
011-数据结构-树形结构-B+树[mysql应用]、B*树
一、B+树概述
B+树是B树的变种,有着比B树更高的查询效率。
一棵 B+ 树需要满足以下条件:
- 节点的子树数和关键字数相同(B 树是关键字数比子树数少一)
- 节点的关键字表示的是子树中的最大数,在子树中同样含有这个数据
- 叶子节点包含了全部数据,同时符合左小右大的顺序
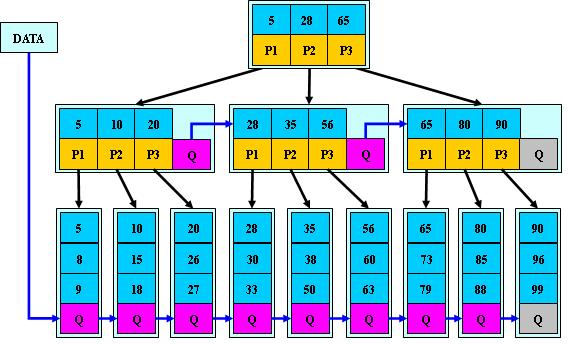
如下图一个M=3 的B+树:
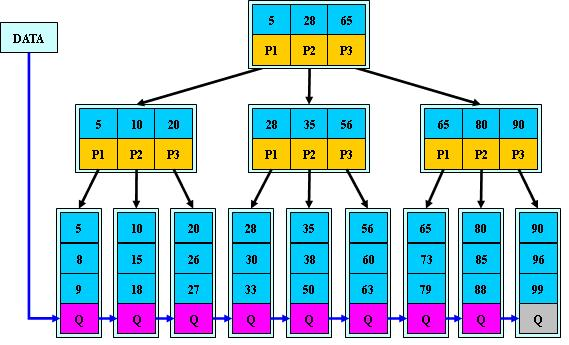
简单概括下 B+ 树的三个特点:
- 关键字数和子树相同
- 非叶子节点仅用作索引,它的关键字和子节点有重复元素
- 叶子节点用指针连在一起
第一点:在 B 树中,节点的关键字用于在查询时确定查询区间,因此关键字数比子树数少一;而在 B+ 树中,节点的关键字代表子树的最大值,因此关键字数等于子树数。
第二点,除叶子节点外的所有节点的关键字,都在它的下一级子树中同样存在,最后所有数据都存储在叶子节点中。根节点的最大关键字其实就表示整个 B+ 树的最大元素。
第三点,叶子节点包含了全部的数据,并且按顺序排列,B+ 树使用一个链表将它们排列起来,这样在查询时效率更快。
由于 B+ 树的中间节点不含有实际数据,只有子树的最大数据和子树指针,因此磁盘页中可以容纳更多节点元素,也就是说同样数据情况下,B+ 树会 B 树更加“矮胖”,因此查询效率更快。
B+ 树的查找必会查到叶子节点,更加稳定。
有时候需要查询某个范围内的数据,由于 B+ 树的叶子节点是一个有序链表,只需在叶子节点上遍历即可,不用像 B 树那样挨个中序遍历比较大小。
B+ 树的三个优点:
- 层级更低,IO 次数更少
- 每次都需要查询到叶子节点,查询性能稳定
- 叶子节点形成有序链表,范围查询方便
1.1、B+树相比B树的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少;
2.所有查询都要查找到叶子节点,查询性能稳定;
3.所有叶子节点形成有序链表,便于范围查询。
代码地址:地址 中的data-004-tree中 BPlusTree
参看地址:
https://blog.csdn.net/u011240877/article/details/80490663
https://blog.csdn.net/qq_33171970/article/details/88395278
1.1、B+树的应用【mysql】
mysql使用B+树作为索引:
B+树相对B树的优点:
①B+树的所有Data域在叶子节点,一般来说都会进行一个优化,就是将所有的叶子节点用指针串联起来,遍历叶子节点就能获取全部数据,这样就能进行区间访问了。
②IO一次读数据是从磁盘上读的,磁盘容量是固定的,取数据量大小是固定的,非叶子节点不存储数据,节点小,磁盘IO次数就少。
1、MYISAM
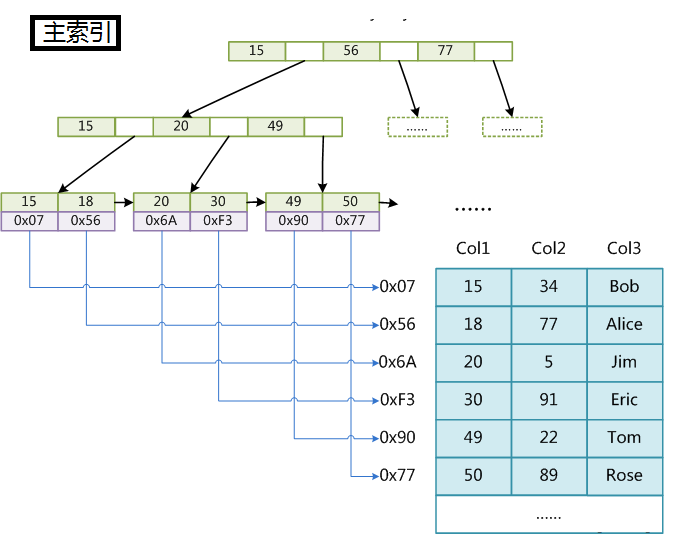

MyISAM中有两种索引,分别是主索引和辅助索引,在这里面的主索引使用具有唯一性的键值进行创建,而辅助索引中键值可以是相同的。MyISAM分别会存一个索引文件和数据文件。它的主索引是非聚集索引。当我们查询的时候我们找到叶子节点中保存的地址,然后通过地址我们找到所对应的信息。
2、INNODB
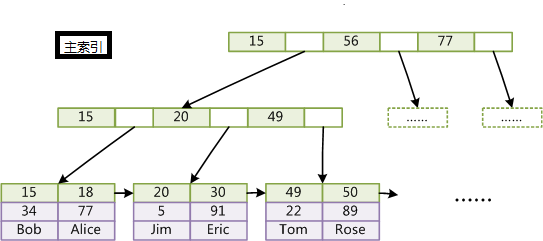
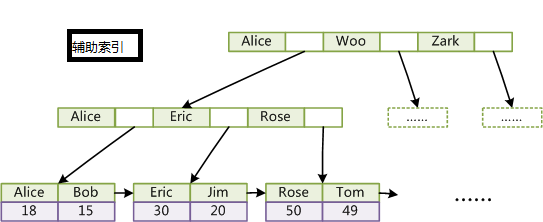
InnoDB索引和MyISAM最大的区别是它只有一个数据文件,在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点数据域保存了完整的数据记录。所以我们又把它的主索引叫做聚集索引。而它的辅助索引和MyISAM也会有所不同,它的辅助索引都是将主键作为数据域。所以,这样当我们查找的时候通过辅助索引要先找到主键,然后通过主索引再找到对于的主键,得到信息。
MyISAM表索引在处理文本索引时更具优势,而INNODB表索引在其它类型上更具效率优势,同时MySQL高并发需要事务场景时,只能使用INNODB表
二、B*树
是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2);
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
代码地址:地址 中的data-004-tree中 BStarTree
三、小结
3.1、对比
二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于走右结点;
B树【B-树】:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;由于B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更近,因此访问也更迅速。
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;
3.2、为什么说B+tree比B树更适合实际应用中操作系统的文件索引和数据库索引?
(1) B+tree的磁盘读写代价更低
B+tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
(2)B+tree的查询效率更加稳定
由于非叶子结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
(3)B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步