
基于scrapy+mongodb的智联招聘网站信息爬取
本篇内容主要记录博主本人爬取智联招聘网站信息的过程!!
环境:python 3.6.5
pycharm JetBrains PyCharm Community Edition 2018.1 x64
Mongodb 4.0.0
1.第一步当然是创建一个新的爬虫啦
scrapy crawl xxxx #爬虫名字
2.解析网站
进入到智联首页https://www.zhaopin.com/,点击搜索(以搜索python为例),得到信息列表按F12打开调试器

一开始我单纯的以为在Elements(查看器)获取所有信息足矣
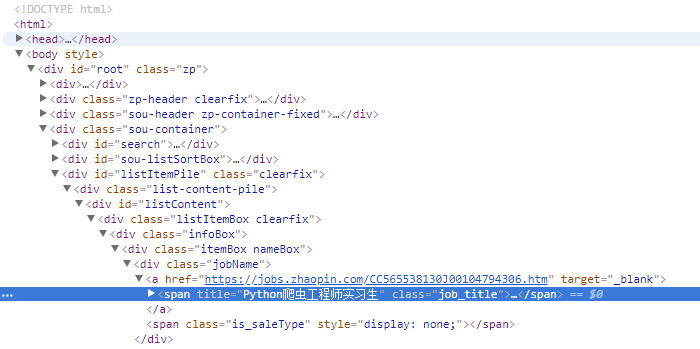
让我满怀欢喜的把整个网页爬取下来,然后分析,发现要搜索上图标签//*[@id="listContent"]/div[1]/div[1]/div[1]/div[1]/a/span竟然啥没有,不信你打开网页源代码试试。
这是因为,生成的信息是通过异步加载出来的,所以要分析的话要通过Network来获取异步加载信息
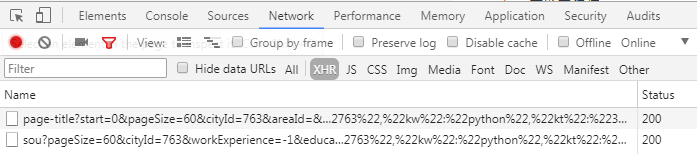
点击上面的第二条链接,你会发现,所有信息都被藏在里面了
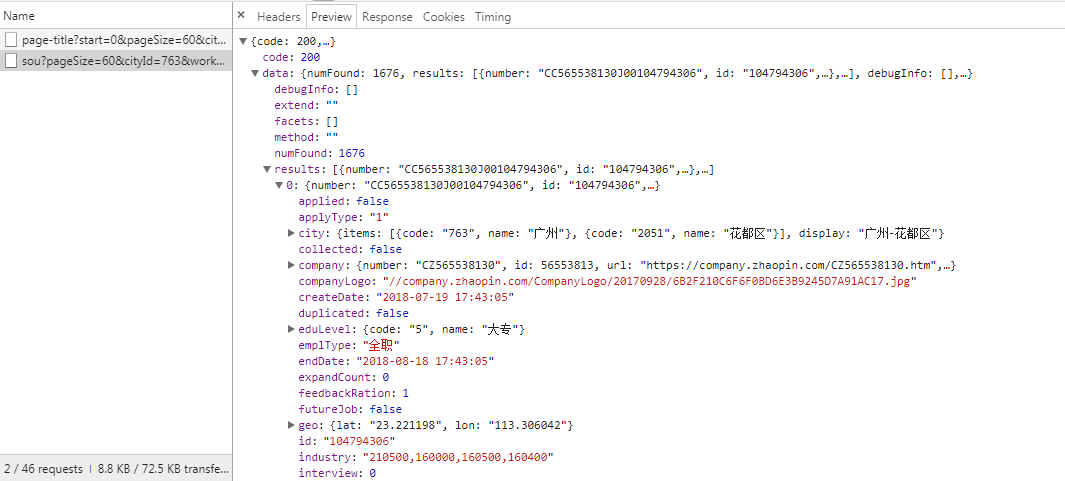
有了这些json格式的信息,就可以用xpath或者re来构造需要的信息。
还有一点就是实现翻页,拉到最底部点击第二页和第三页。会发现调试器又出现了四条链接与刚才的一样,对比下两条sou开头的链接
1.https://fe-api.zhaopin.com/c/i/sou?pageSize=60&cityId=763&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&lastUrlQuery=%7B%22jl%22:%22763%22,%22kw%22:%22python%22,%22kt%22:%223%22%7D
2.https://fe-api.zhaopin.com/c/i/sou?start=60&pageSize=60&cityId=763&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&lastUrlQuery=%7B%22p%22:2,%22jl%22:%22763%22,%22kw%22:%22python%22,%22kt%22:%223%22%7D
3.https://fe-api.zhaopin.com/c/i/sou?start=120&pageSize=60&cityId=763&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&lastUrlQuery=%7B%22p%22:3,%22jl%22:%22763%22,%22kw%22:%22python%22,%22kt%22:%223%22%7D
会发现多了一个start=xxx,不难发现这就是页码跳转的一个参数。有了这个参数我们就可以实现翻页获取信息。接下来开始敲代码!
3.设置settings文件
激活DEFAULT_REQUEST_HEADERS头部信息,打开PIPELINES管道。
ROBOTSTXT_OBEY = False DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', 'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)" " Chrome/63.0.3239.132 Safari/537.36" } ITEM_PIPELINES = { 'zhilian.pipelines.ZhilianPipeline': 300, }
4.设置items
暂时先抓取这些简单信息
class ZhilianItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
eduLevel = scrapy.Field() # 学历
company = scrapy.Field() # 公司名称
salary = scrapy.Field() # 薪资
city = scrapy.Field() # 城市
workingExp = scrapy.Field() # 工作经验
5.编写爬虫文件
zl_spider.py
# -*- coding: utf-8 -*- import json import scrapy from scrapy import Request from zhilian.items import ZhilianItem class ZlSpiderSpider(scrapy.Spider): name = 'zl_spider' allowed_domains = ['www.zhaopin.com'] start_urls = ['https://www.zhaopin.com'] first_url = 'https://fe-api.zhaopin.com/c/i/sou?start={page}&pageSize=60&cityId=763&workExperience=-1&education' \ '=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&lastUrlQuery=%7B%22p%22:2,' \ '%22jl%22:%22763%22,%22kw%22:%22python%22,%22kt%22:%223%22%7D' def start_requests(self, page=None): #实现翻页 for i in range(0, 11): page = i*60 yield Request(self.first_url.format(page=page), callback=self.parse) pass def parse(self, response): result = json.loads(response.text) item = ZhilianItem() for field in item.fields: if field in result.keys(): item[field] = result.get(field) yield item
至此运行查看一下有没有成功

发现空空如也
检查一下result.keys()里的值


发现字典里只有两个key,所以上面遍历出来的value为空,而我真正需要的值在data.results里面
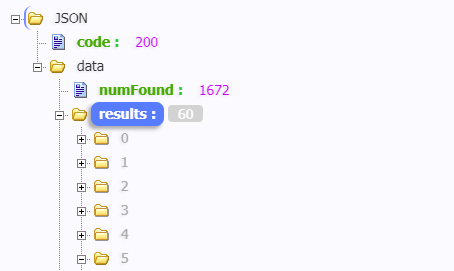
接下来改写下代码,把parse部分改写成如下图

结果无情报错
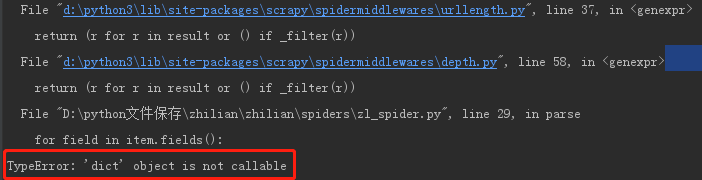
无奈之下只好手打

最终修改得到的爬虫代码页为
# -*- coding: utf-8 -*- import json import scrapy from scrapy import Request from zhilian.items import ZhilianItem class ZlSpiderSpider(scrapy.Spider): name = 'zl_spider' allowed_domains = ['www.zhaopin.com'] start_urls = ['https://www.zhaopin.com'] first_url = 'https://fe-api.zhaopin.com/c/i/sou?start={page}&pageSize=60&cityId=763&workExperience=-1&education' \ '=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&lastUrlQuery=%7B%22p%22:2,' \ '%22jl%22:%22763%22,%22kw%22:%22python%22,%22kt%22:%223%22%7D' def start_requests(self, page=None): # 翻页 for i in range(0, 11): page = i*60 yield Request(self.first_url.format(page=page), callback=self.parse) pass def parse(self, response): item = ZhilianItem() result = json.loads(response.text) for i in range(0, 60): # 一个页面有60个数据字典,遍历每个字典 results = result['data']['results'][i] company = results['company']['name'] eduLevel = results['eduLevel']['name'] workingExp = results['workingExp']['name'] city = results['city']['display'] item['company'] = company item['eduLevel'] = eduLevel item['salary'] = results.get('salary') item['workingExp'] = workingExp item['city'] = city yield item
运行结果部分如图
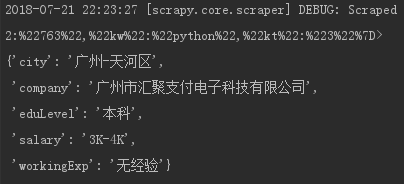
6.写入数据库mongodb,用update来使数据去重(适用于数据量小)
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymongo class ZhilianPipeline(object): def process_item(self, item, spider): return item class MongoPipeline(object): collection_name = 'zl_python' def __init__(self, mongo_uri, mongo_db): self.mongo_uri = mongo_uri self.mongo_db = mongo_db @classmethod def from_crawler(cls, crawler): return cls( mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DATABASE') ) def open_spider(self, spider): self.client = pymongo.MongoClient(self.mongo_uri) self.db = self.client[self.mongo_db] def close_spider(self, spider): self.client.close() def process_item(self, item, spider): self.db[self.collection_name].update({'company': item['company']}, dict(item), True) # 去重 return item
7.最终成果部分截图
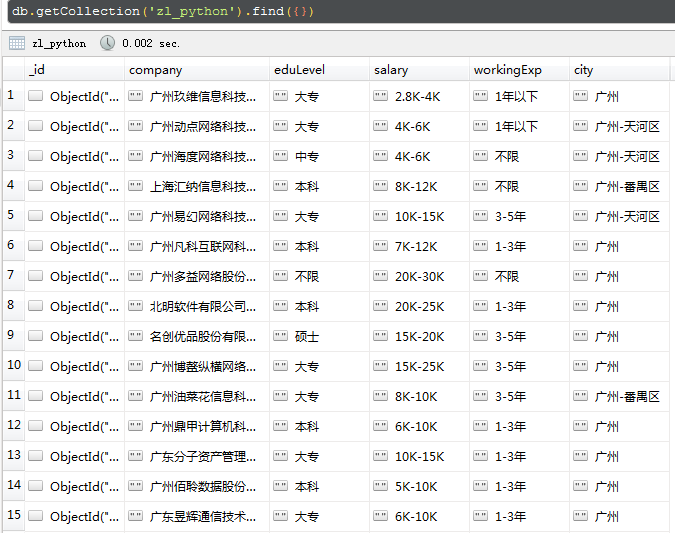

十页的数据为313,说明部分数据为重复数据。
github地址:https://github.com/biyeee/ZL_spider

 浙公网安备 33010602011771号
浙公网安备 33010602011771号