
简学Python第二章__巧学数据结构文件操作
Python第二章__巧学数据结构文件操作
欢迎加入Linux_Python学习群
 群号:478616847
群号:478616847
目录:
- 列表
- 元祖
- 索引
- 字典
- 序列
- 文件操作
- 编码与文件方法
本站开始将引入一个新的概念:数据结构,简答的说数据结构就是将数据元素或者其他数据结构集合到一起称之为数据结构,
常见的数据结构有 列表,元祖,字典,集合,它们有个别名叫做序列,序列是Python中最基本的数据结构,下面我们一一揭秘这些数据结构。
一、索引
什么是索引?
索引的意思很简单,在字符串或者序列中每一个元素Python都给了它们一个编号,那么通过这个编号可以取到对应的元素,我们把这个编号叫做索引,请看下面实例
Pythron中索引的规则是从0开始的,也就是序列或者字符串中第一个元素的下标是0,第二个是1,第三个是2,最后一个可以用-1表示


1 >>> strs = "abcdefg" 2 >>> strs[0] 3 'a' 4 >>> strs[1] 5 'b' 6 >>> strs[-1] 7 'g'
分片
分片的意思就是通过索引下标取得一段元素,其中在第一个分片的例子中可以看出,分片取得是0下标位到3下标位的数据但不包括3下标位,所以因为这种特性我们取出的数据就是三个
既012下标位的数据也就是123,第二个例子和第三个例子表示了想要从开头或者结尾分片的时候,开头或者结尾可以不写。
1 >>> a = "12345678" 2 >>> a[0:3] 3 '123' 4 >>> a[:3] 5 '123' 6 >>> a[6:] 7 '78' 8 >>> a[6:-1] 9 '7'
其中分片我们也可以跳着取数据,这里我们称之为步长,当步长为1的时候其实没有实际意义,因为取出的值还是原来的,当步长等于2的时取得就是奇数位的数据了,当步长为负数的时候则是从后往前
1 >>> a[0::1] 2 '1' 3 >>> a[0::2] 4 '1357' 5 >>> a[::-1] 6 '87654321' 7 >>> a[::-2] 8 '8642'
二、列表(List)
列表是最常用的Python数据类型,它可以存储很多元素,每个元素以逗号进行分割,并且每个元素我们都可以进行更改,也可以添加删除数据。
list函数
list函数可以把字符串或者其他序列转换成列表
1 >>> a = "abcd" 2 >>> list(a) 3 ['a', 'b', 'c', 'd']
基本的列表操作
想要访问列表中的元素我们可以通过索引取出,也可以通过for循环遍历列表中所有的元素
1 >>> a = ["a","b","c","d"] 2 >>> a[1] 3 'b' 4 >>> for i in a: 5 ... print(i) 6 ... 7 a 8 b 9 c 10 d
常用的内置函数方法
1 lists = ["a","b","c","d","e",] 2 3 #添加 4 lists.append("f") 5 print(lists) 6 7 #删除列表中的元素 8 del(lists[0])#等于lists.__delitem__(1) 9 del(lists[2:4])#删除序列片段 10 lists.remove("b") 11 print(lists) 12 13 #更改列表中的元素 14 lists = ["a","b","c","d","e",] 15 lists[2] = "C" 16 print(lists) 17 18 #判断序列的长度 19 print(len(lists)) 20 21 #获取元素大小,单位字节 22 print(lists.__sizeof__()) 23 24 #搜索列表中某个元素出现的次数 25 lists = ["a","b","c","d","c",] 26 print(lists.count("c")) 27 28 #查找某个元素第一次出现的下标 29 print(lists.index("c")) 30 31 #把元素插入到指定下标位置 32 print(lists[2]) 33 lists[2] = "C" 34 print(lists[2]) 35 36 #删除指定下标位的元素,并返回元素,如果不指定下标默认删除最后一个,并返回元素 37 print(lists) 38 c = lists.pop() 39 print(c) 40 c = lists.pop(1) 41 print(c) 42 print(lists) 43 44 #列表倒叙 45 lists = ["a","b","c","d"] 46 lists.reverse() 47 print(lists) 48 49 #按照大小排序,字符串比较unicode值 50 lists = ["c","b","a","d","2","1"] 51 lists.sort() 52 print(lists) 53 54 #__add__加 55 lists = ["a","b","c"] 56 test = ["d"] 57 lists = lists+test#其中的+号就是调用的__add__所以这样写也是可以的lists = lists.__add__(test) 58 print(lists) 59 60 #包含,查看列表是否包含某个元素,返回布尔值 61 print(lists.__contains__("a"))#同等于lists in "a" 62 63 #合并列表 64 lists = ["a","b"] 65 test = ["c","d"] 66 lists.extend(test) 67 print(lists) 68 69 #将列表中的元素以指定分隔符拼接成字符串 70 print("_".join(lists))
深浅copy
我们知道在列表中可以把其它序列作为元素,看下面代码我们可以发先 list1等于一个列表,list2等于list1那么list1中的任何改变list2也会改变
1 >>> list1 = ["1","2",["a","b","c"],"3"] 2 >>> list2 = list1 3 >>> print("list1:",list1) 4 list1: ['1', '2', ['a', 'b', 'c'], '3'] 5 >>> print("list2:",list2) 6 list2: ['1', '2', ['a', 'b', 'c'], '3'] 7 >>> list1[0] = "11" 8 >>> print("list1:",list1) 9 list1: ['11', '2', ['a', 'b', 'c'], '3'] 10 >>> print("list2:",list2) 11 list2: ['11', '2', ['a', 'b', 'c'], '3'] 12 >>> list1[2][0] = "A" 13 >>> print("list1:",list1) 14 list1: ['11', '2', ['A', 'b', 'c'], '3'] 15 >>> print("list2:",list2) 16 list2: ['11', '2', ['A', 'b', 'c'], '3']
通过id()我们可以得到变量的内存地址,我们发现list1和list2的内存地址是一样的,包括其中的列表的那个元素也是一样的,所以修改list1的数据list2也会更改
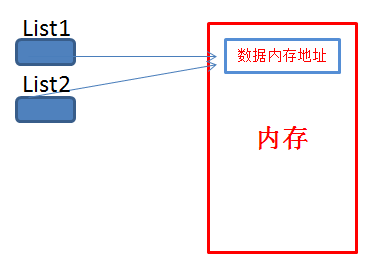
浅拷贝
下面的代码我们发现,浅拷贝的时候,list1和list2的内存地址是不同的,但是更改list1中的列表元素,list2列表也跟着改变,这说明了,浅拷贝无法拷贝列表中的列表或序列元素
1 >>> import copy 2 >>> 3 >>> list1 = ["1","2",["a","b","c"],"3"] 4 >>> list2 = copy.copy(list1) 5 >>> print(id(list1),id(list2)) 6 8996584 7019896 7 >>> print(id(list1[2]),id(list2[2])) 8 8997184 8997184 9 >>> list1[2][0] = "A" 10 >>> print(list1) 11 ['1', '2', ['A', 'b', 'c'], '3'] 12 >>> print(list2) 13 ['1', '2', ['A', 'b', 'c'], '3'] 14 >>> list1[1] = "5" 15 >>> print(list1) 16 ['1', '5', ['A', 'b', 'c'], '3'] 17 >>> print(list2) 18 ['1', '2', ['A', 'b', 'c'], '3']

深拷贝
深拷贝就是把所有的元素都复制了一份,所以对于list1和list2都是独立的,所以它们的内存地址都是不同的
1 >>> import copy 2 >>> 3 >>> list1 = ["1","2",["a","b","c"],"3"] 4 >>> list2 = copy.deepcopy(list1) 5 >>> print(id(list1),id(list2)) 6 6414784 8996584 7 >>> print(id(list1[2]),id(list2[2])) 8 7019256 8997224 9 >>> list1[2][0] = "A" 10 >>> print(list1) 11 ['1', '2', ['A', 'b', 'c'], '3'] 12 >>> print(list2) 13 ['1', '2', ['a', 'b', 'c'], '3'] 14 >>> list1[1] = "5" 15 >>> print(list1) 16 ['1', '5', ['A', 'b', 'c'], '3'] 17 >>> print(list2) 18 ['1', '2', ['a', 'b', 'c'], '3']
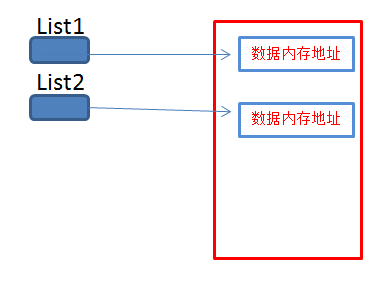
三、元祖(tuple)
什么是元祖?元祖跟列表的区别就是元祖无法做任何的修改,所以元祖所保存的数据都是不可更改的
元祖的常用操作
元祖的基本操作除了创建元组和访问元组元素之外,也没有太多其他操作,在下面可以看出元祖中的序列元素是可以修改的,除此之外元祖也支持,索引、切片、循环、长度、包含的操作
1 tuples = ("a","b","c","d","e") 2 print(tuples[0]) 3 print(tuples[2:]) 4 #某个元素出现的次数 5 tuples.count("a") 6 #找到指定元素的下标 7 tuples.index("d") 8 #转换成列表 9 list(tuples) 10 #字典中的系列不继承元祖不可修改的特点 11 tuples = ("a",[1,2,3]) 12 tuples[1][1] = "a" 13 print(tuples)
四、字典(dict)
字典这种数据类型就类似于我们上学时候用的字典,通过目录查到对应内容的页数
字典的语法: 变量名 = {key:value} 其中的key必须是唯一的
字典由多个键及与其对应的值构成的对组成(我们也把键/值对称为项)每个键和它的值之间用冒号<:)隔开,项之间用逗号(,)隔开, 而整个字典是由一对大括号括起来。
fdict = dict((['x', 1], ['y', 2])) 通过这样的方法可以把列表转换成字典
1 dicts = { 2 "1":"a", 3 "2":"b", 4 "3":"c", 5 "4":"d", 6 }
字典的无序
我们可以发现,不管是元祖还是列表,我们在打印它的时候可以发现,它们元素的顺序是创建时的顺序,然而字典则是没有顺序的
内部原因:
在python中字典是唯一的映射类型,在python内部中将字典的Key计算成哈希值来进行存储,那么存储众多哈希值的表叫做哈希表,这也是为什么字典中的key是唯一的,
哈希表主要是对键执行一个叫做哈希函数的操作,并根据计算的结果,选择在数据结构的某个地址中来存储你的值。任何一个值存储的地址皆取决于它的键。正因为这种随意性,
哈希表中的值是没有顺序的.
在这种映射关系中我们就不会用到序列化排序,不会用到排序意味着针对字典python无序维护类似列表元祖的位置表
1 >>> dicts = {"aa":"a","11":"1","bb":"b","22":"2",} 2 >>> print(dicts) 3 {'22': '2', '11': '1', 'aa': 'a', 'bb': 'b'}
字典的常用操作
#字典的无序 dicts = {"a":"1","b":"2","c":"3","d":"4","e":"5",} print(dicts) #取出key对应的值(value) print(dicts["a"]) #返回key的值,如果存在则返回值,否则返回None print(dicts.get("s")) #setdefault具有与get方法类似的行为,如果传入的key存在则返回对应的value,如果不存在则会在字典中,将会添加键并将值设为默认值(None) print(dicts.setdefault("2")) print(dicts) #取出字典中所有的key print(dicts.keys()) #取出字典中所有的值(value) print(dicts.values()) #向字典添加键值对 dicts["f"] = "6" print(dicts) #更改对应key的value值 dicts["f"] = "f" print(dicts) #更新,将传入的字典添加到原字典中,如果有重名将会被覆盖 b = {"1":1} dicts.update(b) print(dicts) #删除键值对 del dicts["f"] print(dicts) #删除键值对 dicts.pop("d") print(dicts) #随机返回并删除字典中的最后一对键和值,并把删除的键值对返回一个元祖如字典为空,则返回KeyError异常 rm_data = dicts.popitem() print(dicts) print(rm_data) #返回一个由元组构成的列表,每个元组包含一对键-值对 print(dicts.items()) #创建并返回字典的浅拷贝 new_dict = dicts.copy() print(new_dict) #从字典删除所有项 new_dict.clear() print(new_dict) #通过一个列表生成默认dict test = {} print(test.fromkeys([1,2,3],'test'))
循环字典
1 #方法1 2 dicts = {"a":"1","b":"2","c":"3","d":"4","e":"5",} 3 for key in dicts: 4 print(key,dicts[key]) 5 6 #方法2 7 for k,v in dicts.items(): #会先把dict转成list,数据里大时莫用 8 print(k,v)
只循环字典的key或者value
1 #只循环key 2 dicts = {"a":"1","b":"2","c":"3","d":"4","e":"5",} 3 for key in dicts.keys(): 4 print(key) 5 6 #只循环value 7 for v in dicts.values(): 8 print(v)
五、集合(set)
把由不同的元素组成的类型叫做集合,集合是一个无序的,不重复的数据组合,和其他容器类型一样,集合支持用 in 和 not in 操作符检查成员,也指出长度的操作,但不支持索引!
它的主要作用有两点1、去重,把一个列表变成集合,就自动去重了,2、关系测试,测试两组数据之前的交集、差集、并集等关系
python中几个的表现形式 sets = {1,2,3,4}
集合的常用操作
1 #创建一个数值集合 2 s = set([3,5,9,10]) 3 #创建一个唯一字符的集合 4 t = set("Hello") 5 # t 和 s的并集 6 a = t | s 7 # t 和 s的交集 8 b = t & s 9 # 求差集(项在t中,但不在s中) 10 c = t – s 11 # 对称差集(项在t或s中,但不会同时出现在二者中) 12 d = t ^ s 13 14 基本操作: 15 16 # 添加一项 17 t.add('x') 18 # 在s中添加多项 19 s.update([10,37,42]) 20 21 #使用remove()可以删除一项: 22 t.remove('H') 23 24 #set 的长度 25 len(s) 26 27 #测试 x 是否是 s 的成员 28 x in s 29 30 #测试 x 是否不是 s 的成员 31 x not in s 32 33 #测试是否 s 中的每一个元素都在 t 中 34 s.issubset(t) 35 s <= t 36 37 #测试是否 t 中的每一个元素都在 s 中 38 s.issuperset(t) 39 s >= t 40 41 #返回一个新的 set 包含 s 和 t 中的每一个元素 42 s.union(t) 43 s | t 44 45 #返回一个新的 set 包含 s 和 t 中的公共元素 46 s.intersection(t) 47 s & t 48 49 #返回一个新的 set 包含 s 中有但是 t 中没有的元素 50 s.difference(t) 51 s - t 52 53 #返回一个新的 set 包含 s 和 t 中不重复的元素 54 s.symmetric_difference(t) 55 s ^ t 56 57 #返回 set “s”的一个浅复制 58 s.copy()
六、文件操作
打开文件
你必须先用Python内置的open()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。
语法:object = open(file_name [, access_mode][, buffering])
例子:
我们发现,当我们想print出foo时返回的并不是文件中的数据,我们把foo的值称之为文件句柄,我们对文件的操作都是通过文件句柄来实现的。
1 #foo是创建的对象,userdata.txt是要打开的文件名,"r"是打开文件的方法,打开文件有多种方法,详见下面表格 2 3 >>> foo = open(r”data\userdata.txt','r') 4 >>> print(foo) 5 <_io.TextIOWrapper name='data\\userdata.txt' mode='r' encoding='cp936'>
文件操作的模式

"+" 表示可以同时读写某个文件,"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用 rU,r+U),"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件)
文件读写操作
文件读操作
在读操作的时候有三个方法来进行读取,分别是read(),readline(),readlines(),
read方法将读取文件的所以内容,readlines()读取文件所以内容,并处理成列表,readline()读取一行内容,在效率方面readlines,和read是速度快的,readline因为是一行一行
读取文件内容所以速度较慢,但是节省内存!我们可以看到通常情况下用readline进行文件操作都是用while循环进行的,而readlines和read,用for循环即可
其中我们发现fo.seek(0, 0)它的作用是把文件指针定位到开头,更多知识点请看文件指针
1 foo = open('userdata.txt','r',encoding="utf-8") 2 #读取一行,每次只读取一行 3 print(foo.readline()) 4 5 使用readline()对文件操作 6 # while True: 7 # line = foo.readline() 8 # if not line: break 9 # if 条件 in line: 10 # xxx操作 11 # foo.close() 12 13 #自动将文件内容分析成一个行的列表 14 print(foo.readlines()) 15 #将指针重新定位到文件开头 16 foo.seek(0, 0) 17 #读取剩下的所有内容,文件大时不要用 18 print(foo.read()) 19 #关闭文件 20 foo.close()
我们提到,当遇到大文件的时候建议使用readline,但是需要通过while循环,这时我们可以通过内置模块fileinput来进行for循环,这种方法称之为懒惰行选代
默认格式:fileinput.input (files=None, inplace=False, backup='', bufsize=0, mode='r', openhook=None)
files: #文件的路径列表,默认是stdin方式,多文件['1.txt','2.txt',...] inplace: #是否将标准输出的结果写回文件,默认不取代 backup: #备份文件的扩展名,只指定扩展名,如.bak。如果该文件的备份文件已存在,则会自动覆盖。 bufsize: #缓冲区大小,默认为0,如果文件很大,可以修改此参数,一般默认即可 mode: #读写模式,默认为只读 openhook: #该钩子用于控制打开的所有文件,比如说编码方式等;
在下面例子中openhook=fileinput.hook_encoded("utf-8")是为了解决编码问题告诉fileinput我的文件是utf-8的编码格式,更多知识点请看编码与解码
1 import fileinput 2 3 for line in fileinput.input(r'userdata.txt',openhook=fileinput.hook_encoded("utf-8")): 4 print(line) 5 6 7 常用方法: 8 fileinput.input() #返回能够用于for循环遍历的对象 9 fileinput.filename() #返回当前文件的名称 10 fileinput.lineno() #返回当前已经读取的行的数量(或者序号) 11 fileinput.filelineno() #返回当前读取的行的行号 12 fileinput.isfirstline() #检查当前行是否是文件的第一行 13 fileinput.isstdin() #判断最后一行是否从stdin中读取 14 fileinput.close() #关闭队列
文件写操作
我们发现在write操作的时候字符串后面都加了一个\n,其中的原因是我们在写的时候python不会分辨哪些内容是一行的,所以我们需要加\n进行换行
1 #w,与w+方法会覆盖原文件的内容,他俩的区别是w+可以读 2 foo = open('userdata.txt','w',encoding="utf-8") 3 foo.write("Helloworld\n") 4 foo.close() 5 6 #a,与a+都是用于追加的 7 foo = open('userdata.txt','a+',encoding="utf-8") 8 foo.write("Helloworld\n") 9 foo.close() 10 11 #r+默认的指针会放在文件开始位置所有会替换掉第一行 12 foo = open('userdata.txt','r+',encoding="utf-8") 13 foo.write("aaaaaaaa") 14 foo.close()
文件更改思路
在日常中对文件进行的操作有很多,并且我们也经常涉及更改文件内容,那么在python中没有那么智能,所以更文件就比较麻烦主要思路有两种
1、将文件加载到内存,并在内存中更改完成后,全部写入原文件
2、创建临时文件,通过readline处理文件,并写入临时文件,当全部处理完成后,将临时文件替换成原文件
显然当我们操作多个文件的时候我们用之前的方式不太理想,我们可以使用 with 语句操作文件对象()
语法:with open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True) as xxx:
1 ########文件内容######## 2 breathe again 3 Have you wounder how it feels when it's all over. 4 你是否想过一切结束时会是怎样的感觉? 5 Wound how it feels when you just have to start?a new. 6 想过要重新开始又会是怎样的感觉? 7 Never knowing?where you're going. 8 从不知道你往哪里去? 9 #################### 10 11 #其思路是,把原文件加载到内存,然后处理并保存到变量,然后在写入原文件 12 with open("test","r",encoding="utf-8") as file : 13 content = [] 14 for lien in file.readlines(): 15 if "Wound" in lien: 16 lien = "我是被替换的内容\n" 17 content.append(lien) 18 with open("test","w",encoding="utf-8") as file_w: 19 for i in content: 20 file_w.write(i)
1 #方法一,将文件按行读取,并进行判断,写入临时文件然后进行替换,文件替换需要借助 os模块 中的功能 2 import os 3 file_name = "test" 4 new_filename = file_name+".bk" 5 with open(file_name,"r",encoding="utf-8") as file, open(new_filename,"w",encoding="utf-8") as file_w: 6 while True: 7 line = file.readline() 8 if not line: break 9 if "Wound" in line: 10 line = "我是被替换的内容\n" 11 file_w.write(line) 12 os.remove(file_name) 13 os.rename(new_filename,file_name) 14 15 16 #方法二 借助我们之前学习的 fileinput 模块 17 import fileinput 18 file_name = "test" 19 for line in fileinput.input(file_name,inplace=1): 20 line = line.replace("Wound","我是被替换的内容") 21 print(line.strip("\n")) 22 fileinput.close()
注意! 第二种方法中用到了fileinput模块中的处理原文件的功能,这个功能无法使用openhook(称之为钩子),也就无法指定打开和写入操作时原文件的编码格式
报错提示:ValueError: FileInput cannot use an opening hook in inplace mode
然而Python3中默认的文件解码格式是gbk,所以在打开文件的时候会提示以下错误
错误提示:UnicodeDecodeError: 'gbk' codec can't decode byte 0x89 in position 116: illegal multibyte sequence
有两种解决方法:
1、将要处理的文件的编码格式变成“gbk”,在pycharm中更改文件的格式很简单,在右下角有一个编码格式,直接选择gbk即可
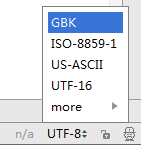
2、修改fileinput原码,在336、340、347、360行代码中加入encoding="utf-8"告诉python我的文件是utf-8的格式,那么在操作的时候python就会以utf-8处理

七、编码与文件方法(os模块对文件目录的操作)
编码与转码
在第一章中我们了解到了编码的发展,也接触到了 unicode,utf-8和GBK,在python2中默认编码是ASCII, python3里默认是unicode,所以这就造成了
我们在操作文件时python默认会用GBK解码方式将内容解码成unicode,那为什么python3要默认Unicode编码呢?
我们知道全球的语言有很多,那么为了规范这些国家有统一的规范进行约束,改变以往字符集编码不兼容的情况,Unicode诞生了,但是在Unicode推广中出
现很多问题,最主要的原因是原来欧美用户的编码都是单字节的,而Unicode编码是双字节,这样大大增加了文本数据占用的空间,要知道在原来磁盘空间远
远没有现在这么大,在这个背景下Utf-8诞生了
那么我们知道了python3里默认是unicode,而我们的文件是UTF-8的编码,想要把UTF-8变成Unicode就需要进行转码
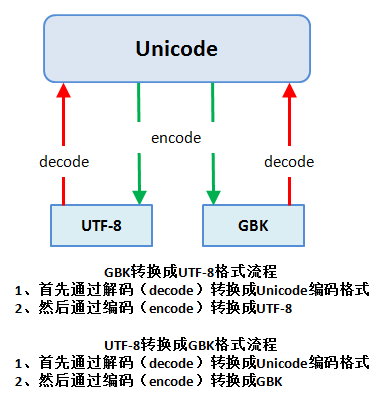
Python3 File(文件) 方法
在文件操作中除了读写还有其他的方法例如file.tell()返回文件当前位置等
1 file = open("test","r",encoding="utf-8") 2 3 # 1 关闭文件。关闭后文件不能再进行读写操作。 4 file.close() 5 6 # 2 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 7 #一般情况下,文件关闭后会自动刷新缓冲区,但有时你需要在关闭前刷新它,这时就可以使用 flush() 方法。 8 file.flush() 9 10 # 3 返回一个整型的文件描述符(file descriptor FD 整型), 可用于底层操作系统的 I/O 操作 11 file.fileno() 12 13 # 4 如果文件连接到一个终端设备返回 True,否则返回 False。 14 file.isatty() 15 16 # 5 返回文件下一行。 17 next(file) 18 19 # 6 从文件读取指定的字节数,如果未给定或为负则读取所有。size是字节的意思 20 file.read([size]) 21 22 # 7 从文件读取指定的字节数,如果未给定或为负则读取所有。 23 file.readline([size]) 24 25 # 8 读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比sizhint较大, 因为需要填充缓冲区。 26 file.readlines([sizehint]) 27 28 # 9 读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比sizhint较大, 因为需要填充缓冲区。 29 file.seek(offset[, whence]) 30 31 # 10 返回文件当前位置。 32 file.tell() 33 34 # 11 截取文件,截取的字节通过size指定,默认为当前文件位置。 35 file.truncate([size]) 36 37 # 12 将字符串写入文件,没有返回值。 38 file.write(str) 39 40 # 13 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 41 file.writelines(sequence)
OS模块操作文件和目录的方法
指针:
什么是指针?我么知道数据存储是按照字节的,那么指针就表示在一串数据中位于第几个字节。在open的时候文件指针在第一位,
当读取完成后文件指针在最后,这也就是为什么在上面 文件读操作的时候加入了fo.seek(0, 0)把文件指针定位到开头,
下图假如四个字节是一行的话那么readline读取一行后的位置就是在4的位置
指针操作不外乎这两个 file.tell() 获取当前指针位置 file.seek() 将指针重定位
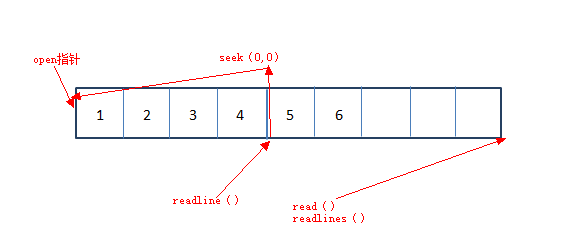
内置模块OS:
模块是什么?在这里我们简单理解一下,模块就是python中准备好的各种功能,就类似于工具盒,工具盒里面的钳子有钳子的用处,锤子有锤子的用处,
python也一样os这个内置模块拥有操作文件和目录的功能,更多模块内容请参考简学Python第三章
1 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 2 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd 3 os.curdir 返回当前目录: ('.') 4 os.pardir 获取当前目录的父目录字符串名:('..') 5 os.makedirs('dirname1/dirname2') 可生成多层递归目录 6 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 7 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname 8 os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname 9 os.unlink(path) 删除文件路径 10 os.utime(path, times)返回指定的path文件的访问和修改的时间。 11 os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 12 os.remove() 删除一个文件 13 os.rename("oldname","newname") 重命名文件/目录 14 os.stat('path/filename') 获取文件/目录信息 15 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" 16 os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" 17 os.pathsep 输出用于分割文件路径的字符串 18 os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' 19 os.path.abspath(path) 返回path规范化的绝对路径 20 os.path.split(path) 将path分割成目录和文件名二元组返回 21 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 22 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 23 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False 24 os.path.isabs(path) 如果path是绝对路径,返回True 25 os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False 26 os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False 27 os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 28 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 29 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
因为OS针对文件和目录的操作众多,更多方法请点击这里,官方介绍
作者:北京小远
出处:http://www.cnblogs.com/bj-xy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号