自动机全家桶
自动机真的好难!
自动机
一个确定有限状态自动机,即 DFA,可以理解成一张有向图,每一个结点都是一个状态。
自动机由五部分组成:
- 字符集 \(\sum\)
- 状态集合 \(Q\) ,相当于图上的顶点
- 起始状态 \(start \in Q\)
- 接受状态集合 \(F\)
- 转移函数 \(\delta\),其中第一个参数和结果都为状态,第二个参数为字符集的一个字符,相当于 DFA 中的边,每条边上都有一个字符。
这不是重点,重点是下面介绍的几种自动机。
序列自动机
比较简单的一种自动机,主要用来识别一个串的子序列。
一个长度为 \(n\) 的字符串 \(s\) 的序列自动机包含 \(n + 1\) 个状态,下图(来自知乎 @Pecco)为 \(abcab\) 的序列自动机。
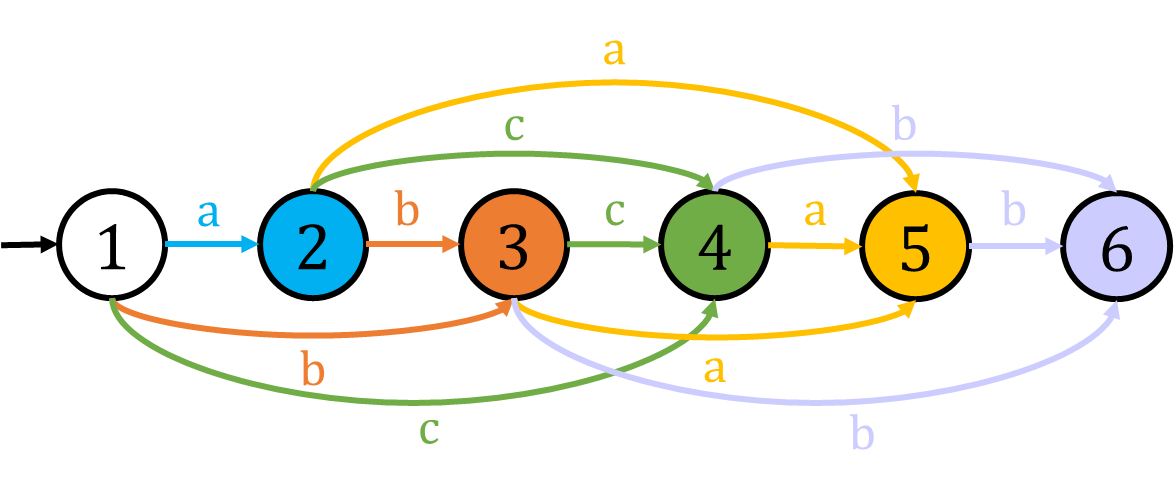
我们可以维护一个 \(ne[i][j]\) 表示从 \(i\) 开始字符 \(j\) 第一次出现的位置,其中 \(j \in \sum\)。
对于一个文本串 \(s\),我们可以从 \(n \sim 1\) 递推,每一次显然 \(\forall j \in \sum\),\(ne[i][j] = ne[i + 1][j]\),然后再将 \(ne[i][s[i]]\) 置为 \(i\) 即可。
以下是 \(j \in [a, z]\) 的代码:
fro(i, n, 1) {
rep(j, 0, 25) ne[i][j] = ne[i + 1][j];
ne[i][s[i] - 'a'] = i;
}
时间和空间复杂度都是 \(O(n\sum)\)
会了这个后,你就可以完成很多的题目。
ARC081C
求不是一个字符串 \(s\) 的子序列的最短串,我们可以先对 \(s\) 建立序列自动机,然后从起始状态开始 \(bfs\),对于自动机中的一个状态 \(t\),枚举所有的 \(\delta(t, c)\),直到找到第一个没有出现过的,然后就找到了。
我们可以记录一个 \(pre[x]\) 表示第 \(x\) 状态是从哪里过来的,然后倒序输出即可。
P1819
本题相当于求 \(A, B, C\) 三个字符串的公共子序列数量。
首先还是先分别求出三个字符串的 \(ne\) 备用,然后我们考虑 \(DP\)。
令 \(F[x][y][z]\) 表示序列 \(A\) 从 \(x\) 开始,\(B\) 从 \(y\) 开始,\(C\) 从 \(z\) 开始的公共子序列数量。
转移时我们考虑枚举下一个公共字符 \(c\),则可以转移到 \(F[neA_{x, c}][neB_{y, c}][neC_{z, c}]\),即:
\(F[x][y][z] = \sum_{c \in [a, z]} F[neA_{x, c}][neB_{y, c}][neC_{z, c}]\)
记忆化搜索即可。
在实现过程中要注意将 \(ne[i][s[i] - 'a']\) 置为 \(i + 1\),否则会自己跳到自己,就死循环了,或者你在 \(DP\) 转移的时候加一也行。
为了方便实现,我们考虑将 \(ne\) 封装到结构体里,就不用写三遍了。
时间为状态数乘转移数,是 \(O(n ^ 3\sum)\)。
双倍经验题:P3856
P5826
可以发现,除了字符集大小非常大以外,都是非常模板的,如果暴力 \(O(n\sum)\) 的话时间空间都受不了。
但我们观察求 \(ne\) 的过程,其实对于 \(i\) 每次只有 \(ne[i][s[i] - 'a']\) 相比 \(i + 1\) 发生了变化,所以我们其实使用了很多无用的空间和操作。我们考虑使用主席树的思想,每次单点修改即可。
代码其实还算好写,因为只用到了最模板的主席树,然后用主席树查询即可。
P4608
如果数据不需要高精度的话是一道非常眉清目秀的题目,对于 \(k = 0\) 和 \(k = 1\) 的情况分开来写两个 \(dp\) 即可,思路类似 \(P1819\),输出路径可以在记忆化搜索函数的开头输出答案序列即可。
为什么要演奏高精度!气死了喵!
坑点:空的序列也是要输出的,而且是英文大小写字母。
AC 自动机
建立
事情开始变得不对劲起来了
\(AC\) 自动机其实就是 \(Trie + KMP\),本质上就是利用 \(KMP\) 的思想同时对多个模式串进行匹配。如果不熟悉这两个建议先去复习一下。
在做 \(AC\) 自动机之前,我们得先建出一个 \(Trie\) 然后如同 \(KMP\) 定义 \(ne\) 数组一样,我们定义 \(fail[u]\) 表示所有模式串中最长的前缀中匹配当前 \(u\) 结点所对应状态的后缀。有点绕,你可以理解成 \(KMP\) 中的最长公共前后缀不一定在同一个序列上,可能是一个不同序列的前缀和当前 \(u\) 结点所对应状态的后缀相等。
比如当前 $ Trie$ 中已经有了 \(he\) 和 \(her\),那么你可以理解为 \(fail[her] = he\),只不过真是存的是对应 \(her\) 的状态 \(u\),对应 \(he\) 的状态为 \(v\),则 \(fail[u] = v\)。
我们考虑如何建立所有的 \(fail\) 指针。
按照 \(KMP\) 的思路,我们考虑从 \(Trie\) 的根节点开始,向下逐位地匹配。
对于一个结点 \(u\),它的父节点为 \(p\),\(trie(p, c) = u\)。我们考虑用深度小于 \(u\) 的结点的 \(fail\) 来推 \(u\) 的 \(fail\)。
如果 \(trie(fail[p], c)\) 存在,就让 \(fail[u] = trie(fail[p], c)\),相当于在 \(p\) 和 \(fail[p]\) 后面都加上一个字符 \(c\)。
如果 \(trie(fail[p], c)\) 不存在,我们就继续跳 \(fail[fail[p]]\),\(fail[fail[fail[p]]]\)……直到根节点如果也不存在,就让 \(fail\) 指向根节点。
OI-wiki 的动图:

我们发现一只跳 \(fail\) 显然做了很多无用功,所以可以进行路径压缩。
我们还是思考对于一个结点 \(p\),令 \(u = trie(p, c)\),分两种情况考虑:
- 如果 \(u\) 存在,那么我们可以直接令 \(fail[u] = trie(fail[p], c)\),不考虑 \(trie(fail[p], c)\) 是否存在。这利用到了数学归纳法的思想,我们假定前面的层数都已经计算好了,所以可以直接像上述一般赋值。换句话说,我们不用考虑到达 \(fail[p]\) 后怎么跳,因为这已经是算好的。
- 如果 \(u\) 不存在,则令 \(u = trie(fail[p], c)\)。因为你考虑朴素操作中如果 \(u\) 不存在会一直跳 \(fail\) 直到找到或是到根节点,而我们现在是直接将 \(fail\) 赋值,所以我们需要冒充有一直向上跳,从而便有了如此地设计。
认真理解一下这一长串文字,其实并不是非常难懂。
到此,\(fail\) 构建的部分就告一段落,下面给出插入和构建的模板代码。
顺便再提一嘴,这样建出来的 \(trie\) 其实可以称作 \(trie\) 图,因为 \(fail\) 的缘故它已经不能称作树了。
void insert() {
int p = 0;
for (int i = 0; s[i]; i ++) {
int c = s[i] - 'a';
if (!tr[p][c]) tr[p][c] = ++ idx;
p = tr[p][c];
}
cnt[p] ++;
}
void build() {
queue<int> q;
rep(i, 0, 25)
if (tr[0][i]) q.push(tr[0][i]);
while (q.size()) {
int u = q.front(); q.pop();
rep(i, 0, 25) {
int p = tr[u][i];
if (!p) tr[u][i] = tr[ne[u]][i];
else {
ne[p] = tr[ne[u]][i];
q.push(p);
}
}
}
}
接下来我们考虑匹配,我们将会以一道模板题为例。
P3808(简单的匹配)
我们需要查询有多少个不同的模式串在文本串中出现过。
首先我们按照上述过程对所有模式串建立 \(AC\) 自动机,然后考虑匹配怎么做。
我们可以用 \(u\) 表示当前匹配到的 \(AC\) 自动机状态,在遍历文本串时顺着文本串的字符 \(c\) 走 \(\delta(u, c)\),然后不断地向上跳 \(fail\) 将走到的所有节点加上贡献,然后把结点的 \(cnt\) 清空,避免重复计算。
文字叙述比较抽象,可以结合图片理解(还是 OI-wiki):
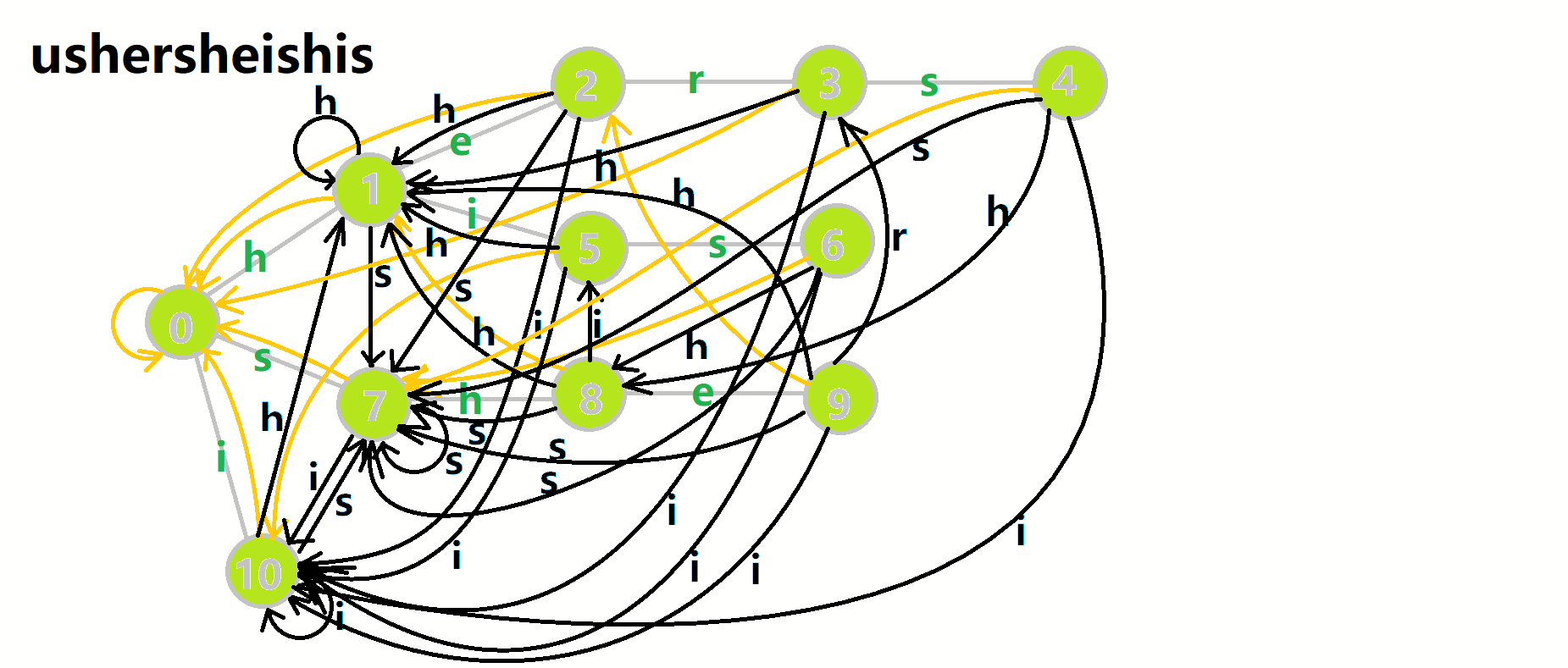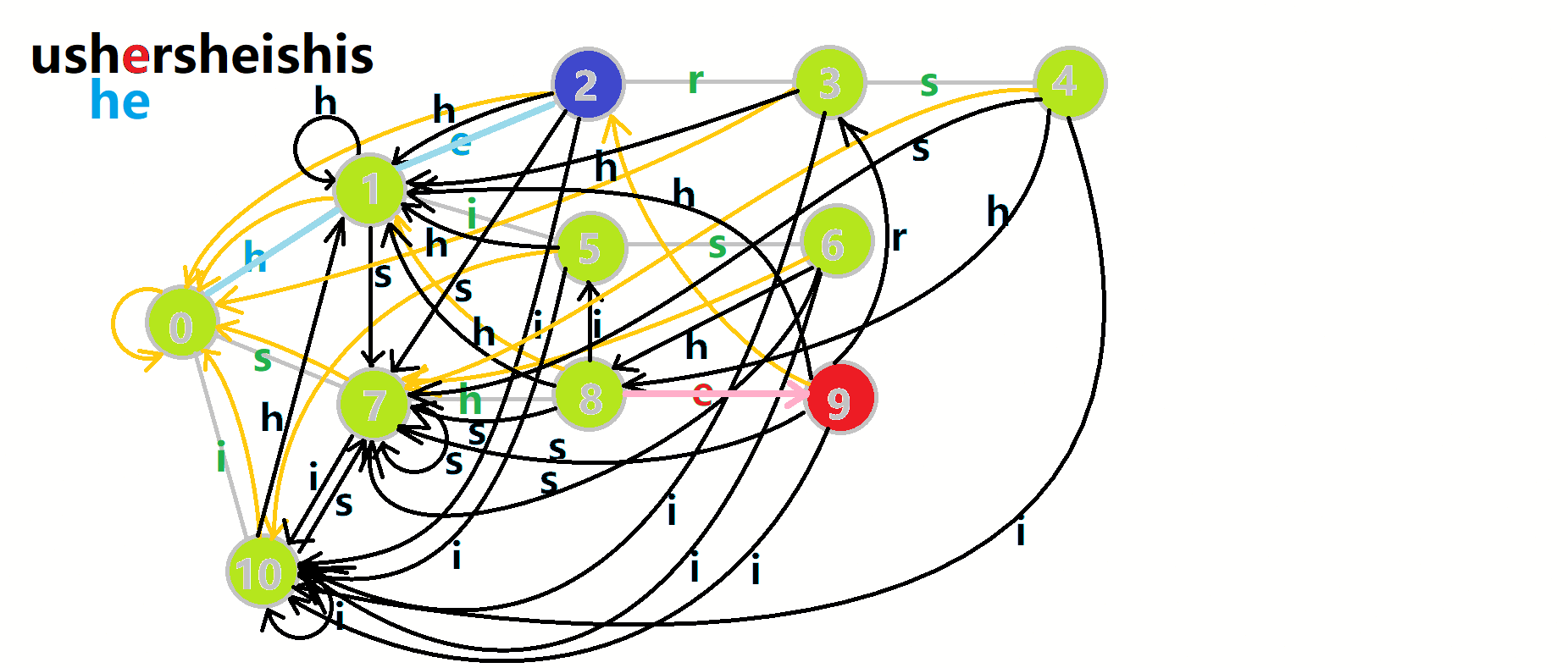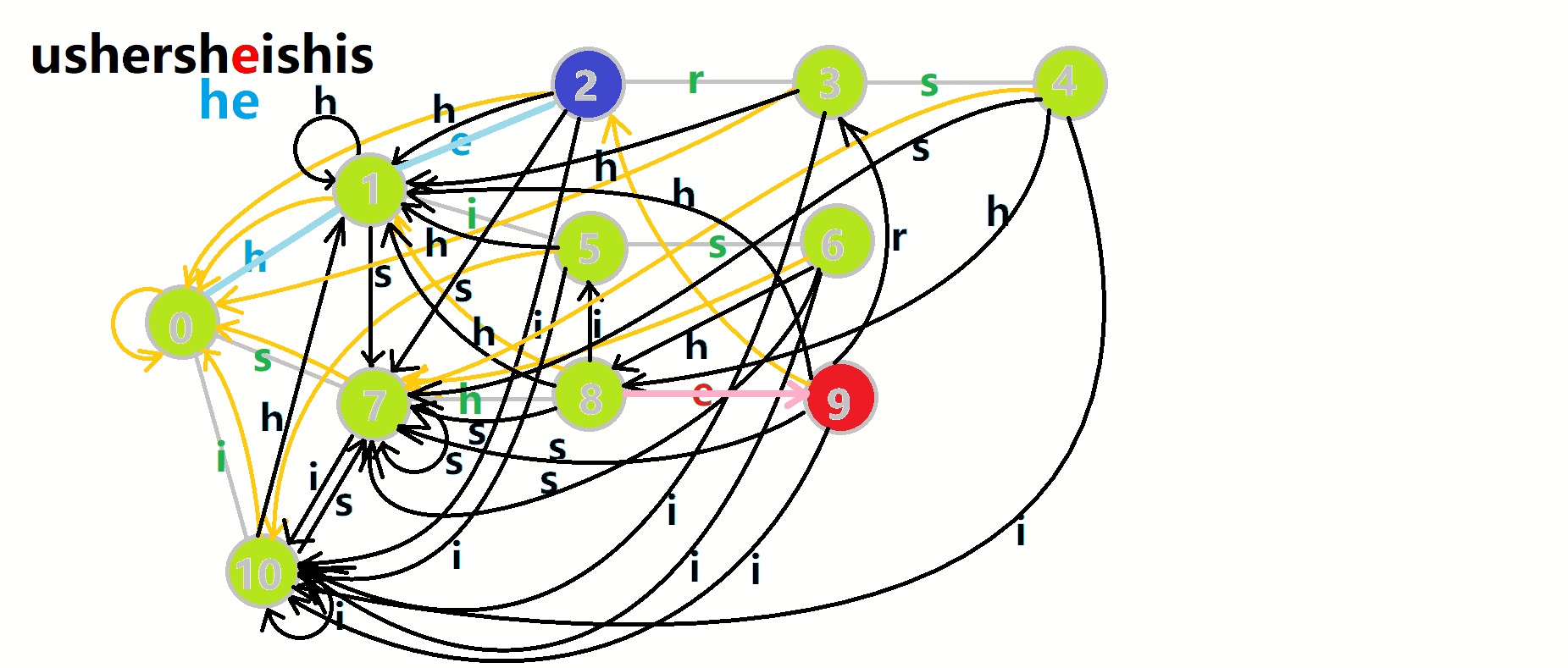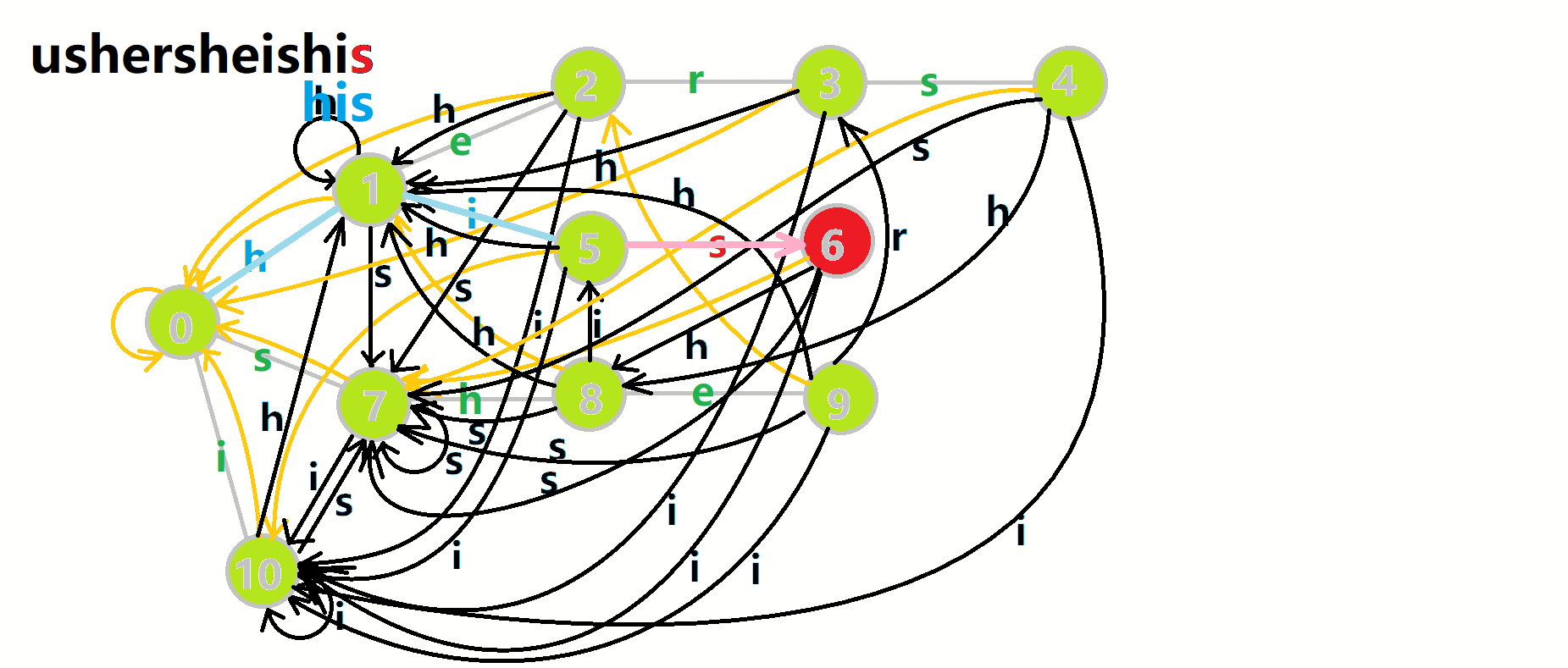
完整的代码可以去[这里](记录详情 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn))
匹配的代码:
// 由于我们将 cnt[p] 清 0 的缘故,复杂度是对的
int res = 0;
for (int i = 0, u = 0; s[i]; i ++) {
int c = s[i] - 'a';
u = tr[u][c];
int p = u;
while (p && cnt[p]) {
res += cnt[p];
cnt[p] = 0;
p = ne[p];
}
}
P5357(匹配优化)
朴素做法十分简单,在 \(trie\) 插入字符串时记录一下 \(ed[p]\) 表示 \(p\) 作为结尾对应的字符串序号,然后在匹配向上跳的过程中,不断将 \(ans[ed[p]] ++\) 即可。
但这样子由于会一直跳 \(fail\),并且不像上一题有清空的优化,所以会超时。
我们考虑 \(fail\) 指针的一个性质:如果 \(AC\) 自动机中只保留 \(fail\) 边,那么剩余的图一定是一棵树。这是显然的。所以上文的匹配就可以转化成 \(fail\) 树上的链求和问题,就可以进行优化。
我们按照 \(fail\) 树做拓扑排序。因为如果一个结点 \(u\) 有贡献,那么它往上跳 \(fail\) 跳到的所有点都有贡献,所以我们可以不用暴力跳,在查询的时候只为找到结点的 \(ans\) 进行计算,然后按照拓扑序计算即可。
代码实现时我们要在 \(build\) 中加入入度统计。
注意模式串中可能有重复的,所以要特殊处理一下,可以看代码理解,这里就不细说了。
代码马蜂应该还是比较不错的?
const int N = 200010, M = 2000010;
int n, idx[N], mp[N], res[N];
char s[M];
namespace AC {
int tr[N][26], ne[N], pidx, degs[N], tot, ans[N];
void insert(char s[N], int id) {
int p = 0;
for (int i = 0; s[i]; i ++) {
int c = s[i] - 'a';
if (!tr[p][c]) tr[p][c] = ++ tot;
p = tr[p][c];
}
if (!mp[p]) mp[p] = ++ pidx;
idx[id] = mp[p];
}
void build() {
queue<int> q;
rep(i, 0, 25)
if (tr[0][i]) q.push(tr[0][i]);
while (q.size()) {
int u = q.front(); q.pop();
rep(i, 0, 25) {
int p = tr[u][i];
if (!p) tr[u][i] = tr[ne[u]][i];
else {
ne[p] = tr[ne[u]][i];
degs[tr[ne[u]][i]] ++;
q.push(p);
}
}
}
}
void query(char s[N]) {
int p = 0;
for (int i = 0; s[i]; i ++) {
p = tr[p][s[i] - 'a'];
ans[p] ++;
}
}
void topu() {
queue<int> q;
rep(i, 1, tot)
if (!degs[i]) q.push(i);
while(q.size()) {
int u = q.front(); q.pop();
res[mp[u]] = ans[u];
ans[ne[u]] += ans[u];
degs[ne[u]] --;
if (!degs[ne[u]]) q.push(ne[u]);
}
}
};
int main() {
n = read();
rep(i, 1, n) {
scanf("%s", s);
AC::insert(s, i);
}
AC::build();
scanf("%s", s);
AC::query(s); AC::topu();
rep(i, 1, n) printf("%d\n", res[idx[i]]);
return 0;
}
P2414
一道非常有趣的 \(AC\) 自动机题。
首先,根据 \(fail\) 的定义,对于 \(AC\) 自动机中的一个 \(y\) 的 \(fail\) 指向 \(x\),则 \(x\) 表示的字符串一定出现在 \(y\) 表示的字符串中。
所以原题中的询问可以转换为找所有属于 \(y\) 的结点中 \(fail\) 直接或间接指向 \(x\) 的结束位置的数量。
所以可以进一步转化成在 \(fail\) 树中,以 \(x\) 结束点为根的子树中,属于 \(y\) 的点的数量。我们只要把 \(y\) 的点全部标记为 \(1\),然后每次对 \(x\) 的末节点求一遍和即可。
我们考虑将 \(fail\) 树跑一遍 \(dfs\) 得出 \(dfs\) 序,这样这个问题就变成了序列问题。由于一个点的子树在 \(dfs\) 序上一定是连续的,所以可以直接使用树状数组求和。
具体来说我们将询问都离线下来,然后从左到右扫描给出的字符串,分三种情况:
- 若遇到 \(B\),标记减一然后回退。
- 若遇到 \(P\),则可以直接解决 \(y\) 为当前点的询问
- 否则走一步,并将走到的结点加一
要维护的细节还是很多的,包括但不限于字符串 \(id\) 的映射和上一步的维护。
P6257
考虑题目给出的名字都是前面加一个字母,这非常不友好,所以我们考虑每次在后面加一个字母,然后将所有的询问串都翻转。这样题目就转化成了查找有多少个人名字后缀包含某个询问串。
这就比较好做了,我们可以对于所有翻转的查询串建立 \(AC\) 自动机,然后对于所有的名字建 \(Trie\)。显然根据题目给出的名字结构是非常好建 \(Trie\) 的。
接着我们考虑一个名字在 \(AC\) 自动机中出现的后缀肯定是一条 \(fail\) 链,所以我们不妨建出 \(fail\) 树。直接跳显然不对,但我们只要在最长的后缀的位置标记,最后用拓扑排序或者 \(dfs\) 计算答案即可。
回文自动机
在学习回文自动机(\(PAM\))之前最好先学 \(manacher\) 喵。
回文自动机是一个高效存储所有回文子串的自动机,它不同于 \(manacher\) 中间加符号让偶串变奇串,而是直接将偶串和奇串分开考虑。
具体来说,我们维护一个奇根和偶根,其中奇根编号为 \(1\),偶根编号为 \(0\),奇根对应回文串长度为 \(-1\),偶根对应回文串长度为 \(0\)。不难发现,奇根和偶根便是 \(PAM\) 的初始状态。
定义 \(PAM\) 上的一个点到根的路径上的字符串为回文串的一半,即 \(PAM\) 的读法是从一个点读到根再倒着读回来。而连接奇根的边只读一次,举个例子:
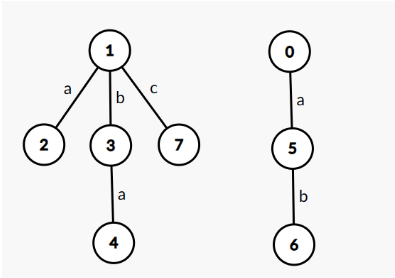
上图中 \(4\) 结点就代表 \(aba\),\(6\) 结点代表 \(baab\)。
同样地 \(PAM\) 也有自己的 \(fail\) 指针,代表一个状态除自己以外的最长回文后缀。同时对于每个结点我们还要记录 \(len[u]\) 表示 \(u\) 所对应回文串的实际长度。
如何构造 \(fail\)?其实和 \(AC\) 自动机十分相似。
我们考虑已经计算了一个串的前 \(i - 1\) 位的信息,令 \(i - 1\) 的最长回文后缀对应的状态 \(u\),考虑如何计算第 \(i\) 位的信息。
显然我们可以考虑能否在 \(u\) 的左右两侧各添加一个 \(s[i]\) 看看能否匹配。即判断 \(s[i]\) 是否等于 \(s[i - len[u] - 1]\),为什么是这样的坐标可以自己算算。
如果当前 \(u\) 无法满足,就一直跳 \(fail\) 即可解决。最后对于第 \(i\) 位来说,则第 \(i\) 位对应的状态 \(p\) 就有 \(len[p] = len[u] + 2\)。
P5496
先放模板代码
const int N = 500010;
int n;
int tr[N][26], fail[N], len[N], idx, num[N];
char s[N];
int getfail(int x, int i) {
while (i - len[x] - 1 < 0 || s[i - len[x] - 1] != s[i]) x = fail[x];
return x;
}
int main() {
scanf("%s", s); n = strlen(s);
int last;
fail[0] = 1, len[1] = -1, idx = 1;
for (int i = 0, u = 0; i < n; i ++) {
if (i >= 1) s[i] = (s[i] - 97 + last) % 26 + 97;
int c = s[i] - 'a', p = getfail(u, i);
if (!tr[p][c]) {
fail[++ idx] = tr[getfail(fail[p], i)][c];
tr[p][c] = idx;
len[idx] = len[p] + 2;
num[idx] = num[fail[idx]] + 1;
}
u = tr[p][c];
last = num[u];
printf("%d ", last);
}
return 0;
}
解释一下,\(getfail\) 就是跳 \(fail\) 的过程。我们对于一个串 \(s\) 循环遍历它的每一位,然后将这一位插入到 \(PAM\) 中。\(num\) 就是用来处理题目询问的,我们可以发现一个状态是比它的最长回文后缀多一个回文串的。
然后便是一些重要的内容:
- 偶根要指向奇根,原因是如果类似于 \(abbac\) 的情况,\(c\) 怎么都匹配不上,就会一直走到偶根。而由于 \(c\) 如果只有自己的话就是一个回文串,是一定可以挂到奇根上的,所以需要从偶根去到奇根。
- 求新点的 \(fail\) 一定要在建立新点前,否则会出现神秘情况卡死。同时求新点的 \(fail\) 时也不能直接使用 \(getfail(p, i)\),否则自己会被当成自己的最长回文后缀,就卡死了。
可以发现用这种方式挂出来的自动机只有 \(n\) 个结点,时间复杂度总共是 \(O(n)\) 的。
P3649
简单应用,我们只要在插点的时候对于每个 \(i\) 让 \(cnt[i] = 1\)。然后由于回文自动机插入的时候本身就是按照拓扑序插入的,所以我们只要再插完点后再循环一遍所有的点,让 cnt[fail[i]] += cnt[i] 即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号