
013-多线程-基础-Fork/Join框架、parallelStream讲解
一、概述
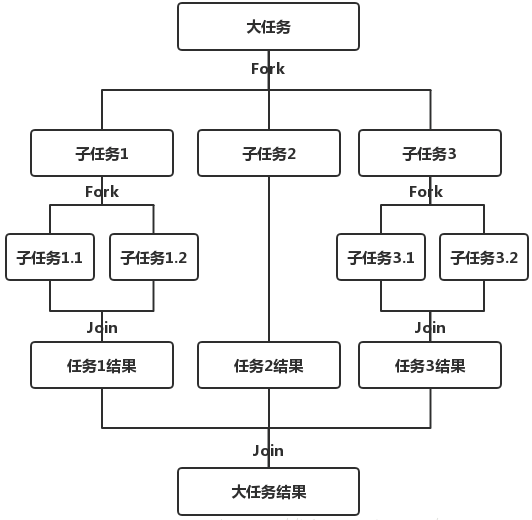
Fork/Join框架是Java7提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
它同ThreadPoolExecutor一样,也实现了Executor和ExecutorService接口。它使用了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入希望的线程数量,那么当前计算机可用的CPU数量会被设置为线程数量作为默认值。
Fork/Join的运行流程如下图所示:
1.1、分治法
ForkJoinPool主要用来使用分治法(Divide-and-Conquer Algorithm)来解决问题。
典型的应用比如快速排序算法。这里的要点在于,ForkJoinPool需要使用相对少的线程来处理大量的任务。比如要对1000万个数据进行排序,那么会将这个任务分割成两个500万的排序任务和一个针对这两组500万数据的合并任务。以此类推,对于500万的数据也会做出同样的分割处理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于10时,会停止分割,转而使用插入排序对它们进行排序。那么到最后,所有的任务加起来会有大概2000000+个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。
所以当使用ThreadPoolExecutor时,使用分治法会存在问题,因为ThreadPoolExecutor中的线程无法像任务队列中再添加一个任务并且在等待该任务完成之后再继续执行。而使用ForkJoinPool时,就能够让其中的线程创建新的任务,并挂起当前的任务,此时线程就能够从队列中选择子任务执行。
那么使用ThreadPoolExecutor或者ForkJoinPool,会有什么性能的差异呢?
首先,使用ForkJoinPool能够使用数量有限的线程来完成非常多的具有父子关系的任务,比如使用4个线程来完成超过200万个任务。但是,使用ThreadPoolExecutor时,是不可能完成的,因为ThreadPoolExecutor中的Thread无法选择优先执行子任务,需要完成200万个具有父子关系的任务时,也需要200万个线程,显然这是不可行的。
1.2、工作窃取算法
forkjoin最核心的地方就是利用了现代硬件设备多核,在一个操作时候会有空闲的cpu,那么如何利用好这个空闲的cpu就成了提高性能的关键,而这里我们要提到的工作窃取(work-stealing)算法就是整个forkjion框架的核心理念,工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
那么为什么需要使用工作窃取算法呢?
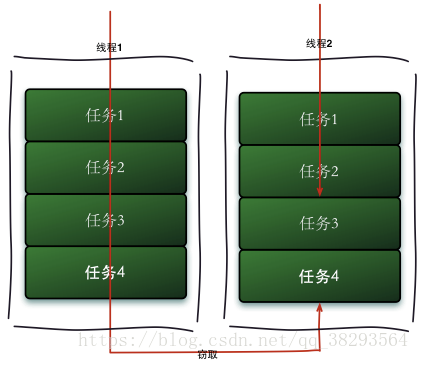
假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取的运行流程图如下:
工作窃取算法的优点:充分利用线程进行并行计算,并减少了线程间的竞争;
工作窃取算法的缺点:在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
二、原理以及主要类
ForkJoinPool: 用来执行Task,或生成新的ForkJoinWorkerThread,执行 ForkJoinWorkerThread 间的 work-stealing 逻辑。ForkJoinPool 不是为了替代 ExecutorService,而是它的补充,在某些应用场景下性能比 ExecutorService 更好。
ForkJoinTask: 执行具体的分支逻辑,声明以同步/异步方式进行执行
ForkJoinWorkerThread: 是 ForkJoinPool 内的 worker thread,执行
ForkJoinTask, 内部有 ForkJoinPool.WorkQueue来保存要执行的ForkJoinTask。
ForkJoinPool.WorkQueue:保存要执行的ForkJoinTask。
2.1、Fork/Join框架的实现原理
在Java的Fork/Join框架中,它提供了两个类来帮助我们完成任务分割以及执行任务并合并结果:
1、ForkJoinTask:我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务中执行fork()和join()操作的机制,通常情况下我们不需要直接继承ForkJoinTask类,而只需要继承它的子类,Fork/Join框架提供了以下两个子类:
RecursiveAction:用于没有返回结果的任务。
RecursiveTask :用于有返回结果的任务。
2、ForkJoinPool :ForkJoinTask需要通过ForkJoinPool来执行,任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成,ForkJoinTask数组负责将存放程序提交给ForkJoinPool,而ForkJoinWorkerThread负责执行这些任务。
基本思想
ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)。
每个工作线程在运行中产生新的任务(通常是因为调用了 fork())时,会放入工作队列的队尾,并且工作线程在处理自己的工作队列时,使用的是 LIFO(后进先出) 方式,也就是说每次从队尾取出任务来执行。
每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务(或是来自于刚刚提交到 pool 的任务,或是来自于其他工作线程的工作队列),窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO 方式。
在遇到 join() 时,如果需要 join 的任务尚未完成,则会先处理其他任务,并等待其完成。
在既没有自己的任务,也没有可以窃取的任务时,进入休眠。
2.1.1、ForkJoinPool属性说明、工作队列说明、控制中心说明
ForkJoinPool里面,有两个特别重要的成员如下:
// Instance fields volatile long ctl; // 控制中心:非常重要,看下图解析 volatile int runState; // 负数是shutdown,其余都是2的次方 final int config; // 配置:二进制的低16位代表 并行度(parallelism), //高16位:mode可选FIFO_QUEUE(1 << 16)和LIFO_QUEUE(1 << 31),默认是LIFO_QUEUE int indexSeed; // 生成worker的queue索引 volatile WorkQueue[] workQueues; // main registry final ForkJoinWorkerThreadFactory factory; final UncaughtExceptionHandler ueh; // per-worker UEH final String workerNamePrefix; // to create worker name string volatile AtomicLong stealCounter; // also used as sync monitor
1、工作队列workQueues
用于保存向ForkJoinPool提交的任务,而具体的执行由ForkJoinWorkerThread执行,而ForkJoinWorkerThreadFactory可以用于生产出ForkJoinWorkerThread:
public static interface ForkJoinWorkerThreadFactory { /** * Returns a new worker thread operating in the given pool. * * @param pool the pool this thread works in * @return the new worker thread * @throws NullPointerException if the pool is null */ public ForkJoinWorkerThread newThread(ForkJoinPool pool); }
队列说明
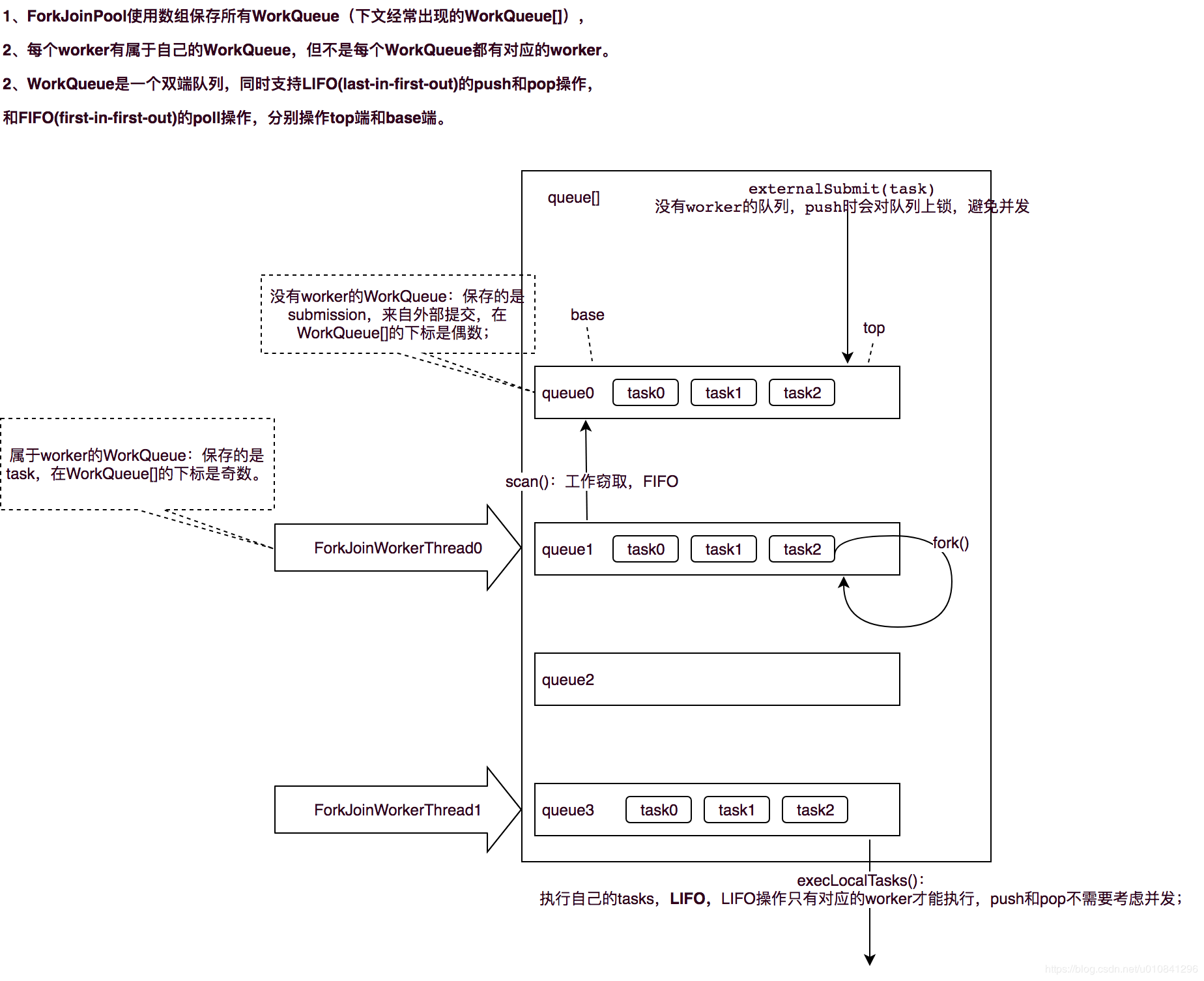
workqueue属性
// Instance fields volatile int scanState; // 负数:inactive, 非负数:active, 其中奇数代表scanning int stackPred; // sp = (int)ctl, 前一个队列栈的标示信息,包含版本号、是否激活、以及队列索引 int nsteals; // 窃取的任务数 int hint; // 一个随机数,用来帮助任务窃取,在 helpXXXX()的方法中会用到 int config; // 配置:二进制的低16位代表 在 queue[] 中的索引, // 高16位:mode可选FIFO_QUEUE(1 << 16)和LIFO_QUEUE(1 << 31),默认是LIFO_QUEUE volatile int qlock; // 锁定标示位:1: locked, < 0: terminate; else 0 volatile int base; // index of next slot for poll int top; // index of next slot for push ForkJoinTask<?>[] array; // 任务列表
2、控制中心ctl

2.1.2、方法说明
队列与关键任务调用说明

1、externalPush || externalSubmit
final void externalPush(ForkJoinTask<?> task) { WorkQueue[] ws; WorkQueue q; int m; //我们以前常用的Random,在并发下,多个线程同时计算种子需要用到同一个原子变量。 //由于更新操作使用CAS,同时执行只有一个线程成功,其他线程的大量自旋造成性能损失,ThreadLocalRandom继承Random,对此进行了改进。 //ThreadLocalRandom运用了ThreadLocal,每个线程内部维护一个种子变量,多线程下计算新种子时使用线程自己的种子变量进行更新,避免了竞争。 int r = ThreadLocalRandom.getProbe(); int rs = runState; // 外部提交的task,肯定会到偶数位下标的队列上 // SQMASK = 0x007e = 1111110,任何数和 SQMASK 进行 & 运算 都会是偶数 if ((ws = workQueues) != null && (m = (ws.length - 1)) >= 0 && (q = ws[m & r & SQMASK]) != null && r != 0 && rs > 0 && //队列上锁 U.compareAndSwapInt(q, QLOCK, 0, 1)) { ForkJoinTask<?>[] a; int am, n, s; if ((a = q.array) != null && (am = a.length - 1) > (n = (s = q.top) - q.base)) { int j = ((am & s) << ASHIFT) + ABASE; //把 task 放到队列的 top端 U.putOrderedObject(a, j, task); U.putOrderedInt(q, QTOP, s + 1); U.putIntVolatile(q, QLOCK, 0); if (n <= 1) signalWork(ws, q); return; } //队列解锁 U.compareAndSwapInt(q, QLOCK, 1, 0); } externalSubmit(task); }
2、registerWorker
final WorkQueue registerWorker(ForkJoinWorkerThread wt) { //...... if ((ws = workQueues) != null && (n = ws.length) > 0) { int s = indexSeed += SEED_INCREMENT; // unlikely to collide int m = n - 1; // worker的queue肯定放在pool中的queue[]中的奇数下标 // m = ws.lenght - 1, ws.lenght 肯定是偶数,则m 肯定是奇数 // 1的二进制位:00000001, 所以任何数 "|" 1 都是奇数 // 所以 奇数 & 奇数 , 1&1 = 1,所以i肯定是奇数 i = ((s << 1) | 1) & m; // odd-numbered indices if (ws[i] != null) { // collision int probes = 0; // step by approx half n int step = (n <= 4) ? 2 : ((n >>> 1) & EVENMASK) + 2; // 如果下标已经有队列,则重新生成奇数下标 // step肯定为偶数:EVENMASK:0xfffe:1111111111111110 // 所以 奇数+偶数,奇偶性不变 while (ws[i = (i + step) & m] != null) { if (++probes >= n) { workQueues = ws = Arrays.copyOf(ws, n <<= 1); m = n - 1; probes = 0; } } } //... } //...... }
3、scan


private ForkJoinTask<?> scan(WorkQueue w, int r) { WorkQueue[] ws; int m; if ((ws = workQueues) != null && (m = ws.length - 1) > 0 && w != null) { int ss = w.scanState; // initially non-negative // k = r & m 。 r是一个随机数,m 是 队列数组长度 - 1;用于定位去哪个 队列 窃取 task for (int origin = r & m, k = origin, oldSum = 0, checkSum = 0;;) { WorkQueue q; ForkJoinTask<?>[] a; ForkJoinTask<?> t; int b, n; long c; if ((q = ws[k]) != null) { // 如果有还没执行的task,尝试窃取队列q 中的base下标的 task。 即FIFO // i: 在内存中,b下标对应的对象的偏移值。 a.length - 1 的二进制位 永远是 0[1...]s,所以 (a.length - 1) & b = b,主要是保证了b不会越界 if ((n = (b = q.base) - q.top) < 0 && (a = q.array) != null) { // non-empty long i = (((a.length - 1) & b) << ASHIFT) + ABASE; if ((t = ((ForkJoinTask<?>) U.getObjectVolatile(a, i))) != null && q.base == b) { // ss 是小偷的 scanState,大于0代表当前的worker是激活的 if (ss >= 0) { // 把 task 从 队列中取出来,然后队列的base+1,如果被窃取的队列中有多于1个的task,则尝试唤醒其他的worker if (U.compareAndSwapObject(a, i, t, null)) { q.base = b + 1; if (n < -1) // signal others signalWork(ws, q); return t; } } // ss小于0代表当前的worker是未激活的,并且当前是第一次扫描,这时候尝试激活worker // oldSum: 上一次遍历周期的 base 值的和。 // (int) c : 可以拿到当前栈顶的空闲worker。sp = (int) c else if (oldSum == 0 && // try to activate w.scanState < 0) tryRelease(c = ctl, ws[m & (int)c], AC_UNIT); } if (ss < 0) // refresh ss = w.scanState; // 更新随机值,重新初始化所有控制变量,重新定位队列 r ^= r << 1; r ^= r >>> 3; r ^= r << 10; origin = k = r & m; // move and rescan oldSum = checkSum = 0; continue; } checkSum += b; } // 每次没有窃取到task的时候,都会k+1(k值不会超过m),当k遍历了一圈还没有steal到任务,则当前小偷worker是过剩的,则inactive这个小偷worker if ((k = (k + 1) & m) == origin) { // continue until stable // oldSum == (oldSum = checkSum) 实际上就是 oldSum == checkSum , oldSum = checkSum // oldSum == checkSum 是判断 这个周期和上个周期 的base和是否一直,如果一直, 说明base可能没有变过 if ((ss >= 0 || (ss == (ss = w.scanState))) && oldSum == (oldSum = checkSum)) { if (ss < 0 || w.qlock < 0) // already inactive break; int ns = ss | INACTIVE; // try to inactivate long nc = ((SP_MASK & ns) | (UC_MASK & ((c = ctl) - AC_UNIT))); // 维护 队列的 stack,可以指向前一个栈顶的队列 w.stackPred = (int)c; // hold prev stack top U.putInt(w, QSCANSTATE, ns); if (U.compareAndSwapLong(this, CTL, c, nc)) ss = ns; else w.scanState = ss; // back out } checkSum = 0; } } } return null; }
4、signalWork
final void signalWork(WorkQueue[] ws, WorkQueue q) { long c; int sp, i; WorkQueue v; Thread p; // AC是负数,所以 active worker不足 while ((c = ctl) < 0L) { // too few active // sp:第一位是0,没有版本号,没有inactive的worker if ((sp = (int)c) == 0) { // no idle workers //tc: tc不为0,就是代表 total worker - parallelism < 0, 所以需要添加worker if ((c & ADD_WORKER) != 0L) // too few workers tryAddWorker(c); break; } if (ws == null) // unstarted/terminated break; // 取栈顶的worker,如果下标已经越界或queue为null,线程池都是终止了 if (ws.length <= (i = sp & SMASK)) // terminated break; if ((v = ws[i]) == null) // terminating break; // 新的scanState,版本+1,设置状态为激活,INACTIVE = 1 << 31,~INACTIVE = 01111111.... int vs = (sp + SS_SEQ) & ~INACTIVE; // next scanState // 确认 worker的 sp没有变化 int d = sp - v.scanState; // screen CAS // 生成新的 ctl,(UC_MASK & (c + AC_UNIT))设置 高32位, (SP_MASK & v.stackPred)设置低32位 long nc = (UC_MASK & (c + AC_UNIT)) | (SP_MASK & v.stackPred); if (d == 0 && U.compareAndSwapLong(this, CTL, c, nc)) { //激活worker v.scanState = vs; // activate v if ((p = v.parker) != null) U.unpark(p); break; } //当前queue没有task 需要执行了,则停止signal if (q != null && q.base == q.top) // no more work break; } }
5、ForkJoinTask的fork方法实现原理
当我们调用ForkJoinTask的fork方法时,程序会把任务放在ForkJoinWorkerThread的pushTask的workQueue中,异步地执行这个任务,然后立即返回结果,代码如下:
public final ForkJoinTask<V> fork() { Thread t; if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ((ForkJoinWorkerThread)t).workQueue.push(this); else ForkJoinPool.common.externalPush(this); return this; }
若当前线程是ForkJoinWorkerThread线程,则强制类型转换(向下转换)成ForkJoinWorkerThread,然后将任务push到这个线程负责的队列里面去,在ForkJoinWorkerThread类中有一个pool和一个workQueue字段:
// 线程工作的ForkJoinPool final ForkJoinPool pool; // the pool this thread works in // 工作窃取队列 final ForkJoinPool.WorkQueue workQueue; // work-stealing mechanics
pushTask方法把当前任务存放在ForkJoinTask数组队列里。然后再调用ForkJoinPool的signalWork()方法唤醒或创建一个工作线程来执行任务。代码如下:
final void push(ForkJoinTask<?> task) { ForkJoinTask<?>[] a; ForkJoinPool p; int b = base, s = top, n; if ((a = array) != null) { // ignore if queue removed int m = a.length - 1; // fenced write for task visibility U.putOrderedObject(a, ((m & s) << ASHIFT) + ABASE, task); U.putOrderedInt(this, QTOP, s + 1); if ((n = s - b) <= 1) { if ((p = pool) != null) p.signalWork(p.workQueues, this); } else if (n >= m) growArray(); } }
该方法的主要功能就是将当前任务存放在ForkJoinTask数组array里。然后再调用ForkJoinPool的signalWork()方法唤醒或创建一个工作线程来执行任务。
6、ForkJoinTask的join方法实现原理
Join方法的主要作用是阻塞当前线程并等待获取结果,其源码如下:
public final V join() { int s; if ((s = doJoin() & DONE_MASK) != NORMAL) reportException(s); return getRawResult(); }
首先,它调用了doJoin()方法,通过doJoin()方法得到当前任务的状态来判断返回什么结果,任务状态有四种:已完成(NORMAL),被取消(CANCELLED),信号(SIGNAL)和出现异常(EXCEPTIONAL):
若状态不是NORMAL,则通过reportException(int)方法来处理状态:
private void reportException(int s) { if (s == CANCELLED) throw new CancellationException(); if (s == EXCEPTIONAL) rethrow(getThrowableException()); }
- 如果任务状态是已完成,则直接返回任务结果。
- 如果任务状态是被取消,则直接抛出CancellationException。
- 如果任务状态是抛出异常,则直接抛出对应的异常。
doJoin()方法的实现代码:
private int doJoin() { int s; Thread t; ForkJoinWorkerThread wt; ForkJoinPool.WorkQueue w; return (s = status) < 0 ? s : ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ? (w = (wt = (ForkJoinWorkerThread)t).workQueue). tryUnpush(this) && (s = doExec()) < 0 ? s : wt.pool.awaitJoin(w, this, 0L) : externalAwaitDone(); }
在doJoin()方法里,首先通过查看任务的状态,看任务是否已经执行完了,如果执行完了,则直接返回任务状态,如果没有执行完,则从任务数组里取出任务并执行。如果任务顺利执行完成了,则设置任务状态为NORMAL,如果出现异常,则纪录异常,并将任务状态设置为EXCEPTIONAL。
执行任务是通过doExec()方法来完成的:
final int doExec() { int s; boolean completed; if ((s = status) >= 0) { try { completed = exec(); } catch (Throwable rex) { return setExceptionalCompletion(rex); } if (completed) s = setCompletion(NORMAL); } return s; }
真正的执行过程是由exec()方法来完成的:
protected abstract boolean exec();
这就是我们需要重写的方法,若是我们的任务继承自RecursiveAction,则我们需要重写RecursiveAction的compute()方法:
public abstract class RecursiveAction extends ForkJoinTask<Void> { private static final long serialVersionUID = 5232453952276485070L; /** * The main computation performed by this task. */ protected abstract void compute(); /** * Always returns {@code null}. * * @return {@code null} always */ public final Void getRawResult() { return null; } /** * Requires null completion value. */ protected final void setRawResult(Void mustBeNull) { } /** * Implements execution conventions for RecursiveActions. */ protected final boolean exec() { compute(); return true; } }
若是我们的任务继承自RecursiveTask,则我们同样需要重写RecursiveTask的compute()方法:
public abstract class RecursiveTask<V> extends ForkJoinTask<V> { private static final long serialVersionUID = 5232453952276485270L; /** * The result of the computation. */ V result; /** * The main computation performed by this task. * @return the result of the computation */ protected abstract V compute(); public final V getRawResult() { return result; } protected final void setRawResult(V value) { result = value; } /** * Implements execution conventions for RecursiveTask. */ protected final boolean exec() { result = compute(); return true; } }
通过上面的分析可知,执行我们的业务代码是在调用了join()之后的,也就是说,fork仅仅是分割任务,只有当我们执行join的时候,我们的任务才会被执行。
2.2、异常处理
ForkJoinTask在执行的时候可能会抛出异常,但是我们没办法在主线程里直接捕获异常,所以ForkJoinTask提供了isCompletedAbnormally()方法来检查任务是否已经抛出异常或已经被取消了,并且可以通过ForkJoinTask的getException方法获取异常。使用如下代码:
if(task.isCompletedAbnormally()){ System.out.println(task.getException()); }
getException方法返回Throwable对象,如果任务被取消了则返回CancellationException。如果任务没有完成或者没有抛出异常则返回null。
public final Throwable getException() { int s = status & DONE_MASK; return ((s >= NORMAL) ? null : (s == CANCELLED) ? new CancellationException() : getThrowableException()); }
2.3、使用
ForkJoinPool 使用submit 或 invoke 提交的区别:invoke是同步执行,调用之后需要等待任务完成,才能执行后面的代码;submit是异步执行,只有在Future调用get的时候会阻塞。
这里继承的是RecursiveTask 适用于有返回值的场景;还可以继承RecursiveAction,适合于没有返回值的场景
执行子任务调用fork方法并不是最佳的选择,最佳的选择是invokeAll方法。
三、示例
3.1、Fork/Join框架应用示例
package com.github.bjlhx15.common.thread.juc.collection; import java.util.Random; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.ForkJoinTask; import java.util.concurrent.RecursiveTask; public class ForkJoinTest { static class SumTask extends RecursiveTask<Long> { static final int THRESHOLD = 100; long[] array; int start; int end; SumTask(long[] array, int start, int end) { this.array = array; this.start = start; this.end = end; } @Override protected Long compute() { if (end - start <= THRESHOLD) { // 如果任务足够小,直接计算: long sum = 0; for (int i = start; i < end; i++) { sum += array[i]; } try { Thread.sleep(1000); } catch (InterruptedException e) { } System.out.println(String.format("compute %d~%d = %d", start, end, sum)); return sum; } // 任务太大,一分为二: int middle = (end + start) / 2; System.out.println(String.format("split %d~%d ==> %d~%d, %d~%d", start, end, start, middle, middle, end)); SumTask subtask1 = new SumTask(this.array, start, middle); SumTask subtask2 = new SumTask(this.array, middle, end); invokeAll(subtask1, subtask2); // subtask1.fork(); // subtask2.fork(); Long subresult1 = subtask1.join(); Long subresult2 = subtask2.join(); Long result = subresult1 + subresult2; System.out.println("result = " + subresult1 + " + " + subresult2 + " ==> " + result); return result; } } public static void main(String[] args) { // 创建随机数组成的数组: long[] array = new long[1000]; fillRandom(array); // fork/join task: ForkJoinPool fjp = new ForkJoinPool(4); // 最大并发数4 ForkJoinTask<Long> task = new SumTask(array, 0, array.length); long startTime = System.currentTimeMillis(); Long result = fjp.invoke(task); long endTime = System.currentTimeMillis(); System.out.println("Fork/join sum: " + result + " in " + (endTime - startTime) + " ms."); } private static void fillRandom(long[] array) { Random random = new Random(); int bound = 100000; for (int i = 0; i < array.length; i++) { array[i] = random.nextInt(bound); } } }
输出结果
split 0~1000 ==> 0~500, 500~1000 split 0~500 ==> 0~250, 250~500 split 500~1000 ==> 500~750, 750~1000 split 0~250 ==> 0~125, 125~250 split 500~750 ==> 500~625, 625~750 split 250~500 ==> 250~375, 375~500 split 750~1000 ==> 750~875, 875~1000 split 0~125 ==> 0~62, 62~125 split 500~625 ==> 500~562, 562~625 split 250~375 ==> 250~312, 312~375 split 750~875 ==> 750~812, 812~875 compute 0~62 = 3185983 compute 750~812 = 3073155 compute 250~312 = 2927391 compute 500~562 = 3086800 compute 312~375 = 3230298 compute 62~125 = 3269295 compute 562~625 = 3113255 result = 2927391 + 3230298 ==> 6157689 compute 812~875 = 3186325 result = 3086800 + 3113255 ==> 6200055 result = 3185983 + 3269295 ==> 6455278 result = 3073155 + 3186325 ==> 6259480 split 375~500 ==> 375~437, 437~500 split 625~750 ==> 625~687, 687~750 split 125~250 ==> 125~187, 187~250 split 875~1000 ==> 875~937, 937~1000 compute 875~937 = 2774271 compute 625~687 = 2874167 compute 375~437 = 3113536 compute 125~187 = 3502959 compute 187~250 = 3098066 compute 687~750 = 2825624 compute 437~500 = 3211442 result = 3113536 + 3211442 ==> 6324978 result = 6157689 + 6324978 ==> 12482667 compute 937~1000 = 3136698 result = 2874167 + 2825624 ==> 5699791 result = 6200055 + 5699791 ==> 11899846 result = 3502959 + 3098066 ==> 6601025 result = 2774271 + 3136698 ==> 5910969 result = 6259480 + 5910969 ==> 12170449 result = 6455278 + 6601025 ==> 13056303 result = 11899846 + 12170449 ==> 24070295 result = 13056303 + 12482667 ==> 25538970 result = 25538970 + 24070295 ==> 49609265 Fork/join sum: 49609265 in 4038 ms.
该代码就是通过Fork/Join框架来计算数组的和,计算耗时4031毫秒。通过该代码作为应用示例主要是为了告诉大家,使用Fork/Join模型的正确方式,在源代码中可以看到,SumTask继承自RecursiveTask,重写的compute方法为:
compute()方法使用了invokeAll方法来分解任务,而不是它下面的subtask1.fork();
这两个方法,使用invokeAll方法的主要原因是为了充分利用线程池,在invokeAll的N个任务中,其中N-1个任务会使用fork()交给其它线程执行,但是,它还会留一个任务自己执行,这样,就充分利用了线程池,保证没有空闲的不干活的线程。
若是采用另外一种方式来运行,程序的运行时间为6028毫秒,可以看到,明显比invokeAll方式慢了很多。
四、JDK 最佳实践
4.1、jdk8 parallelStream
4.1.1、什么是Stream
Stream是java8中新增加的一个特性,被java猿统称为流.
Stream 不是集合元素,它不是数据结构并不保存数据,它是有关算法和计算的,它更像一个高级版本的 Iterator。原始版本的 Iterator,用户只能显式地一个一个遍历元素并对其执行某些操作;高级版本的 Stream,用户只要给出需要对其包含的元素执行什么操作,比如 “过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等,Stream 会隐式地在内部进行遍历,做出相应的数据转换。
Stream 就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。
而和迭代器又不同的是,Stream 可以并行化操作,迭代器只能命令式地、串行化操作。顾名思义,当使用串行方式去遍历时,每个 item 读完后再读下一个 item。而使用并行去遍历时,数据会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。Stream 的并行操作依赖于 Java7 中引入的 Fork/Join 框架(JSR166y)来拆分任务和加速处理过程。Java 的并行 API 演变历程基本如下:
1.0-1.4 中的 java.lang.Thread 5.0 中的 java.util.concurrent 6.0 中的 Phasers 等 7.0 中的 Fork/Join 框架 8.0 中的 Lambda
Stream 的另外一大特点是,数据源本身可以是无限的。
4.1.2、什么是parallelStream
parallelStream其实就是一个并行执行的流.它通过默认的ForkJoinPool,可能提高你的多线程任务的速度.实际是多线程,注意线程安全问题
在从stream和parallelStream方法中进行选择时,我们可以考虑以下几个问题:
1. 是否需要并行?
2. 任务之间是否是独立的?是否会引起任何竞态条件?
3. 结果是否取决于任务的调用顺序? 对于问题1,需要弄清楚要解决的问题是什么,数据量有多大,计算的特点是什么?并不是所有的问题都适合使用并发程序来求解,比如当数据量不大时,顺序执行往往比并行执行更快。毕竟,准备线程池和其它相关资源也是需要时间的。但是,当任务涉及到I/O操作并且任务之间不互相依赖时,那么并行化就是一个不错的选择。通常而言,将这类程序并行化之后,执行速度会提升好几个等级。
对于问题2,如果任务之间是独立的,并且代码中不涉及到对同一个对象的某个状态或者某个变量的更新操作,那么就表明代码是可以被并行化的。
对于问题3,由于在并行环境中任务的执行顺序是不确定的,因此对于依赖于顺序的任务而言,并行化也许不能给出正确的结果。
场景:默认值适用的场景是CPU密集型的,而一般的Web项目是IO密集型的(一般的Web项目都是需要跟数据库打交道的,针对数据库的操作主要就都是IO,而对CPU的消耗并不高)。
当不能使用默认值的时候,需要开发人员额外去了解parallelStream的用法,如下:
4.1.3、parallelStream作用
Stream具有平行处理能力,处理的过程会分而治之,也就是将一个大任务切分成多个小任务,这表示每个任务都是一个操作,因此像以下的程式片段:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.parallelStream()
.forEach(out::println);
得到的展示顺序不一定会是1、2、3、4、5、6、7、8、9,而可能是任意的顺序,就forEach()这个操作來讲,如果平行处理时,希望最后顺序是按照原来Stream的数据顺序,那可以调用forEachOrdered()。例如:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.parallelStream()
.forEachOrdered(out::println);
注意:如果forEachOrdered()中间有其他如filter()的中介操作,会试着平行化处理,然后最终forEachOrdered()会以原数据顺序处理,因此,使用forEachOrdered()这类的有序处理,可能会(或完全失去)失去平行化的一些优势,实际上中介操作亦有可能如此,例如sorted()方法。
4.1.4、通过forkjoin来看parallelStream
在Java 8引入了自动并行化的概念。它能够让一部分Java代码自动地以并行的方式执行,即使用了ForkJoinPool的ParallelStream。
Java 8为ForkJoinPool添加了一个通用线程池,这个线程池用来处理那些没有被显式提交到任何线程池的任务。它是ForkJoinPool类型上的一个静态元素,它拥有的默认线程数量等于运行计算机上的处理器数量。当调用Arrays类上添加的新方法时,自动并行化就会发生。比如用来排序一个数组的并行快速排序,用来对一个数组中的元素进行并行遍历。自动并行化也被运用在Java 8新添加的Stream API中。
一般ForkJoinPool中的通用线程池处理,也可以使用ThreadPoolExecutor完成,但是就代码的可读性和代码量而言,使用ForkJoinPool明显更胜一筹。
4.1.5、线程池数量
1、系统CPU数量:[如机器8核,即8]
Runtime.getRuntime().availableProcessors()
2、parallelStream默认的并发线程数:【parallelStream核心使用ForkJoinPool实现,故如下】【输出是7个】
ForkJoinPool.getCommonPoolParallelism()
3、为什么parallelStream默认的并发线程数要比CPU处理器的数量少1个?
因为最优的策略是每个CPU处理器分配一个线程,然而主线程也算一个线程,所以要占一个名额。如果只有1个CPU,默认的并发线程数就是1
4、修改默认并发数
默认的并发线程数不可以反复修改。因为java.util.concurrent.ForkJoinPool.common.parallelism是final类型的,整个JVM中只允许设置一次。多次修改以第一次为主
1、系统property
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "20");
System.out.println(ForkJoinPool.getCommonPoolParallelism());
2、当然上述参数也可以通过jvm设置系统属性:-Djava.util.concurrent.ForkJoinPool.common.parallelism=N (N为线程数量)
5、既然默认的并发线程数不能反复修改,进行不同线程数量的并发测试,可以引入ForkJoinPool。用法如下:
@Test public void testSetParallelMutli() throws ExecutionException, InterruptedException { int[] threadCountArr = {2, 4, 6}; List<Integer> para = new ArrayList<>(); for (int i = 0; i < 7; i++) { para.add(i); } for (int threadCount : threadCountArr) { new ForkJoinPool(threadCount).submit(() -> {//多线程任务 System.out.println(Thread.currentThread().getName()); }).get(); } }
使用get 是为了阻塞 得到结果;如果主线程没有关闭的情况下可以不用get
4.1.6、示例说明
1、测试一、8核机器,每个任务均耗时2秒,一共16个任务
@Test public void testSetParallelMutli2() throws ExecutionException, InterruptedException { List<Integer> para = new ArrayList<>(); for (int i = 0; i < 16; i++) { para.add(i); } para.parallelStream().forEach(i -> { try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(LocalDateTime.now() + "||" + Thread.currentThread().getName() + ":" + i); }); }
输出
2019-09-13T10:51:04.344||ForkJoinPool.commonPool-worker-1:5 2019-09-13T10:51:04.344||ForkJoinPool.commonPool-worker-6:1 2019-09-13T10:51:04.344||ForkJoinPool.commonPool-worker-2:14 2019-09-13T10:51:04.344||main:10 2019-09-13T10:51:04.344||ForkJoinPool.commonPool-worker-4:13 2019-09-13T10:51:04.344||ForkJoinPool.commonPool-worker-3:2 2019-09-13T10:51:04.344||ForkJoinPool.commonPool-worker-7:4 2019-09-13T10:51:04.344||ForkJoinPool.commonPool-worker-5:7 2019-09-13T10:51:06.350||ForkJoinPool.commonPool-worker-4:3 2019-09-13T10:51:06.350||ForkJoinPool.commonPool-worker-6:0 2019-09-13T10:51:06.350||ForkJoinPool.commonPool-worker-1:12 2019-09-13T10:51:06.350||ForkJoinPool.commonPool-worker-2:15 2019-09-13T10:51:06.350||main:11 2019-09-13T10:51:06.350||ForkJoinPool.commonPool-worker-5:8 2019-09-13T10:51:06.350||ForkJoinPool.commonPool-worker-3:6 2019-09-13T10:51:06.350||ForkJoinPool.commonPool-worker-7:9
结论:会有7个 ForkJoinPool.commonPool-worker 线程和1个主线程main一起执行任务。并且8个一组一组执行,每个线程执行了两个任务。
2、测试二、8核机器,每个任务耗时2秒内随机,一共16个任务
@Test public void testSetParallelMutli2() throws ExecutionException, InterruptedException { List<Integer> para = new ArrayList<>(); for (int i = 0; i < 16; i++) { para.add(i); } para.parallelStream().forEach(i -> { try { // Thread.sleep(2000); Thread.sleep(new Random().nextInt(2000)); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(LocalDateTime.now() + "||" + Thread.currentThread().getName() + ":" + i); }); }
输出
2019-09-13T10:54:01.486||ForkJoinPool.commonPool-worker-5:7 2019-09-13T10:54:01.751||main:10 2019-09-13T10:54:01.774||main:11 2019-09-13T10:54:01.862||ForkJoinPool.commonPool-worker-5:6 2019-09-13T10:54:02.203||ForkJoinPool.commonPool-worker-5:15 2019-09-13T10:54:02.285||ForkJoinPool.commonPool-worker-6:1 2019-09-13T10:54:02.407||ForkJoinPool.commonPool-worker-6:0 2019-09-13T10:54:02.479||ForkJoinPool.commonPool-worker-1:5 2019-09-13T10:54:02.496||ForkJoinPool.commonPool-worker-2:14 2019-09-13T10:54:02.518||ForkJoinPool.commonPool-worker-4:13 2019-09-13T10:54:02.732||main:9 2019-09-13T10:54:02.740||ForkJoinPool.commonPool-worker-7:4 2019-09-13T10:54:02.791||ForkJoinPool.commonPool-worker-3:2 2019-09-13T10:54:03.178||ForkJoinPool.commonPool-worker-5:12 2019-09-13T10:54:03.743||ForkJoinPool.commonPool-worker-1:8 2019-09-13T10:54:04.003||ForkJoinPool.commonPool-worker-6:3
结论:会有7个 ForkJoinPool.commonPool-worker 线程和1个主线程main一起执行任务。并且是强占式【工作窃取法】的执行任务:如上线程5、主线程执行了各3个任务,其他有2个或一个的。
3、示例三、接收消息队列消息,每次消息个数n个,每个消息是一个100个的list<String>,接收时候使用parallelStream消费并发处理
发送消息
@Test public void testMq() throws Exception { for (int j = 0; j < 1; j++) { List<String> list = Lists.newArrayList(); for (int i = 0; i < 100; i++) { list.add(j+"___________"+i); } producerMessageService.sendMessage("test_parallel", UUID.randomUUID().toString(), JSON.toJSONString(list)); Thread.sleep(1000); } logger.error("=======================================================生产 ok"); Thread.sleep(2000000000); }
接收消费
@Override public void onMessage(List<Message> messages) throws Exception { if (messages == null || messages.isEmpty()) { return; } for (int i = 0; i < messages.size(); i++) { Message message = messages.get(i); logger.info(String.format("收到一条消息,消息主题(队列名):%s,内容是:%s", message.getTopic(), message.getText())); List<String> strings = JSONArray.parseArray(message.getText(), String.class); strings.parallelStream().forEach(p -> { try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } logger.error(LocalDateTime.now() + "_______________" + Thread.currentThread().getName() + ":" + p); }); } }
说明:
发送消息,1s后会发送完毕,此时如果有订阅就会出现一条消息积压。
订阅消息者,订阅后会收到词条消息,此时如果正常执行完毕(不论使用不使用多线程)消息积压就没有了,因为一般消息监听会在方法正常执行完毕后,使用消息Id将此条消息从订阅队列中移除。
接收到1条消息,里面会有一个jsonstring,反序列化为List,大小是100,交给parallelStream处理,此时会有8个线程处理【如果是8核机器】,处理速度大约是2秒8个。其余的92进入workQueue中等待处理。
此时如果程序中断,订阅的消息不会被消费使用,下次重连时,需要做已处理消息的去重。
此时如果有新消息发送过来,也会在积压中,不会被消息消费。
4、示例四、从a中100个数找出整除5的
@Test public void testExec() throws ExecutionException, InterruptedException { List<Integer> a = Lists.newArrayList(); for (int i = 0; i < 100; i++) { a.add(i); } List<Integer> b = Lists.newArrayList(); a.parallelStream().forEach(p -> { try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } if (p % 5 == 0) { b.add(p); } }); System.out.println("==========="+b.size()); b.forEach(p -> System.out.print(p+" ")); }
输出:正确应该是20
===========18 15 90 45 30 25 35 85 75 0 40 5 80 95 20 60 70 50 55
对此运行结果不一致,以及会有多线程问题
java.lang.ArrayIndexOutOfBoundsException at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
……
Caused by: java.lang.ArrayIndexOutOfBoundsException: 15 at java.util.ArrayList.add(ArrayList.java:463) at com.github.bjlhx15.common.thread.juc.collection.jdk8stream.TStreamTest.lambda$testExec$6(TStreamTest.java:118) at java.util.stream.ForEachOps$ForEachOp$OfRef.accept(ForEachOps.java:184) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1382) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.ForEachOps$ForEachTask.compute(ForEachOps.java:291)
原因:parallelStream 并行执行,多线程异步,可能没有b添加完毕就遍历,ArrayList不是线程安全的
修正:
方案一、在遍历前,需全部执行完毕【串行】
将 parallelStream 改为 stream串行处理【不可取,处理速度慢】
方案二、在遍历前,需全部执行完毕
继承 RecursiveTask或者RecursiveAction写任务
方案三、将ArrayList替换安全集合CopyOnWriteArrayLIst
List<Integer> b = Lists.newCopyOnWriteArrayList();
此时运行就会出现正确结果。按理说应该会有结果不准确问题吧。但是没有,个人理解,因为是每次8个同时执行,所以即使最后一次主线程提前结束,也有其他线程在锁着b,所以最后执行b的操作会有等待
发的

