

蓝书 0x00
0x01 位运算
AcWing89.a^b
快速幂模板题。
令 为 在二进制下的位数, 为 在二进制下的第 位。
则
于是
所以我们只要将 二进制中所有为 的位 ,取出,答案即为所有 的乘积。
#include <iostream>
using namespace std;
typedef long long LL;
LL a, b, p;
int main() {
scanf("%lld%lld%lld", &a, &b, &p);
LL res = 1 % p;
while (b) {
if (b & 1) res = res * a % p;
b >>= 1;
a = a * a % p;
}
printf("%lld\n", res);
return 0;
}
AcWing90. 64位整数乘法
思路类似快速幂。
令
则
同样地,我们可以枚举每一个为 的二进制位,然后通过以上式子进行计算。
#include <iostream>
using namespace std;
typedef long long LL;
LL a, b, p;
int main() {
cin >> a >> b >> p;
LL res = 0;
while (b) {
if (b & 1) res = (res + a) % p;
b >>= 1;
a = (a + a) % p;
}
cout << res << endl;
return 0;
}
AcWing998. 起床困难综合症
由于给出的二进制运算的特点是不进位,所以每一位的计算是独立的。由于题目要求我们求出经过 次操作后答案最大的 并且 ,所以可以从高位到低位分别枚举 的每一位上填 还是填 。
具体的, 的第 位可以填 当且仅当:
- 填上 后
- 该位填 优于该位填
首先第一种情况,我们只要判断当前 是否小于 ;
第二种情况,我们分别计算填 和 填 后的答案,比较即可确定该位的填法。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010;
int n, m, ans;
int t[N], op[N];
int work(int x, int j) {
for (int i = 1; i <= n; i ++) {
if (op[i] == 1) x &= t[i] >> j & 1;
else if (op[i] == 2) x |= t[i] >> j & 1;
else x ^= t[i] >> j & 1;
}
return x;
}
int main() {
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i ++) {
char s[10];
scanf("%s %d", s, &t[i]);
if (*s == 'A') op[i] = 1;
else if (*s == 'O') op[i] = 2;
else op[i] = 3;
}
for (int i = 30; i >= 0; i --) {
if (1 << i <= m) {
int x = work(0, i), y = work(1, i);
if (x >= y) ans |= x << i;
else ans |= y << i, m -= 1 << i; // 这里填 1 时直接用m减掉 1 << i,方便判断
} else {
ans |= work(0, i) << i;
}
}
printf("%d\n", ans);
return 0;
}
AcWing91. 最短Hamilton路径
状压 DP 入门题。
状态表示()
- 集合:当前经过点的状态为 ,最后停在了 上。其中若 二进制的第 位为 则表示已经经过了第 个点,反之亦然。
- 属性:
状态计算:考虑我们上一步是从 来到 的,那么我们的状态转移方程就应该是
初始化:,其余均为
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 21, M = 1 << 21;
int n;
int f[M][N], w[N][N];
int main() {
cin >> n;
for (int i = 0; i < n; i ++)
for (int j = 0; j < n; j ++)
cin >> w[i][j];
memset(f, 0x3f, sizeof f);
f[1][0] = 0;
for (int i = 0; i < 1 << n; i ++)
for (int j = 0; j < n; j ++)
if (i >> j & 1)
for (int k = 0; k < n; k ++)
if (i >> k & 1)
f[i][j] = min(f[i][j], f[i - (1 << j)][k] + w[k][j]);
cout << f[(1 << n) - 1][n - 1];
return 0;
}
0x02 递推与递归
AcWing 95. 费解的开关
我们可以发现几个性质:
- 我们点灯的先后顺序不影响结果。
- 一个位置至多被点击一次
- 如果我们将第一行固定,那么想改变第一行就有且只有一种可能,便是操作该灯下方第二行的灯。
结合以上性质,我们可以进行递推,先固定第一行,然后操作第二行,接着再操作第三行,最后我们只要判断第五行操作完后是否为 即可。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510;
int n;
char g[5][5], backup[5][5];
void turn(int x, int y) {
int dx[5] = {-1, 0, 0, 0, 1}, dy[5] = {0, -1, 0, 1, 0};
for (int i = 0; i < 5; i ++) {
int xx = x + dx[i], yy = y + dy[i];
if (xx >= 0 && xx < 5 && yy >= 0 && yy < 5)
g[xx][yy] ^= 1;
}
}
void solve() {
int ans = 0x3f3f3f3f;
for (int k = 0; k < 1 << 5; k ++) {
int res = 0;
memcpy(backup, g, sizeof g);
for (int i = 0; i < 5; i ++)
if (k >> i & 1) {
res ++;
turn(0, i);
}
for (int i = 0; i < 4; i ++)
for (int j = 0; j < 5; j ++)
if (g[i][j] == '0') {
res ++;
turn(i + 1, j);
}
bool ok = true;
for (int i = 0; i < 5; i ++)
if (g[4][i] == '0')
ok = false;
if (ok) ans = min(ans, res);
memcpy(g, backup, sizeof backup);
}
if (ans > 6) ans = -1;
printf("%d\n", ans);
}
int main() {
int T; scanf("%d", &T);
while (T --) {
for (int i = 0; i < 5; i ++) scanf("%s", g[i]);
solve();
}
return 0;
}
AcWing 96. 奇怪的汉诺塔
考虑 盘 塔的汉诺塔问题,令 表示 盘 塔问题的步数。我们考虑先将 个盘子从 柱放到 柱,再把剩下的一个盘子放到 柱,最后再把 柱上的 个盘子放到 柱上。
通过以上步骤,可以写出递推式
接着考虑 塔问题。令 表示 盘 塔问题的步数。
我们可以先将 个盘子从 移到 ,剩下的 个盘子做 塔问题,从 移到 ,最后再把 柱上的 个盘子做 塔问题,移到 上。
类似的,我们可以写出递推式
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 15;
int n, f[N], d[N];
int main() {
scanf("%d", &n);
memset(f, 0x3f, sizeof f);
f[1] = 1, d[1] = 1;
for (int i = 2; i <= 12; i ++)
for (int j = 1; j < i; j ++) {
f[i] = min(f[i], 2 * f[j] + d[i - j]);
d[i] = 2 * d[i - 1] + 1;
}
for (int i = 1; i <= 12; i ++)
cout << f[i] << endl;
return 0;
}
AcWing97. 约数之和
令
那么
由约数之和的公式可得, 的约数之和为
暴力循环计算以上式子肯定会超时,所以我们可以采用分治的思想。
我们考虑如何快速计算 。
首先,我们令
接着我们根据 的奇偶性分两类讨论:
-
为奇数
-
为偶数
由此,我们便用 的时间计算出 、
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int Mod = 9901;
typedef long long LL;
int a, b;
LL qmi(int a, int b) {
a %= Mod;
LL res = 1;
while (b) {
if (b & 1) res = res * a % Mod;
b >>= 1;
a = a * a % Mod;
}
return res;
}
LL work(int p, int n) {
if (n == 0) return 1;
if (n & 1) return (qmi(p, n + 1 >> 1) + 1) * work(p, n - 1 >> 1) % Mod;
else return ((qmi(p, n >> 1) + 1) * work(p, (n >> 1) - 1) % Mod + qmi(p, n)) % Mod;
}
int main() {
scanf("%d%d", &a, &b);
LL res = 1;
for (int i = 2; i <= a / i; i ++) {
int cnt = 0;
while (a % i == 0) a /= i, cnt ++;
res = res * work(i, cnt * b) % Mod;
}
if (a > 1) res = res * work(a, b) % Mod;
if (a == 0) res = 0;
printf("%lld\n", res);
return 0;
}
0x03 前缀和与差分
AcWing99. 激光炸弹
二维前缀和应用题。
枚举被炸区域的右下角,然后用二维前缀和计算 ~ 的总和,取最大值即可。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 10010, M = 5010;
int n, r;
int g[M][M], s[M][M];
int main() {
scanf("%d%d", &n, &r);
for (int i = 1; i <= n; i ++) {
int x, y, z;
scanf("%d%d%d", &x, &y, &z);
s[x + 1][y + 1] += z;
}
int ans = -1;
r = min(r, 5001);
for (int i = 1; i <= 5001; i ++)
for (int j = 1; j <= 5001; j ++)
s[i][j] += s[i - 1][j] + s[i][j - 1] - s[i - 1][j - 1];
for (int i = r; i <= 5001; i ++)
for (int j = r; j <= 5001; j ++)
ans = max(ans, s[i][j] - s[i - r][j] - s[i][j - r] + s[i - r][j - r]);
printf("%d\n", ans);
return 0;
}
AcWing100. 增减序列
观察题目,我们每次操作只会对某个区间加或减 ,所以我们可以使用差分。
令 为 的差分数组,即 ,这样对区间 进行修改时只需要分别修改 和 即可。
因为要使 中的所有数都一样,所以 ~ 必须等于 ,而 可以为任意数。
接下来考虑操作,一共四种情况:
- 选择 和
- 选择 和
- 选择 和
- 选择 和 ,其中
第一种情况无意义不考虑,剩下三种情况中,如果 中同时存在正数和负数,我们应该优先考虑第四种情况,然后才是考虑第二种情况和第三种情况。
所以我们设 中有 个整数, 个负数,那么最小操作次数就应该是 。
而在 次的操作过程中,我们可以选择第二种操作也可以选择第三种操作,所以可能得到的结果(也就是 的值)会有 种。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010;
long long n, a[N], b[N];
long long p, q;
int main() {
scanf("%lld", &n);
for (int i = 1; i <= n; i ++) {
scanf("%lld", &a[i]);
b[i] = a[i] - a[i - 1];
}
for (int i = 2; i <= n; i ++)
if (b[i] > 0) p += b[i];
else q -= b[i];
printf("%lld\n%lld\n", max(p, q), abs(p - q) + 1);
return 0;
}
AcWing101. 最高的牛
注意到如果 ,且 和 可以互相看到的话, 和 一定无法互相看到。
于是我们便可以用差分维护这个关系。具体的,如果 和 可以互相看到的话,就让差分数组 (初始都为 ) 中的 ,这样 和 之间的牛的高度都会下降 。然后对 求前缀和,求完后再给前缀和数组中的每一头牛的高度都加上 ,也就是最高的牛的身高。
这种思想为 把对一个区间的操作转化成左右两端上的操作,再通过前缀和得到原问题的解。
#include <iostream>
#include <cstring>
#include <algorithm>
#include <map>
using namespace std;
const int N = 5010;
int n, p, h, m;
int b[N];
map<pair<int, int>, bool> H;
int main() {
scanf("%d%d%d%d", &n, &p, &h, &m);
for (int i = 1; i <= m; i ++) {
int x, y;
scanf("%d%d", &x, &y);
if (x > y) swap(x, y);
if (!H[make_pair(x, y)]) {
H[make_pair(x, y)] = true;
b[x + 1] --, b[y] ++;
}
}
for (int i = 1; i <= n; i ++) b[i] += b[i - 1];
for (int i = 1; i <= n; i ++) b[i] += h;
for (int i = 1; i <= n; i ++) printf("%d\n", b[i]);
return 0;
}
0x04 二分
AcWing102. 最佳牛围栏
简化题意为在数组 中找到一个长度不小于 的连续子段,且该子段平均值最大。
二分答案,将问题转换为判断平均值 是否合法,即是否存在长度不小于 的连续子段的平均值 。
我们先把 中的每一个数都减去 ,问题再次转换为是否存在长度不小于 的连续子段的总和 。
考虑前缀和,。朴素地可以枚举子段的两端点,运用前缀和进行计算。
但这种做法一定会超时,我们考虑优化。
我们先把答案表示出来。
我们可以发现 每增加 , 也只会增加 ,所以我们不用每次都枚举 ,可以维护 的最小值 ,然后判断当前的 是否 即可。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010;
int n, L;
int a[N];
double s[N];
bool check(double x) {
for (int i = 1; i <= n; i ++) s[i] = a[i] - x;
for (int i = 1; i <= n; i ++) s[i] += s[i - 1];
double minn = 0x3f3f3f3f;
for (int i = 0, j = L; j <= n; i ++, j ++) {
minn = min(minn, s[i]);
if (s[j] - minn >= 0) return true;
}
return false;
}
int main() {
double l = 0, r = 0;
scanf("%d%d", &n, &L);
for (int i = 1; i <= n; i ++) {
scanf("%d", &a[i]);
r = max(r, (double)(a[i]));
}
while (r - l > 1e-6) {
double mid = (l + r) / 2;
if (check(mid)) l = mid;
else r = mid;
}
printf("%d\n", (int)(r * 1000));
return 0;
}
AcWing113. 特殊排序
假设当前已经排好了 的顺序,考虑当前第 个元素应该插入的位置。
我们可以二分插入位置 ,如果 比 小,那么 , 否则 。
可以证明如此二分一定能成功插入,证明如下:
如果第 个元素比第 个元素小,那么我们可以寻找第 个元素。如果第 个元素比第 个元素大,那么第 个元素就插入到 和 之间;否则我们就继续往前找,直到第 个元素,如果比第 个元素小,那我们就插在第 个元素前面。
反之,若第 个元素大于第 个元素,同上亦可证明。
虽然我们二分时不会像上方一个一个枚举,但也足够证明二分的正确性。
// Forward declaration of compare API.
// bool compare(int a, int b);
// return bool means whether a is less than b.
class Solution {
public:
vector<int> specialSort(int N) {
vector<int> res(1, 1);
for (int i = 2; i <= N; i ++) {
int l = 0, r = res.size() - 1;
while (l < r) {
int mid = l + r + 1 >> 1;
if (compare(res[mid], i)) l = mid;
else r = mid - 1;
}
res.push_back(i);
for (int j = res.size() - 2; j > r; j --) swap(res[j], res[j + 1]);
if (compare(i, res[r])) swap(res[r], res[r + 1]);
}
return res;
}
};
0x05 排序
AcWing103. 电影
使用 存储每种语言能使多少个人开心,接着把每台电影语言和字幕让人开心的数量存入结构体 中,接着以语言为主要,字幕为次要从大到小排序,v[1] 就是答案。
由于题目要求输出编号,所以还要加入 存储电影序号。
#include <iostream>
#include <algorithm>
#include <map>
using namespace std;
const int N = 200010;
int n, m;
int a[N], b[N], c[N];
map<int, int> h;
struct node {
int x, y, id;
} v[N];
bool cmp(node a, node b) {
return a.x > b.x || a.x == b.x && a.y > b.y;
}
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; i ++) {
scanf("%d", &a[i]);
h[a[i]] ++;
}
scanf("%d", &m);
for (int i = 1; i <= m; i ++) scanf("%d", &b[i]);
for (int i = 1; i <= m; i ++) scanf("%d", &c[i]);
for (int i = 1; i <= m; i ++)
v[i] = {h[b[i]], h[c[i]], i};
sort(v + 1, v + 1 + m, cmp);
printf("%d\n", v[1].id);
return 0;
}
AcWing104. 货仓选址
超级经典的初中数学题。
现将 从小到大进行排序,设货仓建在 , 左侧有 家店,右侧有 家店。
- 如果 ,那么 每右移一个单位长度,距离之和就会变小
- 如果 ,那么 每左移一个单位长度,距离之和就会变小
所以,我们应该将店设在最中间,即中位数。具体地,如果 是奇数,那货仓就建在 处;如果 是偶数,那货仓就可以建在 上的任意位置。
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 100010;
int n, a[N];
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; i ++) scanf("%d", &a[i]);
sort(a + 1, a + 1 + n);
int m = (1 + n) / 2;
long long ans = 0;
for (int i = 1; i <= n; i ++) ans += abs(a[i] - a[m]);
printf("%d\n", ans);
return 0;
}
AcWing105. 七夕祭
首先我们可以发现,我们只会交换相邻的两个数,所以我们可以把行和列分开来做。
接着考虑对于数组 的最小交换次数。
先思考当前 和 不能互相交换的情况。
由于最后 中的每个数都要变为 的平均值 ,所以我们记 ,然后我们用一个前缀和数组 ,记录 的前缀和。
那么 即为答案。
为什么是这样的呢?我们可以举一个例子。
发现了吗? 记录了 应该被 给 ,但是 本身就是 ,又要考虑给 的问题,所以 总共需要 给它 , 同理,需要 的 。到了 ,它本身拥有 ,所以还需要 给它 。
这样子我们就可以不重不漏地计算出答案。
回到本题,从上述做法的线性改为了环形。注意到(注意力惊人)一定存在最优解不是环而是链,所以我们可以枚举环的断点,用链的做法去做。
证明如下:
来自 @AcWing 东边的西瓜皮
我们假设断点为 ,那么原前缀和序列的顺序就成了 ,我们考虑修改过后的前缀和数组,即为 。
由于 为 ,所以
所以我们要找出使得 最小的 即可。这很明显是货仓选址问题,所以
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 100010;
int n, m, T;
int row[N], col[N];
int a[N], b[N];
int main() {
scanf("%d%d%d", &n, &m, &T);
while (T --) {
int x, y;
scanf("%d%d", &x, &y);
row[x] ++, col[y] ++;
}
int averow = 0, avecol = 0;
for (int i = 1; i <= n; i ++) averow += row[i];
for (int i = 1; i <= m; i ++) avecol += col[i];
bool f1 = true, f2 = true;
if (averow % n != 0) f1 = false;
if (avecol % m != 0) f2 = false;
if (!f1 && !f2) {
printf("impossible");
return 0;
} else if (!f1) {
printf("column ");
} else if (!f2) {
printf("row ");
} else {
printf("both ");
}
long long ans = 0;
if (f1) {
averow /= n;
a[1] = 0;
for (int i = 2; i <= n; i ++) a[i] = a[i - 1] + row[i] - averow;
sort(a + 1, a + 1 + n);
long long res = 0;
for (int i = 1; i <= n; i ++)
res += abs(a[i] - a[n + 1 >> 1]);
ans += res;
}
if (f2) {
avecol /= m;
b[1] = 0;
for (int i = 2; i <= m; i ++) b[i] = b[i - 1] + col[i] - avecol;
sort(b + 1, b + 1 + m);
long long res = 0;
for (int i = 1; i <= m; i ++)
res += abs(b[i] - b[m + 1 >> 1]);
ans += res;
}
printf("%lld\n", ans);
return 0;
}
AcWing106. 动态中位数
对顶堆算法。
用一个大根堆和一个小根堆来维护数据,做法是如果新加入的数据大于大根堆的堆顶,就把它加入小根堆,否则加入大根堆。
加入完后,我们还要对大根堆和小根堆进行维护,使得大根堆长度为小根堆长度加一。
我们只要在 为奇数时访问大根堆的堆顶即可。
#include <iostream>
#include <cstring>
#include <algorithm>
#include <queue>
using namespace std;
const int N = 100010;
int T, p, n;
int a[N];
int main() {
scanf("%d", &T);
while (T --) {
scanf("%d%d", &p, &n);
printf("%d %d\n", p, (n + 1) / 2);
int cnt = 0;
priority_queue<int> down;
priority_queue<int, vector<int>, greater<int>> up;
for (int i = 1; i <= n; i ++) {
int x; scanf("%d", &x);
if (down.empty() or x <= down.top()) down.push(x);
else up.push(x);
if (down.size() > up.size() + 1) up.push(down.top()), down.pop();
if (up.size() > down.size()) down.push(up.top()), up.pop();
if (i & 1) {
printf("%d ", down.top());
cnt ++;
if (cnt % 10 == 0) puts("");
}
}
if (cnt % 10) puts("");
}
return 0;
}
AcWing108. 奇数码问题
考虑将二维数组写成类似 的形式,则此时左右交换不会影响此序列。上下交换,比如交换 和 ,则会增加两个逆序对。我们可以拓展到 的矩阵中,即上下交换会增加 个逆序对。
因为 是奇数,所以 一定是偶数,所以如果初始序列有奇数个逆序对,则不论我们怎么操作,最终都只有奇数个逆序对,反之亦然。
所以我们可以分别计算输入序列和答案序列的逆序对,判断它们的奇偶性是否相同。
#include <iostream>
#include <cstring>
#include <algorithm>
#include <cstdio>
using namespace std;
typedef long long LL;
const int N = 500010;
int n, q[N], tmp[N];
LL merge_sort(int l, int r)
{
if (l >= r) return 0;
int mid = l + r >> 1;
LL res = merge_sort(l, mid) + merge_sort(mid + 1, r);
int k = 0, i = l, j = mid + 1;
while (i <= mid && j <= r)
if (q[i] <= q[j]) tmp[k ++] = q[i ++];
else
{
tmp[k ++] = q[j ++];
res += mid - i + 1;
}
while (i <= mid)
tmp[k ++] = q[i ++];
while (j <= r)
tmp[k ++] = q[j ++];
for (int i = l, j = 0; i <= r; i ++, j ++)
q[i] = tmp[j];
return res;
}
int main()
{
while (cin >> n) {
int len = 0;
for (int i = 1; i <= n * n; i ++) {
int x; cin >> x;
if (x) q[len ++] = x;
}
LL res1 = merge_sort(0, n * n - 2);
len = 0;
for (int i = 1; i <= n * n; i ++) {
int x; cin >> x;
if (x) q[len ++] = x;
}
LL res2 = merge_sort(0, n * n - 2);
if ((res1 & 1) == (res2 & 1)) puts("TAK");
else puts("NIE");
}
return 0;
}
0x06 排序
AcWing 109.天才ACM
倍增。
最开始 ,然后进行如下操作:
- 定义变量
- 循环判断 的校验值是否小于等于 。
- 如果是,
r += p, p *= 2 - 如果不是,
p /= 2
- 如果是,
- 当 时,退出循环,让
接着我们考虑如何判断校验值是否小于等于 。
一个显而易见的结论是,如果序列 是从小到大排序的,那么校验值就应该是
即先让最大值和最小值凑一对,然后是次大和次小,并且我们配的对数量要小于 。
所以,假设当前要计算 的最大值,我们只要将 从小到大排序,做如上操作即可。
分析下时间复杂度,设每个答案的长度为 ,那么对于每个 ,需要倍增 。
那么总共的答案就是
这个复杂度是一定会超时的,所以我们需要优化。
注意到在处理 时,已经把 排好了序,所以我们在处理 时就不用
重新排序,只要将 排序,然后和 进行归并即可。
这种思路下只需要将每个区间处理一次,时间复杂度就是 ,可以通过本题。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
typedef long long LL;
const int N = 500010;
int T, n, m;
LL t;
int w[N], b[N], tmp[N];
bool check(int l, int mid, int r) {
int k = 0;
for (int i = mid; i < r; i ++) b[i] = w[i];
sort(b + mid, b + r);
int i = l, j = mid;
while (i < mid && j < r)
if (b[i] < b[j]) tmp[k ++] = b[i ++];
else tmp[k ++] = b[j ++];
while (i < mid) tmp[k ++] = b[i ++];
while (j < r) tmp[k ++] = b[j ++];
LL res = 0;
for (int i = 0; i < m && i < k; i ++, k --)
res += (LL)(tmp[k - 1] - tmp[i]) * (tmp[k - 1] - tmp[i]);
return res <= t;
}
int main() {
scanf("%d", &T);
while (T --) {
scanf("%d%d%lld", &n, &m, &t);
for (int i = 0; i < n; i ++) scanf("%d", &w[i]);
int l = 0, cnt = 0;
while (l < n) {
int r = l, p = 1;
while (p) {
if (r + p <= n && check(l, r, r + p)) {
r += p;
p <<= 1;
for (int i = l; i < r; i ++)
b[i] = tmp[i - l];
} else {
p >>= 1;
}
}
cnt ++;
l = r;
}
printf("%d\n", cnt);
}
return 0;
}
0x07 贪心
AcWing1055. 股票买卖
考虑当前是第 天,分两种情况。
- 当前持有股票,则若下一天是涨,我们肯定会把股票留着,否则,我们应该直接卖出。
- 当前未持有股票,如果下一天涨,我们应该在今天买入,否则不应该买入。
所以可以得到
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010;
int n, w[N];
int f[N][2];
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; i ++) scanf("%d", &w[i]);
int res = 0;
for (int i = 2; i <= n; i ++)
res += max(w[i] - w[i - 1], 0);
printf("%d\n", res);
return 0;
}
AcWing110. 防晒
首先把每一头牛可接受的光线按 为第一关键字, 为第二关键字,从大到小排序。
接着分别枚举每头牛可用的防晒霜,对于每头牛选择 最大的防晒霜。
证明:
首先,对于每一罐防晒霜 ,因为我们已经按照 进行了排序,所以如果
防晒霜 ,大于 ,则它一定大于 ~ 。
那么对于一头奶牛 与防晒霜 和 来说,只有以下三种情况:
- 能用, 能用
- 能用, 不能用
- 不能用, 不能用
所以 的适用范围比 更广,故而我们应该尽可能先使用 ,实在不行再考虑 。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
typedef pair<int, int> PII;
const int N = 2510;
int c, l;
PII w[N];
int spf[N], cov[N];
int main() {
scanf("%d%d", &c, &l);
for (int i = 1; i <= c; i ++)
scanf("%d%d", &w[i].first, &w[i].second);
for (int i = 1; i <= l; i ++)
scanf("%d%d", &spf[i], &cov[i]);
sort(w + 1, w + 1 + c, [&](PII a, PII b) {
return a.first > b.first;
});
int ans = 0;
for (int i = 1; i <= c; i ++) {
int sel = 0;
for (int j = 1; j <= l; j ++) {
if (w[i].first <= spf[j] && spf[j] <= w[i].second && cov[j] && spf[j] > spf[sel])
sel = j;
}
if (sel) ans ++, cov[sel] --;
}
printf("%d\n", ans);
return 0;
}
AcWing111. 畜栏预定
首先对于每头牛,按照吃草的开始时间排序,然后从前到后考虑每只牛,用一个小根堆来枚举当前结束时间最早的畜栏。
对于一头牛,如果它吃草的开始时间比小根堆里所有的结束时间都早(即早于堆顶),就要新开辟一个畜栏。
否则,我们应该将其放入当前任意可放入的畜栏,方便起见,放入堆顶。
证明(来自 ,非常精妙):
反证法,假设存在一种方案,使得需要的畜栏数量更少,记其需要的畜栏数量是 。
考虑在上述做法中,第一次新建第 个畜栏的时刻,不妨设当前处理的是第 头牛。
由于所有牛是按开始时间从小到大排好序的,所以现在前 个畜栏中最后一头牛的开始时间一定小于等于第
头牛的开始时间。
而且前 个畜栏中最小的结束时间大于等于第 头牛的开始时间,所以前
个畜栏里最后一头牛的吃草区间一定都包含第 头牛的开始时间,所以我们就找到了
个区间存在交集,所以至少需要 个畜栏,矛盾。
所以上述做法可以得到最优解,证毕。
#include <iostream>
#include <cstring>
#include <algorithm>
#include <queue>
using namespace std;
typedef pair<int, int> PII;
const int N = 50010;
int n, cnt;
int ans[N];
priority_queue<PII, vector<PII>, greater<PII>> q;
struct node {
int l, r, id;
} w[N];
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; i ++)
scanf("%d%d", &w[i].l, &w[i].r);
for (int i = 1; i <= n; i ++)
w[i].id = i;
sort(w + 1, w + 1 + n, [&](node a, node b) {
return a.l < b.l;
});
int res = 0;
for (int i = 1; i <= n; i ++) {
if (q.empty() || w[i].l <= q.top().first) {
q.push({w[i].r, ++ res});
ans[w[i].id] = res;
} else {
PII t = q.top(); q.pop();
q.push({w[i].r, t.second});
ans[w[i].id] = t.second;
}
}
printf("%d\n", res);
for (int i = 1; i <= n; i ++)
printf("%d\n", ans[i]);
return 0;
}
AcWing112. 雷达设备
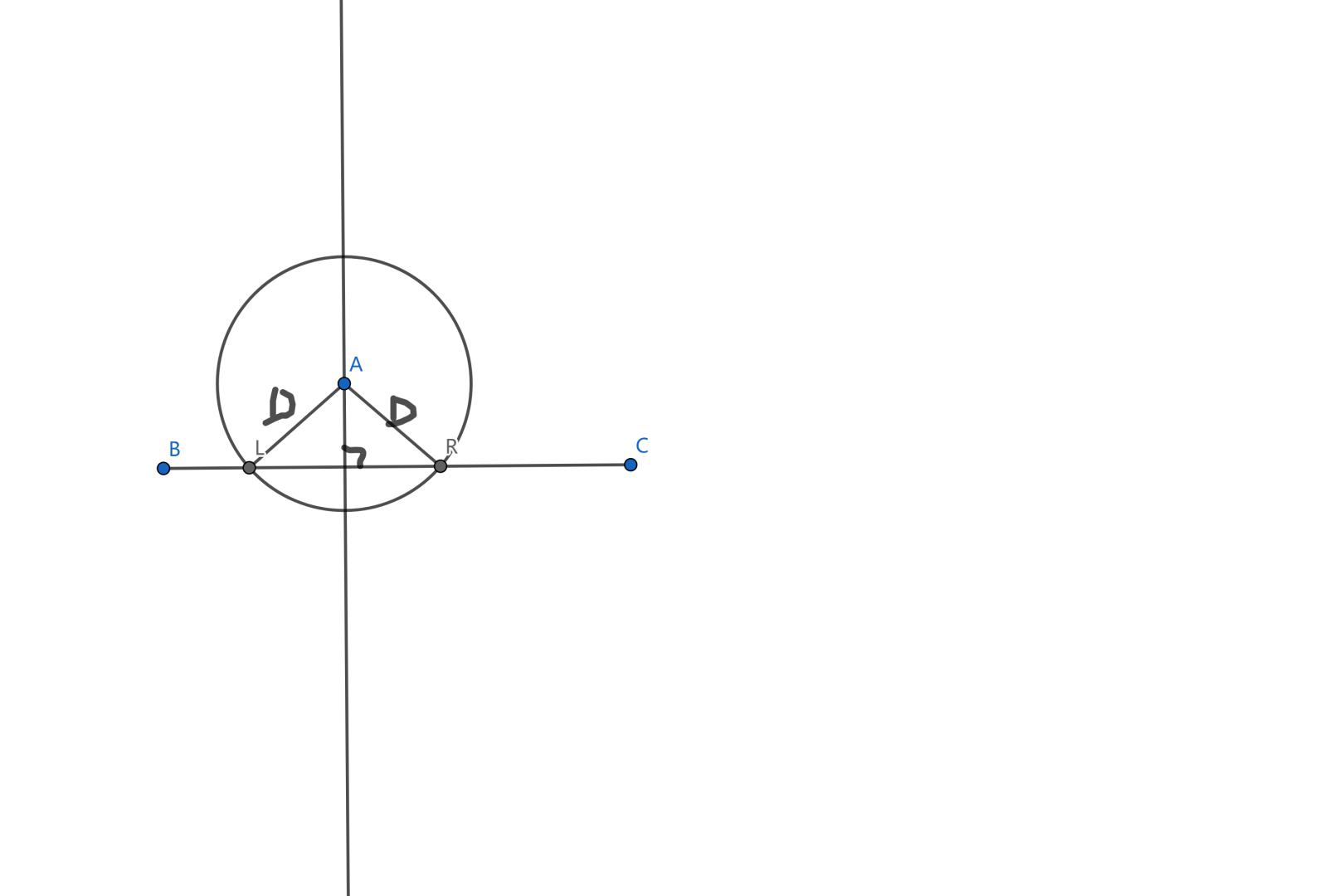
如图,我们求出对于每个点 ,能覆盖它的范围 ,根据勾股定理我们可以得到:
于是问题就转化成了,给定 个区间,在 上找尽量少的点,使每个区间内至少有一个点。
这就是 AcWing905. 区间选点,模板题。
我们把每个区间按 排序,对于每个区间:
- 如果区间内已经有了点,就跳过这个区间。
- 如果区间内没有点,就在区间的右端点找点。
正确性显然,不予证明。
#include <iostream>
#include <cstring>
#include <algorithm>
#include <cmath>
using namespace std;
typedef pair<double, double> PDD;
const int N = 1010;
int n, d;
PDD q[N];
PDD calc(int x, int y) {
if (d * d < y * y) return {0x3f3f3f3f, 0x3f3f3f3f};
double l = x - sqrt(d * d - y * y);
double r = x + sqrt(d * d - y * y);
return {l, r};
}
int main() {
scanf("%d%d", &n, &d);
for (int i = 1; i <= n; i ++) {
int x, y;
scanf("%d%d", &x, &y);
q[i] = calc(x, y);
if (q[i].first == 0x3f3f3f3f) {
puts("-1");
return 0;
}
}
sort(q + 1, q + 1 + n, [&](PDD a, PDD b) {
return a.second < b.second;
});
int cnt = 0;
double ed = -0x3f3f3f3f;
for (int i = 1; i <= n; i ++) {
if (ed < q[i].first) {
cnt ++;
ed = q[i].second;
}
}
printf("%d\n", cnt);
return 0;
}
AcWing114. 国王游戏
作法:把所有人按照 从小到大排序,然后循环找最大值。
证明:
假设当前有两个人 和 ,考虑如果排序前和排序后的答案。
这里假设国王为 号大臣。
-
排序前,即
此时大臣 的奖赏是:
此时大臣 的奖赏是:
-
排序后,即
此时大臣 的奖赏是:
此时大臣 的奖赏是:
把每个式子都提取公因式 ,再乘上 ,
转为求: 与 的最大值
通过推导可以得出,当 时,交换前更优;
反之,交换后更优。所以无论如何我们都应该按照 排序。
要写高精度。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
typedef pair<int, int> PII;
#define x first
#define y second
const int N = 1010, M = 4010;
int n;
PII w[N];
void mul(int a[], int b) {
for (int i = 0, t = 0; i < M; i ++) {
t += a[i] * b;
a[i] = t % 10;
t /= 10;
}
}
void div(int c[], int a[], int b) {
for (int i = M - 1, r = 0; i >= 0; i --) {
r = r * 10 + a[i];
c[i] = r / b;
r %= b;
}
}
int compare(int a[], int b[]) {
for (int i = M - 1; i >= 0; i --)
if (a[i] > b[i]) return 1;
else if (a[i] < b[i]) return -1;
return 0;
}
void print(int a[]) {
int l = M - 1;
while (a[l] == 0 && l > 0) l --;
for (int i = l; i >= 0; i --)
printf("%d", a[i]);
}
int main() {
scanf("%d", &n);
for (int i = 0; i <= n; i ++)
scanf("%d%d", &w[i].x, &w[i].y);
sort(w + 1, w + 1 + n, [&](PII a, PII b) {
return a.x * a.y < b.x * b.y;
});
int tmp[M], p[M] = {1}, res[M] = {0};
for (int i = 1; i <= n; i ++) {
mul(p, w[i - 1].x);
div(tmp, p, w[i].y);
if (compare(res, tmp) == -1)
memcpy(res, tmp, sizeof tmp);
}
print(res);
return 0;
}
AcWing115. 给树染色
首先我们考虑没有限制的情况,那我们从大到小来取,现在有了限制,我们照样可以利用类似的思路。
假设当前最大值为 ,它的父节点为 ,那么 和 取的顺序一定是相邻的,所以我们可以把它们当作一个点来做。
那么如果现在又有一个点 ,那我们有两种染法:
- 先 ,再 :
- 先 ,再 :
我们考虑作差:
所以当 时 我们应该先染式子右边,否则先染式子左边。
我们考虑是否能把其拓展为两个序列。
假设有两个序列 和 。
与之相似我们也有两种染法:
作差:
所以当 时,
,反之亦然。
因此,我们可以把 序列和 序列看作点权为 的平均值和 的平均值的两个点。
我们最后的做法是:每次寻找当前树上的最大值,然后找到它的父亲,在合并顺序中把最大值跟在父亲的后面,最后用最大值的点权更新父亲。
考虑如何计算这种合并方式的代价。
首先最开始先加上每个点的点权。对于当前要合并的 和 ,如果把 放在 的后面,就代表一整个 都要加上一个偏移量 。
由以上推导可以发现,偏移量其实就是 中点的数量,所以代价就应该加上 中点的数量乘以 中点权的总和。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 1010;
int n, root;
struct Node {
int p, s, size;
double avg;
} nodes[N];
int find() {
int res = 0;
for (int i = 1; i <= n; i ++)
if (i != root && nodes[i].avg > nodes[res].avg)
res = i;
return res;
}
int main() {
int ans = 0;
scanf("%d%d", &n, &root);
for (int i = 1; i <= n; i ++) {
scanf("%d", &nodes[i].s);
nodes[i].avg = nodes[i].s;
nodes[i].size = 1;
ans += nodes[i].s;
}
for (int i = 1; i < n; i ++) {
int u, v;
scanf("%d%d", &u, &v);
nodes[v].p = u;
}
for (int i = 1; i < n; i ++) {
int p = find();
int fa = nodes[p].p;
ans += nodes[fa].size * nodes[p].s;
for (int j = 1; j <= n; j ++)
if (nodes[j].p == p)
nodes[j].p = fa;
nodes[fa].size += nodes[p].size;
nodes[fa].s += nodes[p].s;
nodes[fa].avg = (double)nodes[fa].s / nodes[fa].size;
nodes[p].avg = -1;
}
printf("%d\n", ans);
return 0;
}
习题
AcWing116. 飞行员兄弟
由于每个把手最多只可能进行一次操作,所以我们可以枚举每个把手是否操作。
为了方便枚举,我们可以把 当成 , 当成 ,然后二进制枚举 到 ,然后判断该操作是否合法。
假设对于 的 进行了操作,那么我们应该把第 位进行改变。
我们可以预处理出一个 表示对于第 行的所有数 ,令 ,同样的再预处理出维护列的 ,那么如果我们对第 位进行了操作,那么我们只需要做 t ^= row[i / 4] + col[i % 4] - (1 << i) 即可。
时间复杂度为:
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 10, M = 16;
int g, ans = 0x3f3f3f3f, ansg;
int row[N], col[N];
int check(int state) {
int ans = 0, t = g;
for (int i = 0; i < M; i ++)
if (state >> i & 1) {
ans ++;
int change = row[i / 4] + col[i % 4] - (1 << i);
t ^= change;
}
for (int i = 0; i < M; i ++)
if (t >> i & 1) ans = 0x3f3f3f3f;
return ans;
}
int main() {
for (int i = 0; i < 4; i ++)
for (int j = 0; j < 4; j ++)
row[i] |= (1 << (i * 4 + j));
for (int j = 0; j < 4; j ++)
for (int i = 0; i < 4; i ++)
col[j] |= (1 << (i * 4 + j));
for (int i = 0; i < 4; i ++)
for (int j = 0; j < 4; j ++) {
char c; cin >> c;
if (c == '+') g |= 1 << (i * 4 + j);
}
for (int i = 0; i < 1 << M; i ++) {
int r = check(i);
if (ans > r) ans = r, ansg = i;
}
cout << ans << endl;
for (int i = 0; i < M; i ++)
if (ansg >> i & 1)
cout << i / 4 + 1 << ' ' << i % 4 + 1 << endl;
return 0;
}
AcWing117. 占卜DIY
双端队列模拟,没什么好写的。
#include <iostream>
#include <cstring>
#include <algorithm>
#include <queue>
using namespace std;
const int N = 15;
deque<int> q[15];
int cnt[N];
int main() {
for (int i = 1; i <= 13; i ++) {
for (int j = 1; j <= 4; j ++) {
char c; cin >> c;
if (c == 'J') q[i].push_back(11);
else if (c == 'Q') q[i].push_back(12);
else if (c == 'K') q[i].push_back(13);
else if (c == 'A') q[i].push_back(1);
else q[i].push_back(c == '0' ? 10 : c - '0');
}
}
int die = 0, u = q[13].front();
q[13].pop_front();
while (die < 4) {
if (u == 13) {
die ++;
u = q[13].front();
q[13].pop_front();
continue;
}
q[u].push_front(u);
int now = u;
u = q[u].back();
q[now].pop_back();
if (cnt[now] < 4) cnt[now] ++;
}
int res = 0;
for (int i = 1; i <= 13; i ++)
res += cnt[i] == 4;
cout << res << endl;
return 0;
}
AcWing118. 分形
找规律,我们可以发现第 层一共有 行,并且可以用五个上一层的图形进行拼接而成。
我们找到每个图形的左上角坐标,分别为
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 800;
char g[N][N][8];
int pow3(int x) {
int res = 1;
for (int i = 1; i <= x; i ++) res *= 3;
return res;
}
void work(int k, int x1, int y1) {
for (int i = 1; i <= pow3(k - 2); i ++)
for (int j = 1; j <= pow3(k - 2); j ++)
g[x1 + i - 1][y1 + j - 1][k] = g[i][j][k - 1];
}
int main() {
for (int k = 1; k <= 7; k ++)
for (int i = 1; i <= pow3(k - 1); i ++)
for (int j = 1; j <= pow3(k - 1); j ++)
g[i][j][k] = ' ';
g[1][1][1] = 'X';
for (int i = 2; i <= 7; i ++) {
work(i, 1, 1);
work(i, 1, pow3(i - 2) * 2 + 1);
work(i, pow3(i - 2) + 1, pow3(i - 2) + 1);
work(i, pow3(i - 2) * 2 + 1, 1);
work(i, pow3(i - 2) * 2 + 1, pow3(i - 2) * 2 + 1);
}
int n;
while (cin >> n && ~n) {
for (int i = 1; i <= pow3(n - 1); i ++, puts(""))
for (int j = 1; j <= pow3(n - 1); j ++)
printf("%c", g[i][j][n]);
puts("-");
}
return 0;
}
AcWing119. 袭击
如上图,我们可以把区间根据 分为两个部分,这样我们只要能够求出从 中选出一个点和从 中选出一个点的最小距离。
首先,我们令当前最小距离 ,如下图
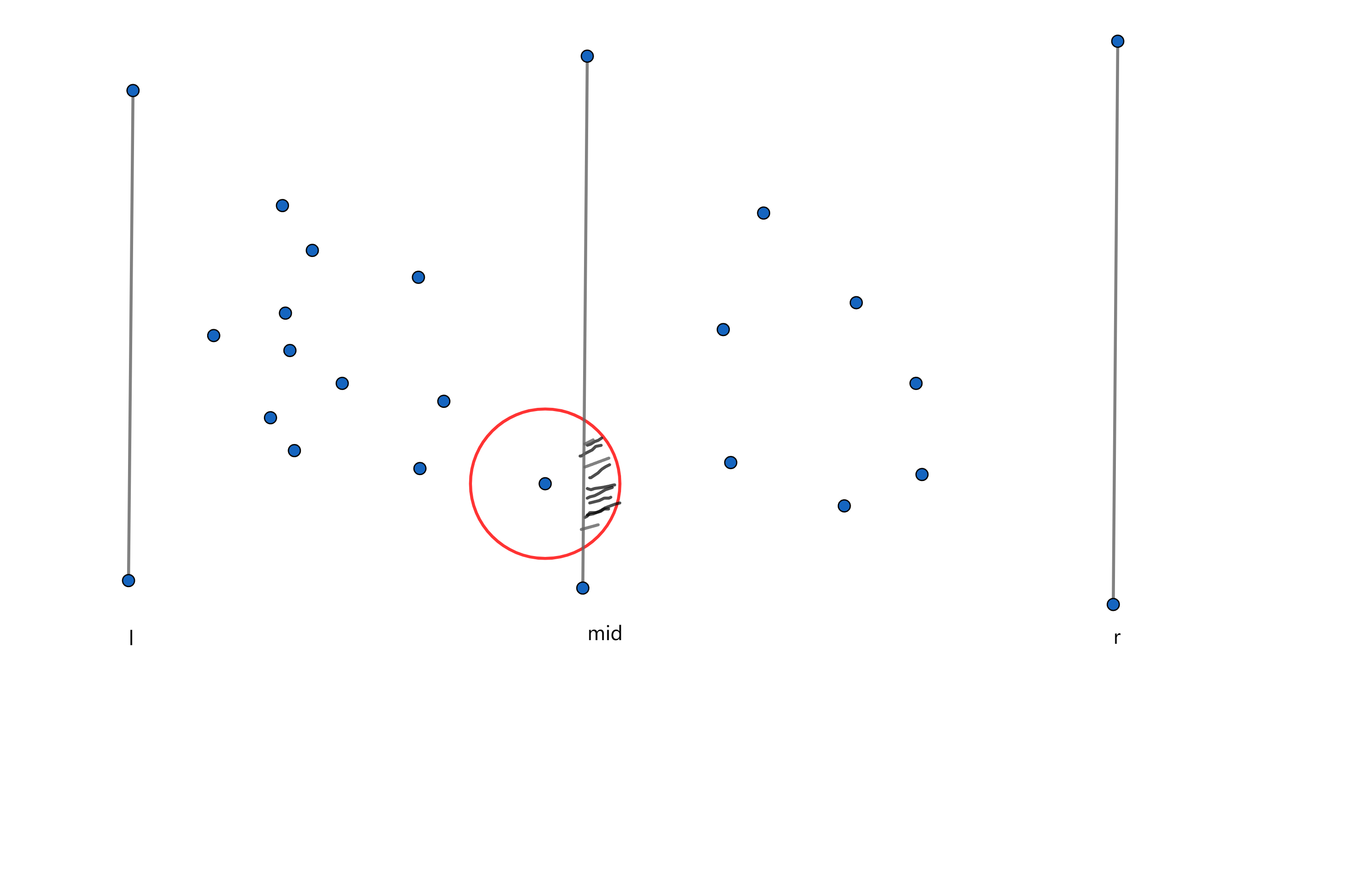
我们只需要求出阴影范围内的点即可。
这里有一个性质:对于一个左边的点,右边最多只有 个点会被考虑。
证明:如下图。
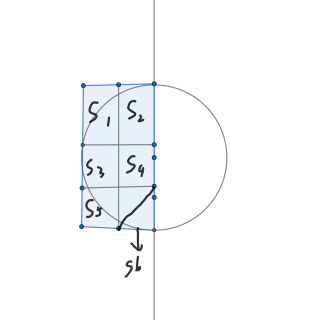
假设当前有 个点被考虑,那么根据抽屉原理,一定会有两个点在同一个格子里。我们发现大长方形的宽为 ,长为 ,所以小长方形的长为 ,宽为 ,那么在长方形内部的最长距离也就是对角线长度为 ,所以不可能有 个点。
所以我们每次枚举会枚举 个点,复杂度为 ,总复杂度为
由于一些奇怪的有序的数据会使我们的 退化成 ,所以我们要在排序前先打乱一下数组。
#include <iostream>
#include <cstring>
#include <algorithm>
#include <cmath>
using namespace std;
const int N = 200010, INF = 0x3f3f3f3f;
int T, n, m;
double ans;
struct node {
double x, y;
int type;
} points[N], tmp[N];
double dist(node a, node b) {
if (a.type == b.type) return INF;
return sqrt((a.x - b.x) * (a.x - b.x) + (a.y - b.y) * (a.y - b.y));
}
double dfs(int l, int r) {
if (l == r) return INF;
int mid = l + r >> 1;
double midx = points[mid].x;
double res = min(dfs(l, mid), dfs(mid + 1, r));
int k = 0, i = l, j = mid + 1;
while (i <= mid && j <= r)
if (points[i].y < points[j].y) tmp[k ++] = points[i ++];
else tmp[k ++] = points[j ++];
while (i <= mid) tmp[k ++] = points[i ++];
while (j <= r) tmp[k ++] = points[j ++];
for (int i = l; i <= r; i ++) points[i] = tmp[i - l];
k = 0;
for (int i = l; i <= r; i ++)
if (points[i].x >= midx - res && points[i].x <= midx + res)
tmp[k ++] = points[i];
for (int i = 0; i < k; i ++)
for (int j = i - 1; j >= 0 && tmp[i].y - tmp[j].y < res; j --)
res = min(res, dist(tmp[i], tmp[j]));
ans = min(ans, res);
return res;
}
int main() {
scanf("%d", &T);
while (T --) {
scanf("%d", &n);
for (int i = 0; i < n; i ++) {
scanf("%lf%lf", &points[i].x, &points[i].y);
points[i].type = 0;
}
for (int i = n; i < n * 2; i ++) {
scanf("%lf%lf", &points[i].x, &points[i].y);
points[i].type = 1;
}
n *= 2;
random_shuffle(points, points + n);
sort(points, points + n, [&](node a, node b){
return a.x < b.x;
});
ans = dist(points[0], points[n - 1]);
double res = dfs(0, n - 1);
printf("%.3lf\n", res);
}
return 0;
}
AcWing120. 防线
考虑到防线上最多只有一个奇数防具,所以我们可以二分,如果 的和为奇数,就代表奇数在这段区间内 ,否则 。
那么如何快速计算 的和呢?我们可以用到前缀和思想。
考虑如何计算 之间的和。
我们可以枚举每一个等差数列 ,如果 说明两个区间存在交集,那么交集应该为 。
根据小学奥数,交集内部的数量就应该为(末项-首项)/ 公差 + 1,即 。
所以 的和就等于 。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 200010;
int T, n;
int s[N];
struct node {
int s, e, d;
} p[N];
int calc(int x) {
int res = 0;
for (int i = 1; i <= n; i ++)
if (p[i].s <= x)
res += (min(p[i].e, x) - p[i].s) / p[i].d + 1;
return res;
}
int main() {
scanf("%d", &T);
while (T --) {
int l = 0x3f3f3f3f, r = -0x3f3f3f3f;
scanf("%d", &n);
for (int i = 1; i <= n; i ++) {
scanf("%d%d%d", &p[i].s, &p[i].e, &p[i].d);
l = min(l, p[i].s);
r = max(r, p[i].e);
}
if (calc(r) & 1) {
while (l < r) {
int mid = l + r >> 1;
if ((calc(mid) - calc(l - 1)) & 1) r = mid;
else l = mid + 1;
}
printf("%d %d\n", l, calc(l) - calc(l - 1));
} else {
puts("There's no weakness.");
}
}
return 0;
}
AcWing121. 赶牛入圈
先把 坐标离散化,然后计算离散化后的前缀和。接着我们考虑二分正方形边长,该二分正确性显然,因为在满足条件的情况下边长变大答案不可能更优,而不满足条件时边长一定会增大。
考虑如何写 函数。
由于我们已经预处理好了前缀和,我们就可以枚举正方形的左上角和右下角,然后通过前缀和来计算答案。一个细节是,因为四叶草的坐标是格子的左下角,所以我们在计算是要用 和 (建议画图)。
一个更细节的细节是,我们没必要一定枚举正方形,我们发现如果一个长方形的长和宽都小于等于正方形的边长,并且长方形内的四叶草数量大于等于 ,那正方形情况也一定成立。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
typedef pair<int, int> PII;
#define x first
#define y second
const int N = 1010;
int c, n;
int s[N][N];
PII p[N];
vector<int> nums;
int find(int x) {
int l = 0, r = nums.size() - 1;
while (l < r) {
int mid = l + r >> 1;
if (nums[mid] >= x) r = mid;
else l = mid + 1;
}
return l;
}
bool check(int l) {
for (int x0 = 0, x1 = 1; x1 < nums.size(); x1 ++) {
while (nums[x1] - nums[x0 + 1] + 1 > l) x0 ++;
for (int y0 = 0, y1 = 1; y1 < nums.size(); y1 ++) {
while (nums[y1] - nums[y0 + 1] + 1 > l) y0 ++;
if (s[x1][y1] - s[x1][y0] - s[x0][y1] + s[x0][y0] >= c)
return true;
}
}
return false;
}
int main() {
scanf("%d%d", &c, &n);
nums.push_back(0);
for (int i = 1; i <= n; i ++) {
scanf("%d%d", &p[i].x, &p[i].y);
nums.push_back(p[i].x);
nums.push_back(p[i].y);
}
sort(nums.begin(), nums.end());
nums.erase(unique(nums.begin(), nums.end()), nums.end());
for (int i = 1; i <= n; i ++) {
int x = find(p[i].x), y = find(p[i].y);
s[x][y] ++;
}
for (int i = 1; i < nums.size(); i ++)
for (int j = 1; j < nums.size(); j ++)
s[i][j] += s[i - 1][j] + s[i][j - 1] - s[i - 1][j - 1];
int l = 1, r = 10000;
while (l < r) {
int mid = l + r >> 1;
if (check(mid)) r = mid;
else l = mid + 1;
}
printf("%d\n", l);
return 0;
}
AcWing122. 糖果传递
七夕祭缩减版。推导过程不再写了。
#include <iostream>
#include <cstring>
#include <algorithm>
typedef long long LL;
using namespace std;
const int N = 1000010;
int n, a[N], w[N], s[N];
int main() {
scanf("%d", &n);
LL avg = 0;
for (int i = 1; i <= n; i ++) {
scanf("%d", &a[i]);
avg += a[i];
}
avg /= n;
for (int i = 1; i <= n; i ++)
w[i] = a[i] - avg;
for (int i = 1; i <= n; i ++)
s[i] = s[i - 1] + w[i];
sort(s + 1, s + 1 + n);
int k = n + 1 >> 1;
long long res = 0;
for (int i = 1; i <= n; i ++)
res += abs(s[i] - s[k]);
printf("%lld\n", res);
return 0;
}
AcWing123. 士兵
很容易发现我们可以把 和 分开来做。
首先考虑 轴,排序后就是货仓选址。
再考虑 轴,此处有一个性质是最优情况下,排序后士兵间的相对顺序和最后走到最终位置的相对顺序不会改变。
比如最左边的点走到 ,则第 个人走到 。
所以第 个士兵(设其坐标为 )要走的距离就是
所以问题又变为了货仓选址,我们只需要给每个 即可。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
typedef pair<int, int> PII;
#define x first
#define y second
const int N = 10010;
int n, c[N];
PII p[N];
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; i ++)
scanf("%d%d", &p[i].x, &p[i].y);
sort(p + 1, p + 1 + n, [&](PII a, PII b) {
return a.y < b.y;
});
int k = p[n + 1 >> 1].y;
int res = 0;
for (int i = 1; i <= n; i ++)
res += abs(p[i].y - k);
sort(p + 1, p + 1 + n, [&](PII a, PII b) {
return a.x < b.x;
});
for (int i = 1; i <= n; i ++)
p[i].x -= i - 1;
sort(p + 1, p + 1 + n, [&](PII a, PII b) {
return a.x < b.x;
});
k = p[n + 1 >> 1].x;
for (int i = 1; i <= n; i ++) {
res += abs(p[i].x - k);
}
printf("%d\n", res);
return 0;
}
AcWing124. 数的进制转换
高精度 + 模拟进制转换,没什么好写的,注意细节就行了。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 500;
int n, m, T;
string s, t;
int get(char c) {
if (c >= '0' && c <= '9') return c - '0';
else if (c >= 'A' && c <= 'Z') return c - 'A' + 10;
else return c - 'a' + 36;
}
char reget(int c) {
if (c <= 9) return c + '0';
else if (c < 36) return c - 10 + 'A';
else return c - 36 + 'a';
}
vector<int> div(vector<int> A, int b, int &r) {
vector<int> C;
r = 0;
for (int i = A.size() - 1; i >= 0; i --) {
r = r * n + A[i];
C.push_back(r / b);
r %= b;
}
reverse(C.begin(), C.end());
while (C.back() == 0 && C.size() > 0) C.pop_back();
return C;
}
int main() {
cin >> T;
while (T --) {
cin >> n >> m >> s;
cout << n << ' ' << s << endl << m << ' ';
vector<int> res, ans;
for (int i = s.size() - 1; i >= 0; i --)
res.push_back(get(s[i]));
while (res.size()) {
int r;
res = div(res, m, r);
ans.push_back(r);
}
for (int i = ans.size() - 1; i >= 0; i --)
cout << reget(ans[i]);
cout << endl << endl;
}
return 0;
}
AcWing125. 耍杂技的牛
将 进行排序,证明类似国王游戏,这里不过多赘述。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 50010;
int n;
struct node {
int s, w;
} a[N];
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; i ++)
scanf("%d%d", &a[i].w, &a[i].s);
sort(a + 1, a + 1 + n, [&](node a, node b) {
return a.w + a.s < b.w + b.s;
});
long long res = -0x3f3f3f3f, sum = 0;
for (int i = 1; i <= n; i ++) {
res = max(res, sum - a[i].s);
sum += a[i].w;
}
printf("%d\n", res);
return 0;
}
AcWing126. 最大的和
我们先预处理矩阵的前缀和,朴素思路是枚举矩阵的左上角和右下角,这样时间复杂度是 。
我们考虑优化,只枚举矩阵的起始行和结尾行,即 和 ,然后用类似最长连续子段和的思路从 开始枚举列,找到最大连续列的和。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 110;
int n, g[N][N];
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; i ++)
for (int j = 1; j <= n; j ++) {
scanf("%d", &g[i][j]);
g[i][j] += g[i - 1][j];
}
int res = -0x3f3f3f3f;
for (int i = 1; i <= n; i ++)
for (int j = i; j <= n; j ++) {
int last = 0;
for (int k = 1; k <= n; k ++) {
last = max(last, 0) + g[j][k] - g[i - 1][k];
res = max(res, last);
}
}
printf("%d\n", res);
return 0;
}
AcWing127. 任务
我们发现时间对收入的影响比级别多的多的多,所以我们以时间为第一关键字,收入为第二关键字从大到小排序任务和机器。
我们从 到 枚举每个任务,接着寻找每个可以使用的机器,并且使用其中级别最小的机器。
因为任务排过序,所以如果一台机器能满足当前任务的时间,就一定能满足之后所有任务的时间,但级别却不一定满足,所以我们需要使用可行机器里级别最小的。
#include <iostream>
#include <cstring>
#include <algorithm>
#include <set>
using namespace std;
typedef long long LL;
const int N = 100010;
int n, m;
struct node {
int x, y;
} a[N], b[N];
int main() {
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i ++)
scanf("%d%d", &a[i].x, &a[i].y);
for (int i = 1; i <= m; i ++)
scanf("%d%d", &b[i].x, &b[i].y);
sort(a + 1, a + 1 + n, [&](node a, node b) {
return a.x > b.x || a.x == b.x && a.y > b.y;
});
sort(b + 1, b + 1 + m, [&](node a, node b) {
return a.x > b.x || a.x == b.x && a.y > b.y;
});
multiset<int> S;
LL res = 0, cnt = 0;
for (int i = 1, j = 1; i <= m; i ++) {
while (j <= n && b[i].x <= a[j].x)
S.insert(a[j ++].y);
auto it = S.lower_bound(b[i].y);
if (it != S.end()) {
cnt ++;
res += b[i].x * 500 + b[i].y * 2;
S.erase(it);
}
}
printf("%lld %lld\n", cnt, res);
return 0;
}



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步