
简学Python第七章__class面向对象高级用法与反射
Python第七章__class面向对象高级用法与反射
欢迎加入Linux_Python学习群
 群号:478616847
群号:478616847
目录:
- Python中关于oop的常用术语
- 类的特殊方法
- 元类
- 反射
一、Python中关于oop的常用术语
抽象/实现
抽象指对现实世界问题和实体的本质表现,行为和特征建模,建立一个相关的子集,可以用于 绘程序结构,从而实现这种模型。抽象不仅包括这种模型的数据属性,
还定义了这些数据的接口。对某种抽象的实现就是对此数据及与之相关接口的现实化(realization)。现实化这个过程对于客户 程序应当是透明而且无关的。
封装/接口
封装描述了对数据/信息进行隐藏的观念,它对数据属性提供接口和访问函数。通过任何客户端直接对数据的访问,无视接口,与封装性都是背道而驰的,除非程序
员允许这些操作。作为实现的 一部分,客户端根本就不需要知道在封装之后,数据属性是如何组织的。在Python中,所有的类属性都是公开的,但名字可能被“混
淆”了,以阻止未经授权的访问,但仅此而已,再没有其他预防措施了。这就需要在设计时,对数据提供相应的接口,以免客户程序通过不规范的操作来存取封装的数
据属性。
注意:封装绝不是等于“把不想让别人看到、以后可能修改的东西用private隐藏起来”真正的封装是,经过深入的思考,做出良好的抽象,给出“完整且最小”
的接口,并使得内部细节可以对外透明(注意:对外透明的意思是,外部调用者可以顺利的得到自己想要的任何功能,完全意识不到内部细节的存在)
合成
合成扩充了对类的 述,使得多个不同的类合成为一个大的类,来解决现实问题。合成 述了 一个异常复杂的系统,比如一个类由其它类组成,更小的组件也可能是
其它的类,数据属性及行为, 所有这些合在一起,彼此是“有一个”的关系。
派生/继承/继承结构
派生描述了子类衍生出新的特性,新类保留已存类类型中所有需要的数据和行为,但允许修改或者其它的自定义操作,都不会修改原类的定义。
继承描述了子类属性从祖先类继承这样一种方式
继承结构表示多“代”派生,可以述成一个“族谱”,连续的子类,与祖先类都有关系。
泛化/特化
基于继承
泛化表示所有子类与其父类及祖先类有一样的特点。
特化描述所有子类的自定义,也就是,什么属性让它与其祖先类不同。
多态与多态性
多态指的是同一种事物的多种状态:水这种事物有多种不同的状态:冰,水蒸气
多态性的概念指出了对象如何通过他们共同的属性和动作来操作及访问,而不需考虑他们具体的类。
冰,水蒸气,都继承于水,它们都有一个同名的方法就是变成云,但是冰.变云(),与水蒸气.变云()是截然不同的过程,虽然调用的方法都一样
自省/反射
自省也称作反射,这个性质展示了某对象是如何在运行期取得自身信息的。如果传一个对象给你,你可以查出它有什么能力,这是一项强大的特性。如果
Python不支持某种形式的自省功能,dir和type内建函数,将很难正常工作。还有那些特殊属性,像__dict__,__name__及__doc__
二、类的特殊方法
1、isinstance和issubclass
isinstance(obj,cls)检查是否obj是否是类 cls 的对象


1 class Foo(object): 2 pass 3 obj = Foo() 4 print(isinstance(obj, Foo))
issubclass(sub, super)检查sub类是否是 super 类的派生类
1 class Foo(object): 2 pass 3 class Test(Foo): 4 pass 5 print(issubclass(Test, Foo))
2、__setattr__,__delattr__,__getattr__
__setattr__只要添加和修改属性就会触发它的运行,可以利用它修改和添加属性
1 class Foo: 2 def __init__(self,y): 3 self.y=y 4 def __setattr__(self, key, value): 5 print('我是 setattr') 6 # self.key=value #这就无限递归了 7 self.__dict__[key]=value #所以应该利用dict 8 9 def func(): 10 print("from aaa") 11 12 #__setattr__添加/修改属性会触发它的执行 13 f1=Foo(10) #在init构造函数中会触发 14 print(f1.__dict__) #输出未赋值的对象dict 15 f1.a=func #赋值 16 print(f1.__dict__)#输出赋值完成的对象dict 17 f1.a() #执行
__delattr__删除属性的时候会触发它,可以利用它来限制哪些属性不能被删除
1 class Foo: 2 x=1 3 def __init__(self,y): 4 self.y=y 5 6 def __delattr__(self, item): 7 print('触发 delattr') 8 if item == "y":return#可以做判断保证一些属性不能被删除 9 self.__dict__.pop(item) 10 11 #实例化 12 f1=Foo(10) 13 14 #__delattr__删除属性的时候会触发 15 f1.__dict__['a']=10#我们可以直接修改属性字典,来完成添加/修改属性的操作 16 print(f1.__dict__) 17 del f1.y 18 print(f1.__dict__)
__getattr__只有在使用点调用不存在的属性时候才会触发
1 class Foo: 2 x=1 3 def __init__(self,y): 4 self.y=y 5 6 def __getattr__(self, item): 7 print('触发 getattr') 8 if item == 'age': 9 return 26 10 else: 11 print("你访问的属性不存在") 12 13 14 #__setattr__添加/修改属性会触发它的执行 15 f1=Foo(10) 16 print(f1.y) 17 18 #__getattr__只有在使用点调用不存在的属性时候才会触发 19 print(f1.age) 20 21 print(f1.test)
3、__getattribute__
这个方法表示只要用点调用就会触发,当_getattribute__与__getattr__同时存在,只会执行__getattrbute__,除非__getattribute__在执行过程中抛出
异常AttributeError
1 class Foo: 2 def __init__(self,x): 3 self.x=x 4 5 def __getattr__(self, item): 6 print('执行的是我') 7 # return self.__dict__[item] 8 def __getattribute__(self, item): 9 print('不管是否存在,我都会执行') 10 raise AttributeError() 11 12 f1=Foo(10) 13 f1.x #存在触发 14 15 f1.test #不存在触发 16 #当__getattribute__与__getattr__同时存在,只会执行__getattrbute__,除非__getattribute__在执行过程中抛出异常AttributeError
4、__getitem__,__setitem__,__delitem__
用于索引操作,如字典。以上分别表示获取、设置、删除数据
1 class Foo(object): 2 def __init__(self,name): 3 self.name = name 4 def __getitem__(self, key): 5 print('getitem',key) 6 7 def __setitem__(self, key, value): 8 print('setitem',key,value) 9 self.__dict__[key]=value 10 11 def __delitem__(self, key): 12 print('delitem',key) 13 # self.__dict__.pop(key) 14 15 obj = Foo("FFF") 16 17 print(obj.__dict__) 18 19 result = obj['k1'] # 获取自动触发执行 __getitem__ 20 obj['name'] = 'test' # 设置自动触发执行 __setitem__ 21 del obj['k1'] # 删除自动触发执行 __delitem__ 22 23 print(obj.__dict__)
5、__str__,__repr__
__str__,在打印对象时触发
1 class Foo: 2 def __str__(self): 3 print("hehe") 4 return 'test' 5 6 obj = Foo() 7 print(obj)
__repr__,事实上repr跟str做了一件事,唯一的区别就是,python说str输出的是对人类友好,repr对机器友好,记不记得第一章中的字符串格式化,就提到了
%s 字符串 (采用str()的显示) %r 字符串 (采用repr()的显示)
1 class Foo(object): 2 def __str__(self): 3 return "str" 4 def __repr__(self): 5 return "repr" 6 7 obj = Foo() 8 print("%s" %obj) 9 print("%r" %obj)
6、__slots__
在python新式类中,从object继承下来的类有一个变量是__slots__,默认情况下每个类都会有一个dict,slots的作用是阻止在实例化类时为实例分配dict,由
__slots__管,目的是节省内存。
1 class Foo: 2 __slots__=['name','age'] 3 4 f1=Foo() 5 f1.name='test' 6 f1.age=22 7 print(f1.__slots__) 8 #这句会报错,原因是没有__dict__ 9 #print(f1.__dict__) 10 11 print(Foo.__dict__)
7、__iter__和__next__
这两个主要是实现迭代器协议的,下面的例子中可以看出,首先执行__iter__,然后返回iter(),iter表示如果传递了第二个参数,则第一个参数必须是一个可调用
的对象(如,函数)。此时,iter创建了一个迭代器对象,用for循环这个迭代器时,都会调用第一个参数。如果__next__的返回值等于第二个值,则停止,否则
返回下一个值,也可以不传入第二个参数,直接返回self,那么在for循环和使用next()的时候就会一直迭代。
1 class Foo(object): 2 def __init__(self): 3 self.x = ["a","b","c"] 4 self.a =1 5 def __iter__(self): 6 print("__iter__") 7 return iter(self.__next__,4) 8 9 def __next__(self): 10 print("__next__") 11 self.a+=1 12 return self.a 13 14 itr = Foo() 15 for i in itr: 16 print(i)
1 class Foo: 2 def __init__(self,x): 3 self.x=x 4 def __iter__(self): 5 return self 6 7 def __next__(self): 8 if self.x == 0: 9 raise StopIteration 10 self.x-=1 11 return self.x 12 13 f1=Foo(5) 14 print(next(f1)) 15 print(next(f1)) 16 for i in f1: 17 print(i)
8、__doc__
返回类的描述信息,这个属性无法继承给子类
1 class Foo: 2 """ 3 Hello 我是描述信息 4 """ 5 def __init__(self): 6 pass 7 8 def test(self): 9 pass 10 11 print(Foo.__doc__)
9、__module__和__class__
__module__表示当前操作的对象在哪个模块,__class__表示当前操作的对象属于哪个类
1 #!/usr/bin/env python 2 3 class Foo(object): 4 5 def __init__(self): 6 self.name = "test"
1 from test2 import Foo 2 3 4 obj = Foo() 5 6 print(obj.__module__) 7 print(obj.__class__)
10、__del__
__del__当对象在内存中被释放时,自动触发执行,也就是说del 删除对象和运行结束释放对象的时候都会执行
1 class Foo: 2 3 def __del__(self): 4 print('执行我啦') 5 6 obj = Foo() 7 obj2 = Foo() 8 9 del obj 10 input(">>>>>>")
11、__enter__和__exit__
我们可以这样操作文件 with open(‘a.txt’) as f ,这叫做上下文管理协议,即with语句,为了让一个对象兼容with语句,必须在这个对象的类中声明__enter__
和__exit__方法。
1 class Open: 2 def __init__(self,name): 3 self.name=name 4 5 def __enter__(self): 6 print('出现with语句,对象的__enter__被触发,有返回值则赋值给as声明的变量') 7 return "test" 8 def __exit__(self, exc_type, exc_val, exc_tb): 9 print('with中代码块执行完毕时执行我啊') 10 11 with Open('a.txt') as f: 12 print('f:',f)
12、__call__
__call__表示生成的对象执行对象()就会触发 call 方法
1 class Foo: 2 3 def __call__(self, *args, **kwargs): 4 print("__call__") 5 6 obj = Foo() 7 obj()
上述方法中其实很多都不常用,只需要了解一下即可
三、元类(metaclass)
什么是元类,在Python中一切皆对象,类本身也是对象当使用关键字class的时候,python解释器在加载class的时候就会创建一个对象(这里的对象指的是类而非类
的实例),我们可以使用type查看元类是谁
1 class Foo: 2 pass 3 print(type(Foo))
什么是元类?
元类就是类的祖宗,也就是类的模板
在这个模板中,定义了python是如何创建类的,并且可以用这个模板创建一个类
1 def func(self,name): 2 print(self) 3 print('from func:',name) 4 5 Foo=type('Foo',(object,),{'func':func,'x':1}) 6 7 obj = Foo() 8 obj.func("test") 9 print(obj.x)
但是感觉上面好像少点什么,是不是没有构造方法
1 def func(self,): 2 print(self) 3 print('from func:',self.name) 4 5 def init(self,name): 6 self.name = name 7 Foo=type('Foo',(object,),{'func':func,'x':1,"__init__":init}) 8 9 obj = Foo("test") 10 obj.func() 11 print(obj.x)
类的创建过程
好到此为止已经可以使用type元类创建一个类了,但是这个类是如果创建的,type创建类过程是什么样子的?
首先要了解为什么会执行 __init__构造方法,__init__之所以被执行,是因为有__new__来去调用它,__new__里面干了就是实例化的过程,当我们创建一个__new__
后就直接执行__new__,我们自己定义的__new__方法中没有实例化的过程所以无法实例化,也不能调用 self.name
1 class Foo(object): 2 def __init__(self,name): 3 self.name = name 4 print("__init__") 5 6 def __new__(cls, *args, **kwargs): 7 print("__new__") 8 9 f = Foo("test") 10 11 #报错 12 #print(f.name)
那么如果用自定义的new进行实例化呢?
首先执行 object.__new__(cls) (cls 就是类的本身),然后触发 init 之后生成一块内存地址,然后通过return赋值给实例 f我们可以打印一下 object.__new__(cls)
的内存地址,和 f的内存地址,它们的地址是一样的。
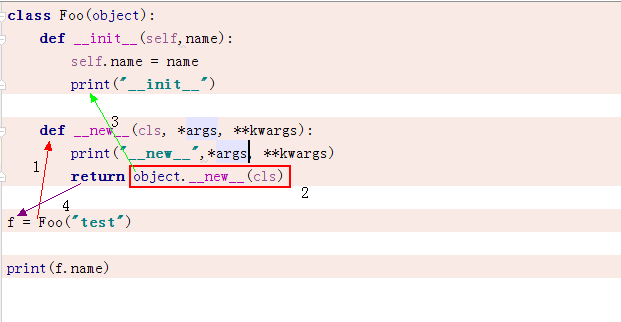
1 class Foo(object): 2 def __init__(self,name): 3 self.name = name 4 print("__init__") 5 6 def __new__(cls, *args, **kwargs): 7 print("__new__",*args, **kwargs) 8 return object.__new__(cls) 9 10 f = Foo("test") 11 12 print(f.name)
到现在我们知道了通过 new 调用 init 然后生成内存空间,赋值给实例,那么这个过程我们是可以控制的,看下面的例子
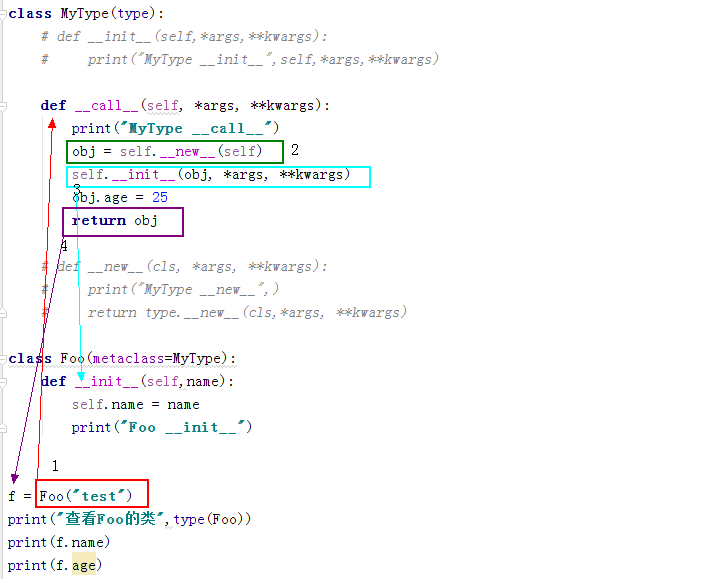
1、首先通过 class Foo (metaclass=MyType) metaclass指定元类是MyType
2、然后Mytype 创造出Foo这个类对象,创造过程就是先执行 MyType 的 new 然后执行 init
3、然后 Foo(“test”) 就执行了 MyType 的 call方法,在call方法中来定义,Foo实例化的过程,(可以把注释的地方解开)
4、这个过程首先通过 Foo的new方法创造实例的内存空间,又执行了obj.age = 22 进行了赋值(这里为了体现f.age),然后执行Foo的 init 进行实例化
5、最后通过return 把创造出来的实例的内存空间,返回给 f,这时f就是Foo的实例,(如果不明白可以加断点走一变)
1 class MyType(type): 2 # def __init__(self,*args,**kwargs): 3 # print("MyType __init__",self,*args,**kwargs) 4 5 def __call__(self, *args, **kwargs): 6 print("MyType __call__") 7 obj = self.__new__(self) 8 self.__init__(obj, *args, **kwargs) 9 obj.age = 25 10 return obj 11 12 # def __new__(cls, *args, **kwargs): 13 # print("MyType __new__",) 14 # return type.__new__(cls,*args, **kwargs) 15 16 class Foo(metaclass=MyType): 17 def __init__(self,name): 18 self.name = name 19 print("Foo __init__") 20 21 22 f = Foo("test") 23 print("查看Foo的类",type(Foo)) 24 print(f.name) 25 print(f.age)
到此我们演示了 类的创建过程,具体有什么用,到后期会一一揭开
四、反射
反射的概念是由Smith在1982年首次提出的,主要是指程序可以访问、检测和修改它本身状态或行为的一种能力(自省)。这一概念的提出很快引发了计算机科学
领域关于应用反射性的研究。它首先被程序语言的设计领域所采用,并在Lisp和面向对象方面取得了成绩。
反射就是通过类名获得类的实例对象(一切皆对象,所以只要是对象就能用反射),通过方法名得到方法,实现调用,在python中反射功能是由四个内置函数提供的
- hasattr 是否含有某成员
- getattr 获取成员
- setattr 设置成员
- delattr 删除成员
1 class Foo(object): 2 3 def __init__(self): 4 self.name = 'test' 5 6 def func(self): 7 print("func") 8 return 'func' 9 10 obj = Foo() 11 12 #### 检查是否含有成员 #### 13 print(hasattr(obj, 'name')) 14 print(hasattr(obj, 'aaa')) 15 16 #### 获取成员 #### 17 print(getattr(obj, 'name')) 18 getattr(obj, 'func')() 19 20 #### 设置成员 #### 21 setattr(obj, 'age', 18) 22 23 #### 删除成员 #### 24 print(obj.__dict__) 25 #注意哦,这里不能删除 func 这个方法,因为在 obj中没有这个方法,这个方法是在 Foo中的 26 delattr(obj, 'name') 27 print(obj.__dict__)
作者:北京小远
出处:http://www.cnblogs.com/bj-xy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号