
谷歌技术"三宝"之BigTable(转)
2006年的OSDI有两篇google的论文,分别是BigTable和Chubby。Chubby是一个分布式锁服务,基于Paxos算法;BigTable是一个用于管理结构化数据的分布式存储系统,构建在GFS、Chubby、SSTable等google技术之上。相当多的google应用使用了BigTable,比如Google Earth和Google Analytics,因此它和GFS、MapReduce并称为谷歌技术"三宝"。
与GFS和MapReduce的论文相比,我觉得BigTable的论文难懂一些。一方面是因为自己对数据库不太了解,另一方面又是因为对数据库的理解局限于关系型数据库。尝试用关系型数据模型去理解BigTable就容易"走火入魔"。在这里推荐一篇文章(需要FQ):Understanding HBase and BigTable,相信这篇文章对理解BigTable/HBase的数据模型有很大帮助。
1 什么是BigTable
Bigtable是一个为管理大规模结构化数据而设计的分布式存储系统,可以扩展到PB级数据和上千台服务器。很多google的项目使用Bigtable存储数据,这些应用对Bigtable提出了不同的挑战,比如数据规模的要求、延迟的要求。Bigtable能满足这些多变的要求,为这些产品成功地提供了灵活、高性能的存储解决方案。
Bigtable看起来像一个数据库,采用了很多数据库的实现策略。但是Bigtable并不支持完整的关系型数据模型;而是为客户端提供了一种简单的数据模型,客户端可以动态地控制数据的布局和格式,并且利用底层数据存储的局部性特征。Bigtable将数据统统看成无意义的字节串,客户端需要将结构化和非结构化数据串行化再存入Bigtable。
下文对BigTable的数据模型和基本工作原理进行介绍,而各种优化技术(如压缩、Bloom Filter等)不在讨论范围。
2 BigTable的数据模型
Bigtable不是关系型数据库,但是却沿用了很多关系型数据库的术语,像table(表)、row(行)、column(列)等。这容易让读者误入歧途,将其与关系型数据库的概念对应起来,从而难以理解论文。Understanding HBase and BigTable是篇很优秀的文章,可以帮助读者从关系型数据模型的思维定势中走出来。
本质上说,Bigtable是一个键值(key-value)映射。按作者的说法,Bigtable是一个稀疏的,分布式的,持久化的,多维的排序映射。
先来看看多维、排序、映射。Bigtable的键有三维,分别是行键(row key)、列键(column key)和时间戳(timestamp),行键和列键都是字节串,时间戳是64位整型;而值是一个字节串。可以用 (row:string, column:string, time:int64)→string 来表示一条键值对记录。
行键可以是任意字节串,通常有10-100字节。行的读写都是原子性的。Bigtable按照行键的字典序存储数据。Bigtable的表会根据行键自动划分为片(tablet),片是负载均衡的单元。最初表都只有一个片,但随着表不断增大,片会自动分裂,片的大小控制在100-200MB。行是表的第一级索引,我们可以把该行的列、时间和值看成一个整体,简化为一维键值映射,类似于:
-
1 table{ 2 "1" : {sth.},//一行 3 "aaaaa" : {sth.}, 4 "aaaab" : {sth.}, 5 "xyz" : {sth.}, 6 "zzzzz" : {sth.} 7 }
列是第二级索引,每行拥有的列是不受限制的,可以随时增加减少。为了方便管理,列被分为多个列族(column family,是访问控制的单元),一个列族里的列一般存储相同类型的数据。一行的列族很少变化,但是列族里的列可以随意添加删除。列键按照family:qualifier格式命名的。这次我们将列拿出来,将时间和值看成一个整体,简化为二维键值映射,类似于:
-
1 table{ 2 // ... 3 "aaaaa" : { //一行 4 "A:foo" : {sth.},//一列 5 "A:bar" : {sth.},//一列 6 "B:" : {sth.} //一列,列族名为B,但是列名是空字串 7 }, 8 "aaaab" : { //一行 9 "A:foo" : {sth.}, 10 "B:" : {sth.} 11 }, 12 // ... 13 } 14
或者可以将列族当作一层新的索引,类似于:
-
1 table{ 2 // ... 3 "aaaaa" : { //一行 4 "A" : { //列族A 5 "foo" : {sth.}, //一列 6 "bar" : {sth.} 7 }, 8 "B" : { //列族B 9 "" : {sth.} 10 } 11 }, 12 "aaaab" : { //一行 13 "A" : { 14 "foo" : {sth.}, 15 }, 16 "B" : { 17 "" : "ocean" 18 } 19 }, 20 // ... 21 }
时间戳是第三级索引。Bigtable允许保存数据的多个版本,版本区分的依据就是时间戳。时间戳可以由Bigtable赋值,代表数据进入Bigtable的准确时间,也可以由客户端赋值。数据的不同版本按照时间戳降序存储,因此先读到的是最新版本的数据。我们加入时间戳后,就得到了Bigtable的完整数据模型,类似于:
-
1 table{ 2 // ... 3 "aaaaa" : { //一行 4 "A:foo" : { //一列 5 15 : "y", //一个版本 6 4 : "m" 7 }, 8 "A:bar" : { //一列 9 15 : "d", 10 }, 11 "B:" : { //一列 12 6 : "w" 13 3 : "o" 14 1 : "w" 15 } 16 }, 17 // ... 18 }
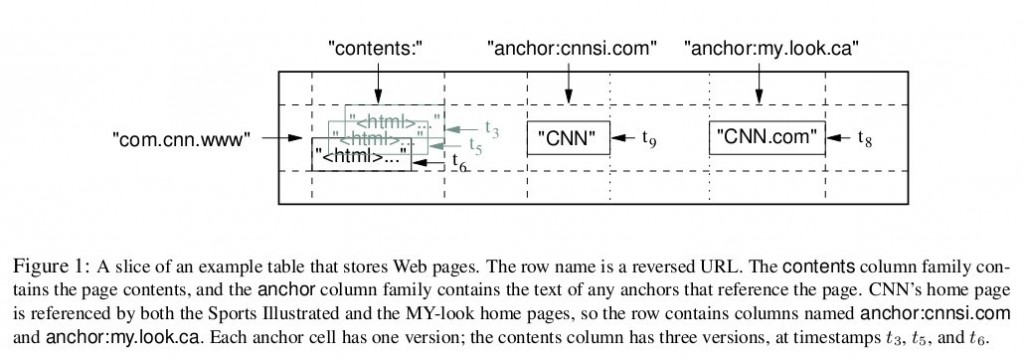
图1是Bigtable论文里给出的例子,Webtable表存储了大量的网页和相关信息。在Webtable,每一行存储一个网页,其反转的url作为行键,比如maps.google.com/index.html的数据存储在键为com.google.maps/index.html的行里,反转的原因是为了让同一个域名下的子域名网页能聚集在一起。图1中的列族"anchor"保存了该网页的引用站点(比如引用了CNN主页的站点),qualifier是引用站点的名称,而数据是链接文本;列族"contents"保存的是网页的内容,这个列族只有一个空列"contents:"。图1中"contents:"列下保存了网页的三个版本,我们可以用("com.cnn.www", "contents:", t5)来找到CNN主页在t5时刻的内容。
再来看看作者说的其它特征:稀疏,分布式,持久化。持久化的意思很简单,Bigtable的数据最终会以文件的形式放到GFS去。Bigtable建立在GFS之上本身就意味着分布式,当然分布式的意义还不仅限于此。稀疏的意思是,一个表里不同的行,列可能完完全全不一样。
3 支撑技术
Bigtable依赖于google的几项技术。用GFS来存储日志和数据文件;按SSTable文件格式存储数据;用Chubby管理元数据。
GFS参见谷歌技术"三宝"之谷歌文件系统。BigTable的数据和日志都是写入GFS的。
SSTable的全称是Sorted Strings Table,是一种不可修改的有序的键值映射,提供了查询、遍历等功能。每个SSTable由一系列的块(block)组成,Bigtable将块默认设为64KB。在SSTable的尾部存储着块索引,在访问SSTable时,整个索引会被读入内存。BigTable论文没有提到SSTable的具体结构,LevelDb日知录之四: SSTable文件这篇文章对LevelDb的SSTable格式进行了介绍,因为LevelDB的作者JeffreyDean正是BigTable的设计师,所以极具参考价值。每一个片(tablet)在GFS里都是按照SSTable的格式存储的,每个片可能对应多个SSTable。
Chubby是一种高可用的分布式锁服务,Chubby有五个活跃副本,同时只有一个主副本提供服务,副本之间用Paxos算法维持一致性,Chubby提供了一个命名空间(包括一些目录和文件),每个目录和文件就是一个锁,Chubby的客户端必须和Chubby保持会话,客户端的会话若过期则会丢失所有的锁。关于Chubby的详细信息可以看google的另一篇论文:The Chubby lock service for loosely-coupled distributed systems。Chubby用于片定位,片服务器的状态监控,访问控制列表存储等任务。
4 Bigtable集群
Bigtable集群包括三个主要部分:一个供客户端使用的库,一个主服务器(master server),许多片服务器(tablet server)。
正如数据模型小节所说,Bigtable会将表(table)进行分片,片(tablet)的大小维持在100-200MB范围,一旦超出范围就将分裂成更小的片,或者合并成更大的片。每个片服务器负责一定量的片,处理对其片的读写请求,以及片的分裂或合并。片服务器可以根据负载随时添加和删除。这里片服务器并不真实存储数据,而相当于一个连接Bigtable和GFS的代理,客户端的一些数据操作都通过片服务器代理间接访问GFS。
主服务器负责将片分配给片服务器,监控片服务器的添加和删除,平衡片服务器的负载,处理表和列族的创建等。注意,主服务器不存储任何片,不提供任何数据服务,也不提供片的定位信息。
客户端需要读写数据时,直接与片服务器联系。因为客户端并不需要从主服务器获取片的位置信息,所以大多数客户端从来不需要访问主服务器,主服务器的负载一般很轻。
5 片的定位
前面提到主服务器不提供片的位置信息,那么客户端是如何访问片的呢?来看看论文给的示意图,Bigtable使用一个类似B+树的数据结构存储片的位置信息。
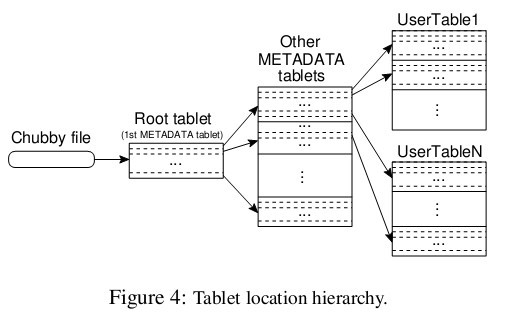
首先是第一层,Chubby file。这一层是一个Chubby文件,它保存着root tablet的位置。这个Chubby文件属于Chubby服务的一部分,一旦Chubby不可用,就意味着丢失了root tablet的位置,整个Bigtable也就不可用了。
第二层是root tablet。root tablet其实是元数据表(METADATA table)的第一个分片,它保存着元数据表其它片的位置。root tablet很特别,为了保证树的深度不变,root tablet从不分裂。
第三层是其它的元数据片,它们和root tablet一起组成完整的元数据表。每个元数据片都包含了许多用户片的位置信息。
可以看出整个定位系统其实只是两部分,一个Chubby文件,一个元数据表。注意元数据表虽然特殊,但也仍然服从前文的数据模型,每个分片也都是由专门的片服务器负责,这就是不需要主服务器提供位置信息的原因。客户端会缓存片的位置信息,如果在缓存里找不到一个片的位置信息,就需要查找这个三层结构了,包括访问一次Chubby服务,访问两次片服务器。
6 片的存储和访问

当片服务器收到一个写请求,片服务器首先检查请求是否合法。如果合法,先将写请求提交到日志去,然后将数据写入内存中的memtable。memtable相当于SSTable的缓存,当memtable成长到一定规模会被冻结,Bigtable随之创建一个新的memtable,并且将冻结的memtable转换为SSTable格式写入GFS,这个操作称为minor compaction。
当片服务器收到一个读请求,同样要检查请求是否合法。如果合法,这个读操作会查看所有SSTable文件和memtable的合并视图,因为SSTable和memtable本身都是已排序的,所以合并相当快。
每一次minor compaction都会产生一个新的SSTable文件,SSTable文件太多读操作的效率就降低了,所以Bigtable定期执行merging compaction操作,将几个SSTable和memtable合并为一个新的SSTable。BigTable还有个更厉害的叫major compaction,它将所有SSTable合并为一个新的SSTable。
遗憾的是,BigTable作者没有介绍memtable和SSTable的详细数据结构。
7 BigTable和GFS的关系
集群包括主服务器和片服务器,主服务器负责将片分配给片服务器,而具体的数据服务则全权由片服务器负责。但是不要误以为片服务器真的存储了数据(除了内存中memtable的数据),数据的真实位置只有GFS才知道,主服务器将片分配给片服务器的意思应该是,片服务器获取了片的所有SSTable文件名,片服务器通过一些索引机制可以知道所需要的数据在哪个SSTable文件,然后从GFS中读取SSTable文件的数据,这个SSTable文件可能分布在好几台chunkserver上。
8 元数据表的结构
元数据表(METADATA table)是一张特殊的表,它被用于数据的定位以及一些元数据服务,不可谓不重要。但是Bigtable论文里只给出了少量线索,而对表的具体结构没有说明。这里我试图根据论文的一些线索,猜测一下表的结构。首先列出论文中的线索:
- The METADATA table stores the location of a tablet under a row key that is an encoding of the tablet's table identifier and its end row.
- Each METADATA row stores approximately 1KB of data in memory(因为访问量比较大,元数据表是放在内存里的,这个优化在论文的locality groups中提到).This feature(将locality group放到内存中的特性) is useful for small pieces of data that are accessed frequently: we use it internally for the location column family in the METADATA table.
- We also store secondary information in the METADATA table, including a log of all events pertaining to each tablet(such as when a server begins
serving it).
第一条线索,元数据表的行键是由片所属表名的id和片最后一行编码而成,所以每个片在元数据表中占据一条记录(一行),而且行键既包含了其所属表的信息也包含了其所拥有的行的范围。譬如采取最简单的编码方式,元数据表的行键等于strcat(表名,片最后一行的行键)。
第二点线索,除了知道元数据表的地址部分是常驻内存以外,还可以发现元数据表有一个列族称为location,我们已经知道元数据表每一行代表一个片,那么为什么需要一个列族来存储地址呢?因为每个片都可能由多个SSTable文件组成,列族可以用来存储任意多个SSTable文件的位置。一个合理的假设就是每个SSTable文件的位置信息占据一列,列名为location:filename。当然不一定非得用列键存储完整文件名,更大的可能性是把SSTable文件名存在值里。获取了文件名就可以向GFS索要数据了。
第三个线索告诉我们元数据表不止存储位置信息,也就是说列族不止location,这些数据暂时不是咱们关心的。
通过以上信息,我画了一个简化的Bigtable结构图:
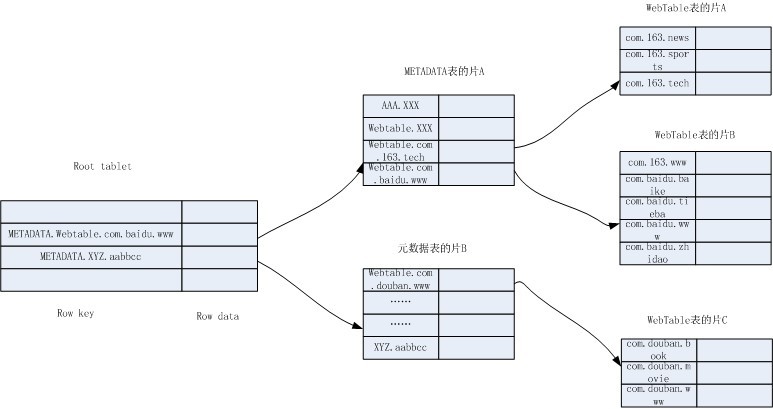
结构图以Webtable表为例,表中存储了网易、百度和豆瓣的几个网页。当我们想查找百度贴吧昨天的网页内容,可以向Bigtable发出查询Webtable表的(com.baidu.tieba, contents:, yesterday)。
假设客户端没有该缓存,那么Bigtable访问root tablet的片服务器,希望得到该网页所属的片的位置信息在哪个元数据片中。使用METADATA.Webtable.com.baidu.tieba为行键在root tablet中查找,定位到最后一个比它大的是METADATA.Webtable.com.baidu.www,于是确定需要的就是元数据表的片A。访问片A的片服务器,继续查找Webtable.com.baidu.tieba,定位到Webtable.com.baidu.www是比它大的,确定需要的是Webtable表的片B。访问片B的片服务器,获得数据。
参考文献
[1] Bigtable: A Distributed Storage System for Structured Data. In proceedings of OSDI'06.

