
微软BI 之SSIS 系列 - 使用 Script Component Destination 和 ADO.NET 解析不规则文件并插入数据
2014-12-06 23:24 BIWORK 阅读(2672) 评论(2) 收藏 举报开篇介绍
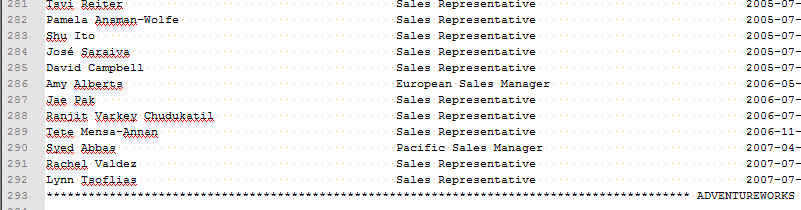
这一篇文章是 微软BI 之SSIS 系列 - 带有 Header 和 Trailer 的不规则的平面文件输出处理技巧 的续篇,在上篇文章中介绍到了对于这种不规则文件输出的处理方式。比如下图中的这种不规则文件,第一行,第二行 Header 部分,第三行的内容 Content 部分,最后一行的 Trailer 部分。

在前几个课程 微软BI SSIS 2012 ETL 控件与案例精讲 第43,44,45,46 课中,我分别讲解了如何使用 .Script Component Source 解析不规则文件(第43,44课),如何使用 Script Component 同步 Transformation 转换处理不规则文件(第45课),以及使用异步的 Transformation 转换不规则文件(第46课),今天我们讲解的是 Script Component Destination。即把 Script Component 作为一个 Destination 目标来使用,既然是 Destination 组件,那么就应该是以接受来自上游的 Input 输入并对数据进行清洗处理。并且,一般的 Destination 要么就是数据库表,要么就是文件,即我们是借用 Script Component 往表或者文件中插入数据。
使用 Script Component Destination
我们还是使用之前的不规则文件作为本篇的例子来讲解。这是 微软BI 之SSIS 系列 - 带有 Header 和 Trailer 的不规则的平面文件输出处理技巧 这篇文章中用到的文件格式描述。

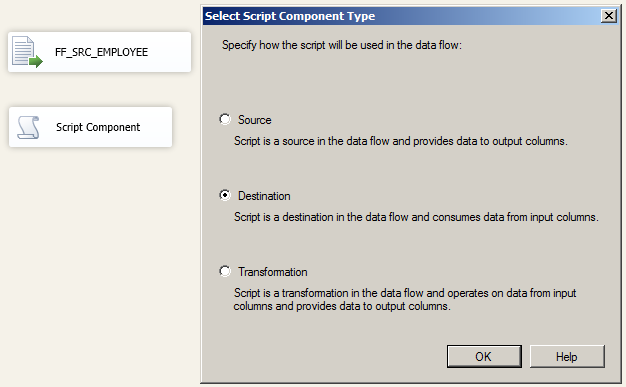
和之前的几个课程的配置,文件链接等方式一样,略。添加一个新的 Script Component 并选择使用 Destination。
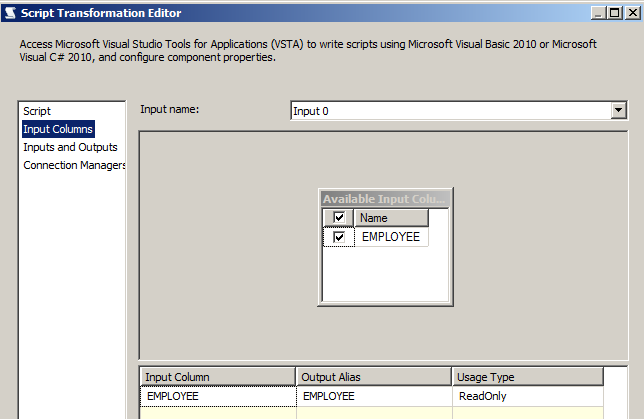
这里仍然选择 EMPLOYEE 作为 INPUT 输入项,文件源配置参照前几课的设置。
在 Script 中访问 SQL Server 数据库表,应通过 ADO.NET 链接方式访问数据库表。
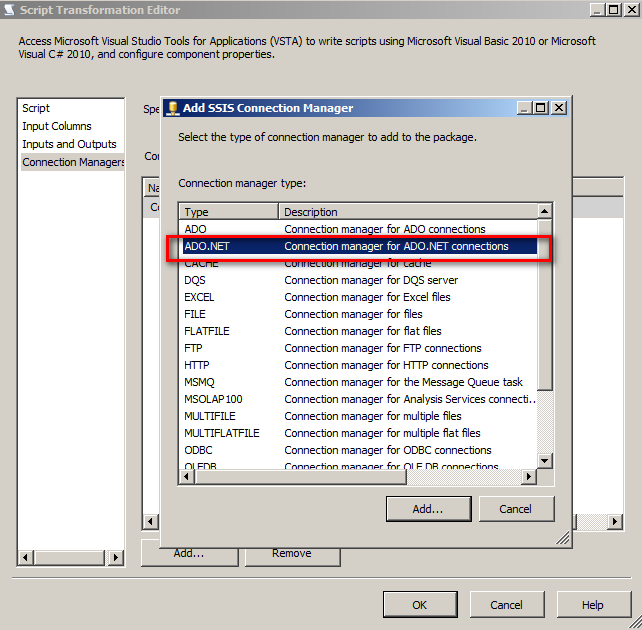
链接到课程指定的 DEMO 数据库。
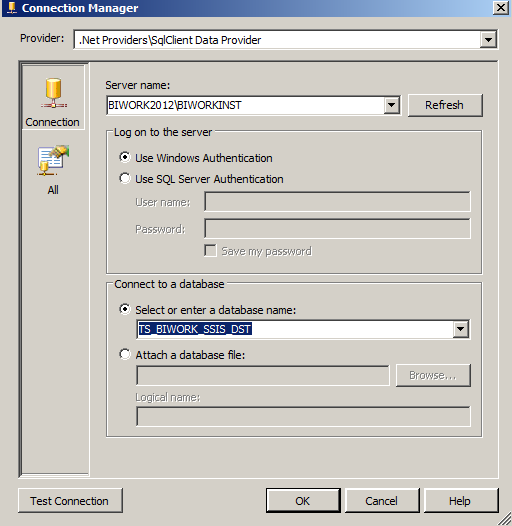
跟 Script Component - Source 中处理一样,取一个名称 - CON_ADO。或者先在链接管理器中先创建好一个 ADO.NET 链接管理器,然后再关联也是可以的。

将上方的文件源关联起来,注意到下方 ADO.NET 连接管理器已经创建了。
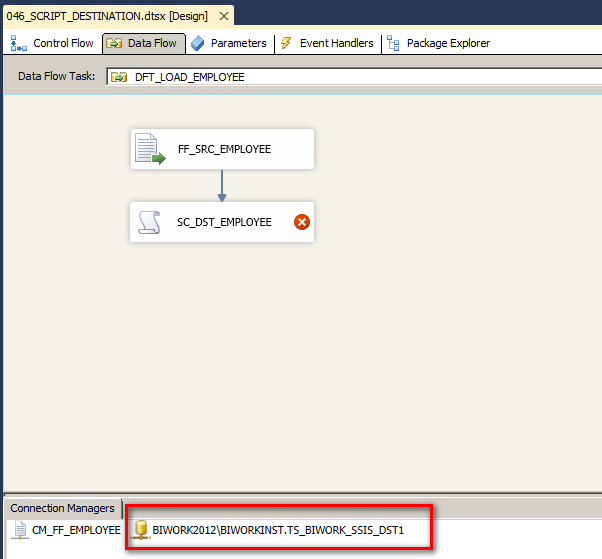
在 Script 脚本中使用 ADO.NET 编程方式需要引入这个 NameSpace 命名空间。
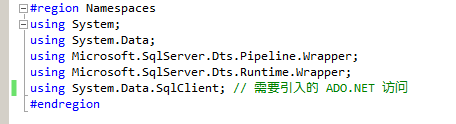
具体代码部分参照如下,具体讲解请参看视频:
#region Help: Introduction to the Script Component /* The Script Component allows you to perform virtually any operation that can be accomplished in * a .Net application within the context of an Integration Services data flow. * * Expand the other regions which have "Help" prefixes for examples of specific ways to use * Integration Services features within this script component. */ #endregion #region Namespaces using System; using System.Data; using Microsoft.SqlServer.Dts.Pipeline.Wrapper; using Microsoft.SqlServer.Dts.Runtime.Wrapper; using System.Data.SqlClient; // 需要引入的 ADO.NET 访问 #endregion /// <summary> /// This is the class to which to add your code. Do not change the name, attributes, or parent /// of this class. /// </summary> [Microsoft.SqlServer.Dts.Pipeline.SSISScriptComponentEntryPointAttribute] public class ScriptMain : UserComponent { //连接管理器接口 IDTSConnectionManager100 con; //数据库访问对象 SqlConnection sqlConn; SqlCommand sqlCommand1; SqlCommand sqlCommand2; SqlParameter sqlParameter; // 需要重写的方法 初始化数据库连接 public override void AcquireConnections(object Transaction) { // Script Component 关联的 ADO.NET 连接管理器 con = this.Connections.CONADO; sqlConn = (SqlConnection)con.AcquireConnection(null); } // 初始化SQL语句与参数 public override void PreExecute() { //INSERT INTO T046_EMPLOYEE_FILE_EXTRACTION VALUES(@FILE_CREATED_DATE,@TOTAL_EMPLOYEES) //INSERT INTO T046_EMPLOYEES VALUES(@EMP_NAME,@POSITION,@HIRED_DATE,@BIRTH_DATE,@EMAIL,@PHONE,@MARRIAGE) sqlCommand1 = new SqlCommand("INSERT INTO T046_EMPLOYEE_FILE_EXTRACTION VALUES(@FILE_CREATED_DATE,@TOTAL_EMPLOYEES)",sqlConn); sqlCommand2 = new SqlCommand("INSERT INTO T046_EMPLOYEES VALUES(@EMP_NAME,@POSITION,@HIRED_DATE,@BIRTH_DATE,@EMAIL,@PHONE,@MARRIAGE)", sqlConn); // For Table T046_EMPLOYEE_FILE_EXTRACTION sqlParameter = new SqlParameter("@FILE_CREATED_DATE", SqlDbType.NVarChar, 50); sqlCommand1.Parameters.Add(sqlParameter); sqlParameter = new SqlParameter("@TOTAL_EMPLOYEES", SqlDbType.Int); sqlCommand1.Parameters.Add(sqlParameter); // For Table T046_EMPLOYEES sqlParameter = new SqlParameter("@EMP_NAME", SqlDbType.NVarChar, 50); sqlCommand2.Parameters.Add(sqlParameter); sqlParameter = new SqlParameter("@POSITION", SqlDbType.NVarChar, 50); sqlCommand2.Parameters.Add(sqlParameter); sqlParameter = new SqlParameter("@HIRED_DATE", SqlDbType.NVarChar, 50); sqlCommand2.Parameters.Add(sqlParameter); sqlParameter = new SqlParameter("@BIRTH_DATE", SqlDbType.NVarChar, 50); sqlCommand2.Parameters.Add(sqlParameter); sqlParameter = new SqlParameter("@EMAIL", SqlDbType.NVarChar, 50); sqlCommand2.Parameters.Add(sqlParameter); sqlParameter = new SqlParameter("@PHONE", SqlDbType.NVarChar, 25); sqlCommand2.Parameters.Add(sqlParameter); sqlParameter = new SqlParameter("@MARRIAGE", SqlDbType.NVarChar, 2); sqlCommand2.Parameters.Add(sqlParameter); } /// <summary> /// This method is called once for every row that passes through the component from Input0. /// /// Example of reading a value from a column in the the row: /// string zipCode = Row.ZipCode /// /// Example of writing a value to a column in the row: /// Row.ZipCode = zipCode /// </summary> /// <param name="Row">The row that is currently passing through the component</param> public override void Input0_ProcessInputRow(Input0Buffer Row) { if (Row.EMPLOYEE.StartsWith("FILE CREATED DATE")) { // 则只取文件日期部分 sqlCommand1.Parameters["@FILE_CREATED_DATE"].Value = Row.EMPLOYEE.Substring(19, 10); sqlCommand1.Parameters["@TOTAL_EMPLOYEES"].Value = 0; sqlCommand1.ExecuteNonQuery(); } // 如果达到第二行 else if (Row.EMPLOYEE.StartsWith("TOTAL EMPLOYEES")) { sqlCommand1.Parameters["@FILE_CREATED_DATE"].Value = ""; sqlCommand1.Parameters["@TOTAL_EMPLOYEES"].Value = int.Parse(Row.EMPLOYEE.Substring(16, 10)); sqlCommand1.ExecuteNonQuery(); } else if (Row.EMPLOYEE.StartsWith("*")) { //不做处理 } else { // 剩下的部分是主体内容部分,直接按照固定的列位置描述截取字符串 sqlCommand2.Parameters["@EMP_NAME"].Value = Row.EMPLOYEE.Substring(0, 50); sqlCommand2.Parameters["@POSITION"].Value = Row.EMPLOYEE.Substring(50, 50); sqlCommand2.Parameters["@HIRED_DATE"].Value = Row.EMPLOYEE.Substring(100, 12); sqlCommand2.Parameters["@BIRTH_DATE"].Value = Row.EMPLOYEE.Substring(112, 12); sqlCommand2.Parameters["@EMAIL"].Value = Row.EMPLOYEE.Substring(124, 50); sqlCommand2.Parameters["@PHONE"].Value = Row.EMPLOYEE.Substring(174, 25); sqlCommand2.Parameters["@MARRIAGE"].Value = Row.EMPLOYEE.Substring(199, 1); sqlCommand2.ExecuteNonQuery(); } } // 直接重写连接释放 public override void ReleaseConnections() { base.ReleaseConnections(); } }
执行结果。
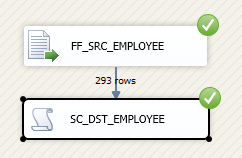
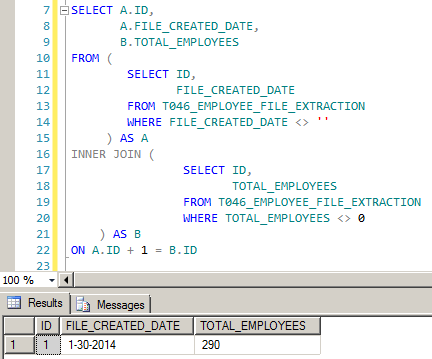
查询结果如下:
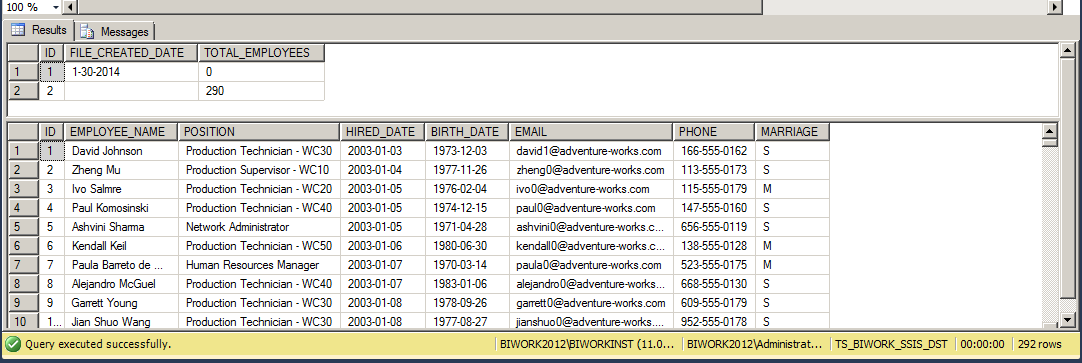
对于第一张表,通过简单的 SQL 语句即可以解决这个合并问题。
总结
其实对比 Script Component Source,Script Component Transformation (同步或异步) 这三种不规则的文件解析方式来说,前面几种是最简单的,特别是 Script Component Source 可以非常直观的看到两个解析之后的 Output 操作。并且我们的这四个案例,不同的解决方式实际上就是把解析不规则文件的过程分别放在了 Source 端,同步的 Transformation 端,异步的 Transformation 端,Destination 端。 不同的位置,解析的过程不一样,对输出的处理不一样。并且通过这样的一个案例可以让我们对 Source, 同步转换,异步转换这些概念更加深刻了。
并且在这些个案例中,我们能够看到 Script Component 强大的自定义编程能力,文件访问,数据库访问,同步转换,异步遍历等不同的解决方案。在实际的 ETL 项目中,我们可以针对不同的场景灵活的使用 Script Component 来解决这些问题。
最后,还是要提醒一下就这种不规则的文件处理不要使用 Script Component Destination 来处理,关于它的效率问题从下图中就可以看得出来。以下测试环境为3G左右的虚机,包括磁盘空间也都很紧张,具体的测试数据在不同的环境下可能表现不同。
而原因其实可以分析出来:
- Script Component Transformation 异步转换并不是一个完全阻塞组件,它是一个半阻塞组件。在拿到上游的全部或者部分 Buffer 的时候,ProcessInput() 方法 就已经开始工作了,处理一部分 Buffer 就往下输出一部分 Buffer。并且在通过 OLE DB Destination 组件的时候,也是批量插入,因此在本案例中效率最高。
- Script Component Source 是我以前在项目中经常使用到的一种方式,也是比较喜欢的一种方式。但是通常的做法就一次从文件读取一行,然后输出一行导致效率没有 Transformation 异步转换高。由于文件一般都是200 - 500MB,因此没有遇到特别大的性能问题,所以就没有进一步的优化。
- Script Component Transformation 同步转换是一个非阻塞组件,但是由于一次处理一行输出一行,这个过程略微花费一点时间。
- Script Component Destination 并不是一个完整意义上的转换组件,在本案例中是作为一个 Destination 组件来处理,受 ProcessInputRow() 方法限制也是一行一行的通过 ADO.NET 方式插入,因此效率最低。

关于阻塞,半阻塞,同步和异步的文章可以参考 微软BI 之SSIS 系列 - 理解Data Flow Task 中的同步与异步, 阻塞,半阻塞和全阻塞以及Buffer 缓存概念 此文中提到的 Script Component 是以默认的同步 Transformation 转换组件为例,因此归在 Non-Blocking 部分。
更多 BI 文章请参看 BI 系列随笔列表 (SSIS, SSRS, SSAS, MDX, SQL Server) 如果觉得这篇文章看了对您有帮助,请帮助推荐,以方便他人在 BIWORK 博客推荐栏中快速看到这些文章。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号