

001-分布式理论-CAP定理
一、概述
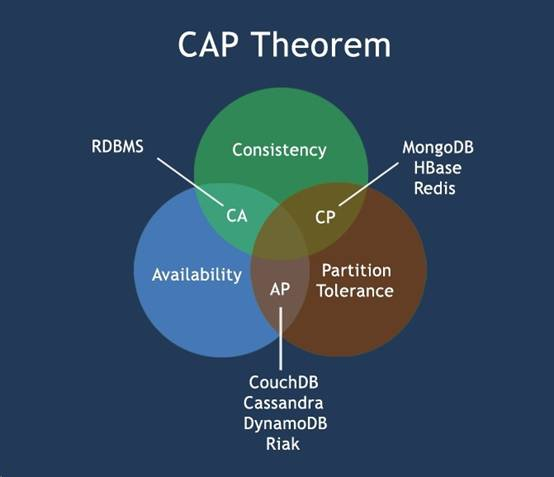
CAP原则又称CAP定理,指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)这三个基本需求,最多只能同时满足其中的2个。
1、cap原则简介
Consistency(一致性) 指数据在多个副本之间能够保持一致的特性(严格的一致性)
Availability(可用性) 指系统提供的服务必须一直处于可用的状态,每次请求都能获取到非错的响应(不保证获取的数据为最新数据)
Partition tolerance(分区容错性) 分布式系统在遇到任何网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务,除非整个网络环境都发生了故障
什么是分区?
在分布式系统中,不同的节点分布在不同的子网络中,由于一些特殊的原因,这些子节点之间出现了网络不通的状态,但他们的内部子网络是正常的。从而导致了整个系统的环境被切分成了若干个孤立的区域,这就是分区。
2、cap权衡
| 选 择 | 说 明 |
| CA | 放弃分区容错性,加强一致性和可用性,其实就是传统的单机数据库的选择 |
| AP | 放弃一致性(这里说的一致性是强一致性),追求分区容错性和可用性,这是很多分布式系统设计时的选择,例如很多NoSQL系统就是如此 |
| CP | 放弃可用性,追求一致性和分区容错性,基本不会选择,网络问题会直接让整个系统不可用 |
对于一个分布式系统而言,分区容错性是一个最基本的要求。因为 既然是一个分布式系统,那么分布式系统中的组件必然需要被部署到不同的节点,否则也就无所谓分布式系统了,因此必然出现子网络。而对于分布式系统而言,网 络问题又是一个必定会出现的异常情况,因此分区容错性也就成为了一个分布式系统必然需要面对和解决的问题。因此系统架构师往往需要把精力花在如何根据业务 特点在C(一致性)和A(可用性)之间寻求平衡。
但是对于涉及到钱财这样不能有一丝让步的场景,C必须保证。网络发生故障宁可停止服务,这是保证CA,舍弃P。还有一种是保证CP,舍弃A,例如网络故障时只读不写。
二、起源
在Towards Robust Distributed Systems 中,CAP理论的提出者Brewer指出:在分布式系统中,计算是相对容易的,真正困难的是状态的维护。那么对于分布式存储或者说数据共享系统,数据的一致性保证也是比较困难的。对于传统的关系型数据库,优先考虑的是一致性而不是可用性,因此提出了事务的ACID特性。而对于许多分布式存储系统,则是更看重可用性而不是一致性,一致性通过BASE(Basically Available, Soft state, Eventual consistency)来保证。下面这张图展示了ACID与BASE的区别:

简而言之:BASE通过最终一致性来尽量保证服务的可用性。注意图中最后一句话“But I think it‘s a spectrum”,就是说ACID BASE只是一个度的问题,并不是对立的两个极端。
2002年,在Brewer's conjecture and the feasibility of consistent, available, partition-tolerant web services中,两位作者通过异步网络模型论证了CAP猜想,从而将Brewer的猜想升级成了理论(theorem)。但实话说,我也没有把文章读得很明白。
2009年的这篇文章brewers-cap-theorem,作者给出了一个比较简单的证明:
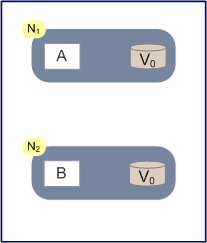
如上图所示,N1,N2两个节点存储同一份数据V,当前的状态是V0。在节点N1上运行的是安全可靠的写算法A,在节点N2运行的是同样可靠的读算法B,即N1节点负责写操作,N2节点负责读操作。N1节点写入的数据也会自动向N2同步,同步的消息称之为M。如果N1,N2之间出现分区,那么就没法保证消息M在一定的时间内到达N2。
从事务的角度来看这各问题

α这个事务由操作α1, α2组成,其中α1是写数据,α2是读数据。如果是单点,那么很容易保证α2能读到α1写入的数据。如果是分布式的情况的情况,除非能控制 α2的发生时间,否则无法保证 α2能读到 α1写入的数据,但任何的控制(比如阻塞,数据集中化等)要么破坏了分区容错性,要么损失了可用性。
另外,这边文章指出很多情况下 availability比consistency重要,比如对于facebook google这样的网站,短暂的不可用就会带来巨大的损失。
2010年的这篇文章brewers-cap-theorem-on-distributed-systems/,用了三个例子来阐述CAP,分别是example1:单点的mysql;example2:两个mysql,但不同的mysql存储不同的数据子集(类似sharding);example3:两个mysql,对A的一个insert操作,需要在B上执行成功才认为操作完成(类似复制集)。作者认为在example1和example2上 都能保证强一致性,但不能保证可用性;在example3这个例子,由于分区(partition)的存在,就需要在一致性与可用性之间权衡。
于我看来,讨论CAP理论最好是在“分布式存储系统”这个大前提下,可用性也不是说整体服务的可用性,而是分布式系统中某个子节点的可用性。因此感觉上文的例子并不是很恰当。
CAP理论发展
从收入目标以及合约规定来讲,系统可用性是首要目标,因而我们常规会使用缓存或者事后校核更新日志来优化系统的可用性。因此,当设计师选择可用性的时候,因为需要在分区结束后恢复被破坏的不变性约。实践中,大部分团体认为(位于单一地点的)数据中心内部是没有分区的,因此在单一数据中心之内可以选择CA;CAP理论出现之前,系统都默认这样的设计思路,包括传统数据库在内。分区期间,独立且能自我保证一致性的节点子集合可以继续执行操作,只是无法保证全局范围的不变性约束不受破坏。数据分片(sharding)就是这样的例子,设计师预先将数据划分到不同的分区节点,分区期间单个数据分片多半可以继续操作。相反,如果被分区的是内在关系密切的状态,或者有某些全局性的不变性约束非保持不可,那么最好的情况是只有分区一侧可以进行操作,最坏情况是操作完全不能进行。
上面摘录中下选线部分跟MongoDB的sharding情况就很相似,MongoDB的sharded cluste模式下,shard之间在正常情况下,是无需相互通信的。
在13年的文章中《better-explaining-cap-theorem》,作者指出“it is really just A vs C!”,因为
(1)可用性一般是在不同的机器之间通过数据的复制来实现
(2)一致性需要在允许读操作之间同时更新几个节点
(3)temporary partion,即几点之间的通信延迟是可能发生了,此时就需要在A 和 C之间权衡。但只有在发生分区的时候才需要考虑权衡。
在分布式系统中,网络分区一定会发生,因此“it is really just A vs C!”
参看地址:
http://www.cnblogs.com/xybaby/p/6871764.html
https://blog.csdn.net/baidu_22254181/article/details/84868709
https://www.infoq.cn/article/cap-twelve-years-later-how-the-rules-have-changed


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2018-02-28 003-CHROME开发者工具的小技巧
2018-02-28 003-Web Worker工作线程