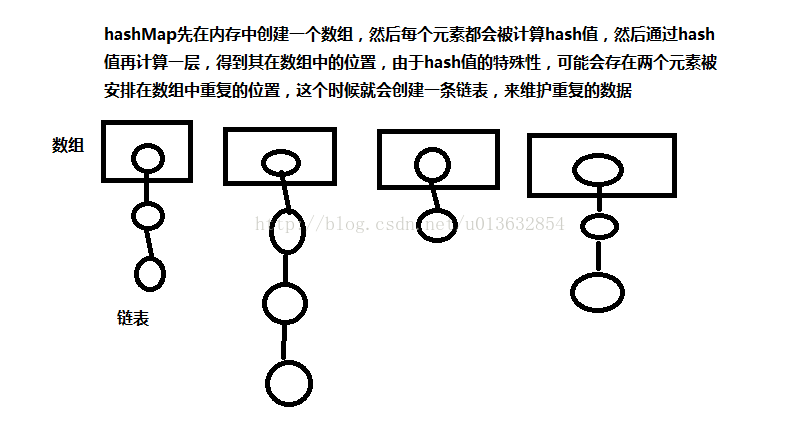
------哈希表:
百度百科这样说的:散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
可以这样理解:(不太准确但是比较形象)
每个人都有自己的特征,获取这个特征的方法就叫哈希函数,一堆这样的特征被存起来就叫做哈希表
代表:
MD5、SHA-1
作用:
文件校验、数字签名
缺点:
哈希表不可避免冲突(collision)现象:对不同的关键字可能得到同一哈希地址 即key1≠key2,而hash(key1)=hash(key2)。具有相同函数值的关键字对该哈希函数来说称为同义词(synonym)。
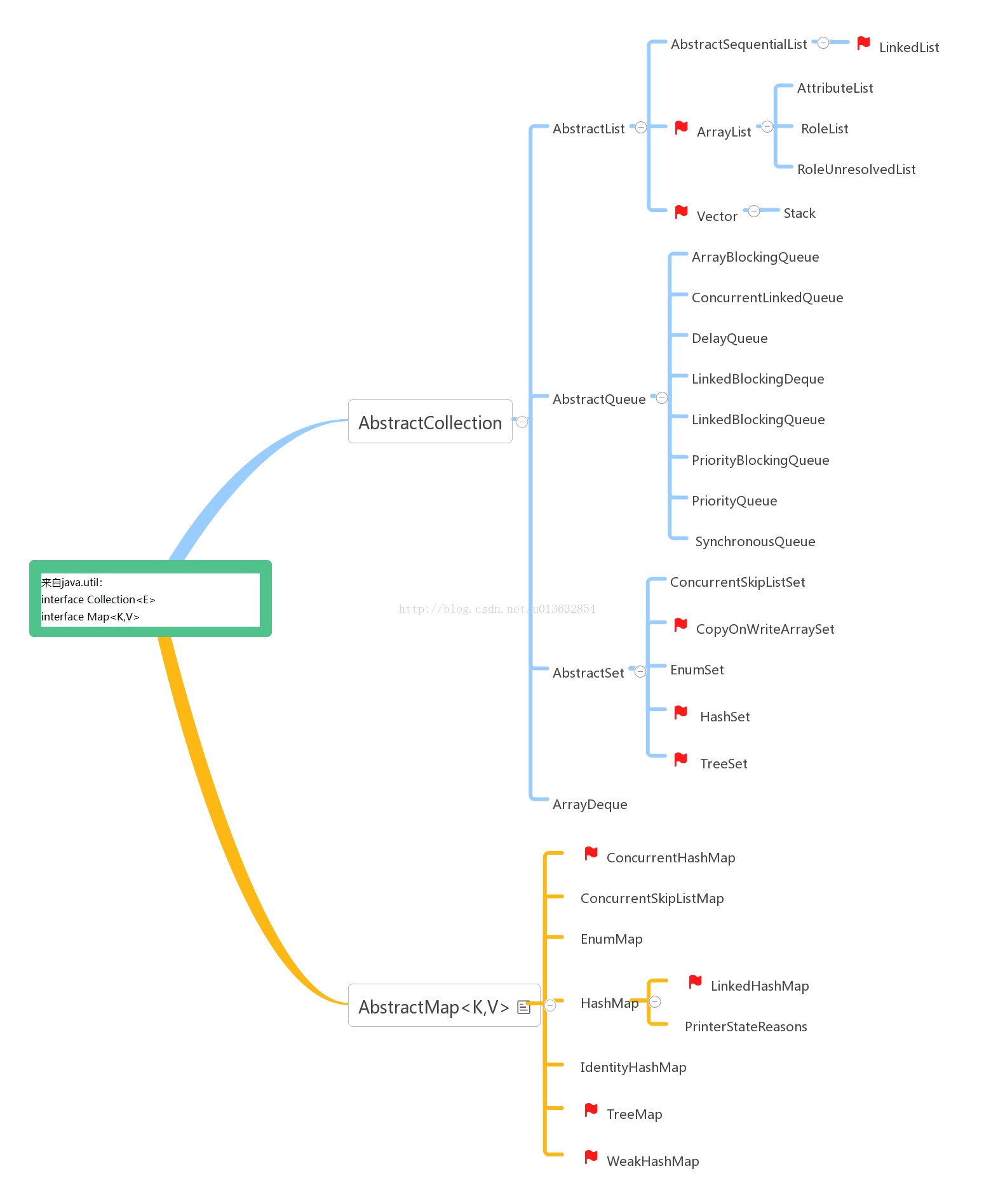
----集合的体系:(根据api1.6继承或实现关系分类)
----常用集合:(从使用的角度分类)
几个接口的特点:
List接口(存储一组不唯一且按插入顺序排序的对象,可以操作索引)
Set接口(存储一组唯一且无序的对象)
Map接口(以键值对的形式存储元素,键是唯一的,也就是key)
1、如果元素可以重复,实现List接口
1)需要查询快
a)线程安全
Vector(由数组实现,访问元素的效率比较高,删除和添加元素效率低,因为要操作大量的元素)
b)线程不安全
ArrayList(由数组实现,访问元素的效率比较高,删除和添加元素效率低,因为要操作大量的元素)
2)需要增删快,
a)线程不安全
LinkedList(由链表实现,插入、删除元素效率比较高,访问效率比较低)
2、如果元素需要唯一不重复,实现Set接口
1)需要查询快,
a)线程不安全
HashSet(由哈希表实现,使用了Hashtable。添加、查询、删除元素的效率都很高,缺点是元素无序。通过hashcode与equals方法确保元素的唯一)
TreeSet(由二叉树实现。查询效率高,且元素有序的。存放自定义类型的对象需要实现 Comparable接口,重写compareTo方法,提供对象排序的方式)
LinkedHashSet(由哈希表实现元素的存储,由链表实现元素的顺序。添加、查询、删除元素的效率都高,且元素是有序的)
2)需要排序,
a)线程不安全
TreeSet
3、通过键值对存取,实现map接口
1)需要查询快,
a)线程不安全
HashMap(由哈希表实现,使用了Hashtable。添加、查询、删除元素的效率都很高)
LinkedHashMap(由哈希表实现元素的存储,由链表实现元素的顺序。添加、查询、删除元素的效率都高,且元素是有序的)
TreeMap(由二叉树实现。查询效率高,且元素有序的。存放自定义类型的对象需要实现 Comparable接口,重写compareTo方法,提供对象排序的方式)
Hashtable( 类实现一个哈希表,该哈希表将键映射到相应的值。任何非 null 对象都可以用作键或值。为了成功地在哈希表中存储和获取对象,用作键的对象必须实现 hashCode 方法和 equals 方法)
这几个也应该了解下:(提高写并发的处理能力,但是弱化了元素读取的一致性)
CopyOnWriteArrayList:http://ifeve.com/java-copy-on-write/
简单理解:多人在操作同一个容器时,每个人修改里面的元素时其实是复制出来一个新的容器 ,然后在新的容器上进行修改,修改完将新的容器赋给原来容器的引用,而这个过程中很多人在同步做读取的动作,但是他们读取的是旧的容器元素,新的内容他们未能取得,这样就读写分离了,不会产生冲突,但是新旧元素不能保持一致。
也可以这样粗糙的理解:我有一批旧的水果,又进了一批新的水果,你却在旧的水果堆里面挑水果来买。
ConcurrentHashMap:http://www.importnew.com/22007.html
词穷.....看上面贴的博客吧,讲得好详细
----收集的一些注意点:
序列化:
大部分的集合实现了序列化的接口,比如ArrayList
comparable、comparator、comparaTo的关系:
public class Test {
public static void main(String[] args) {
Man a = new Man(3);
Man b = new Man(4);
// Comparable是类自己的比较工具
// Man实现了Comparable接口
// 重写了compareTo方法,提供排序的标准
// TreeSet根据要求对存储的元素进行排序
TreeSet<Man> ts = new TreeSet<Man>();
ts.add(a);
ts.add(b);
// 或者是自己使用自己的方法与同类对象进行比较
int compare = a.compareTo(b);
// Comparator是实现一个外部的工具
// 这个是一个比较大小的工具
// 比如比较乐观man之间的年龄大小
CompareTool tool = new CompareTool();
tool.compare(a, b);
}
}
class Man implements Comparable<Man> {
int age;
public Man(int age) {
this.age = age;
}
public int compareTo(Man arg0) {
// 根据业务需求,编写排序的比较方式,比如年龄从大到小
return 0;
}
}
class CompareTool implements Comparator<Man> {
public int compare(Man arg0, Man arg1) {
// 根据业务需求,编写排序的比较方式,比如年龄的比较
return 0;
}
}
hashcode与equals:
HashSet、LinkedHashSet之类的集合,可以按业务需求重写hashcode与equals方法,判断对象的唯一性
public class Test {
public static void main(String[] args) {
HashSet<String> hs = new HashSet<String>() {
@Override
public int hashCode() {
// 按你的业务要求,重写hashCode方法
// 这里是获取对象的特征,用于判断是否有重复对象
return -1;
}
@Override
public boolean equals(Object arg0) {
// 按你的业务要求,重写equals方法
// 这里判断是否是同一个对象
return false;
}
};
}
}
迭代器:
顾名思义,就是获取元素的工具。集合里面的类一般都实现Iterable接口并重写Iterator方法,通过迭代器来操作元素
(List集合特有的迭代器 ,ListIterator ,解决并发修改集合的问题,并且提供了更多操作元素的方法 )
public class Test {
public static void main(String[] args) {
ArrayList<String> arr = new ArrayList<String>();
// 获取迭代器
Iterator it = arr.iterator();
// 查询是否还有内容
if (it.hasNext()) {
// 获取内容
String str = (String) it.next();
}
// list特有的迭代器,线程安全的
ListIterator lit = arr.listIterator();
if (lit.hasNext()) {
String str = (String) lit.next();
}
if (lit.hasPrevious()) {
String str = (String) lit.previous();
}
// set的迭代
HashSet<String> hm = new HashSet<String>();
Iterator ite = hm.iterator();
if (it.hasNext()) {
String str = (String) it.next();
}
// map的迭代
LinkedHashMap<String, String> lhm = new LinkedHashMap<String, String>();
// 要先把map转换为set
Set set = lhm.entrySet();
Iterator sit = set.iterator();
if (sit.hasNext()) {
// 获取内容
String str = (String) sit.next();
}
}
}
泛型:
集合是存储对象的,且都是Object,由于对象具有多态等特点,每次把元素取出肯定是需要向下转型,但是这个要转的类型并不确定,于是这个强转的过程就有出错的可能。那么为了解决这个问题,就需要用到泛型。使用泛型来规定这个集合只能存放某个类型的数据,就不需要关心强转的问题了。
public class Test {
public static void main(String[] args) {
// 创建一个list集合
ArrayList arr = new ArrayList();
// 添加元素
arr.add("hello");
// 获取元素时需要强转
String hello = (String) arr.get(0);
// 如果我强转成一个我自定义的people类,居然也是可以的,这就是潜在的危险
People people = (People) arr.get(0);
// 创建一个带泛型的list集合
ArrayList<String> arr2 = new ArrayList<String>();
// 添加元素
arr2.add("hello");
// 取出元素不需要强转
String hello2 = arr2.get(0);
}
}
----常见面试题:
集合与数组的比较:
数组不够灵活,集合提供了不同的类型来适应不同的场合。具体如下:
1:数组能存放基本数据类型和对象,而集合类中只能存放对象。
2:数组容量固定,集合类容量动态改变。
3:数组无法判断其中实际存有多少元素,length只告诉了数组的容量,而集合的size()可以确切知道元素的个数
4:集合有多种实现方式和不同适用场合,不像数组仅采用顺序表方式
5:集合以类的形式存在,具有封装、继承、多态等类的特性,通过自定义可以满足各种复杂操作,提高开发效率
Collection和Collections的区别:
Collection是集合的顶层接口
Collections是一个专门用来操作集合的工具类,它提供了搜索、排序、线程安全化等操作。
ArrayList和LinkedList的联系和区别:
ArrayList由数组实现,在内存中分配连续空间,遍历元素和随机访问元素效率比较高
LinkedList由链表实现,插入、删除元素效率比较高
Vector和ArrayList的联系和区别:
实现原理相同,功能相同,都是长度可变的数组结构,很多时候可以互用,两者的主要区别如下
Vector是早期的JDK接口,ArrayList是用来替代Vector的
Vector线程安全但低效,ArrayList线程非安全但高效
长度需要增长时,Vector默认增长1倍,ArrayList增长1.5倍
HashMap和Hashtable的联系和区别:
实现原理相同,功能相同,底层都是哈希表结构,查询速度快,在很多情况下可以互用,两者的主要区别如下:
Hashtable是早期的JDK提供的接口,HashMap是新版的JDK提供的接口
Hashtable继承Dictionary类,HashMap实现Map接口
Hashtable是线程安全,HashMap线程非安全
Hashtable不允许null键和值,,HashMap允许null值
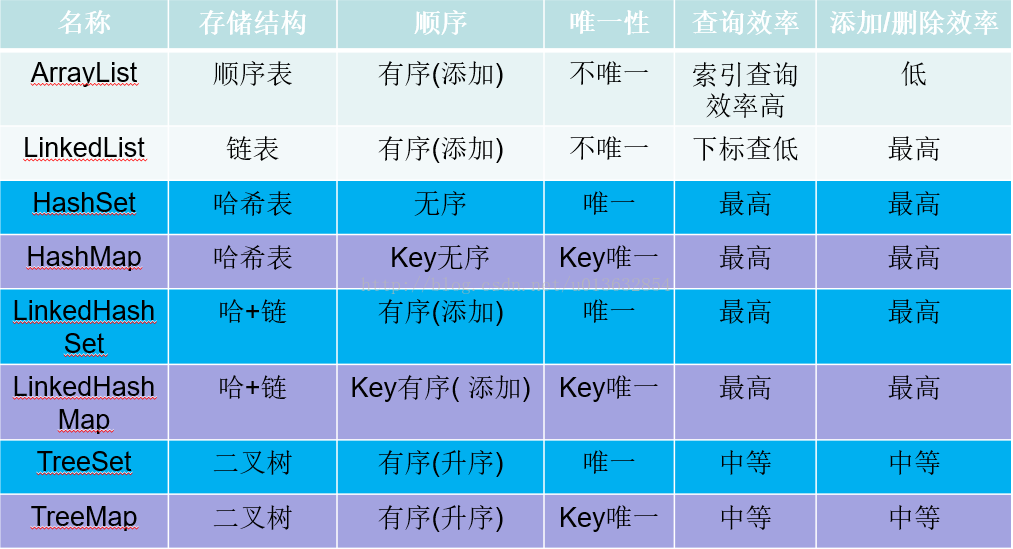
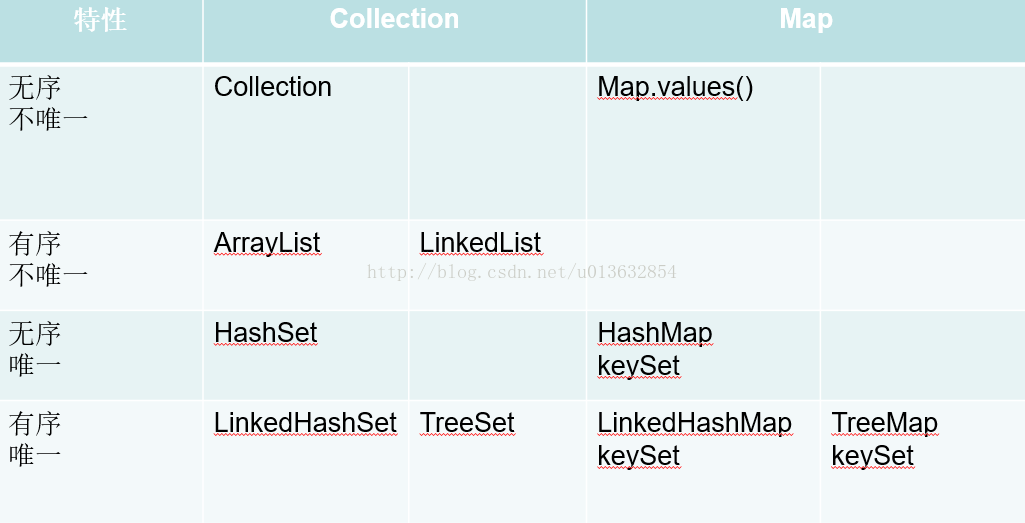
----摘自百度:(两幅图感觉列举得很形象)
行到水穷处,坐看云起时。
中岁颇好道,晚家南山陲。
兴来每独往,胜事空自知。
偶然值林叟,谈笑无还期。


