
MDX Step by Step 读书笔记(四) - Working with Sets (使用集合) - 我对Exists 函数的理解
2013-04-17 14:44 BIWORK 阅读(1425) 评论(3) 编辑 收藏 举报在上一篇笔记里记载了对于 Auto-Exists 的理解 –
MDX Step by Step 读书笔记(四) - Working with Sets (使用集合) - Limiting Set and Auto-Exists
Auto-Exists 的作用可以理解参入Cross Join 的双方 SET 集合互相交叉组合形成一个新的 SET 集合并且只有匹配的元组才会列出来,没有关联关系的不会返回. 但是更多的时候可能只需要返回一个集合中能与另一个集合关联的元组集合,这时可以使用 Exists.
简单来说 Auto-Exists 有 A 和 B 两个集合, 他们并列返回 A和B 中能够关联到的元组形成的集合,返回的集合即有 A 中的成员也有B中的成员.
而Exists 简单来说也可以有 A 和 B两个集合,但是只返回 A 中的那些和 B 中能够关联的元组形成的集合,返回的集合只有 A 中的成员 , 这就是区别.
书中的示例在 Cross Join 基础之上使用了 Exists,可能不太好理解 , 因此先换另外的一种方式来理解.
示例一
SELECT
{
([Date].[Calendar].[CY 2002])
} *
{
([Measures].[Reseller Sales Amount])
} ON COLUMNS,
{[Product].[Category].[Category].Members} *
{[Product].[Subcategory].[Subcategory].Members}
ON ROWS
FROM [Step-by-Step]
WHERE ([Geography].[Country].[United States]);
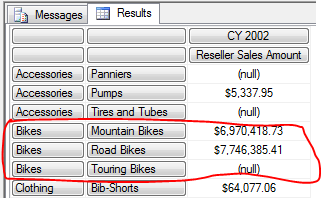
返回的行数比较多, 但我们只先关注一下 Bikes 这个 Category 下面的内容. Bikes下面只在 Mountain Bikes 和Road Bikes 下面有值.
如果对这种结构不理解的话,请先参考上一篇博文,里面介绍到了 Auto-Exists 里面的内容.
再来看看 Exists 的作用,示例二:
SELECT
{
([Date].[Calendar].[CY 2002])
} *
{
([Measures].[Reseller Sales Amount])
} ON COLUMNS,
EXISTS(
{[Product].[Category].[Category].Members},
{([Product].[Subcategory].[Mountain Bikes])}
)
ON ROWS
FROM [Step-by-Step]
WHERE ([Geography].[Country].[United States]);

SELECT 中的 COLUMNS 应该很好理解, 只看ROWS 部分. 我理解的 EXISTS 关键字只是用来起来一个筛选作用,并不参与到实际的运算, 可以理解为这个函数会返回一个集合.
EXISTS(
{[Product].[Category].[Category].Members},
{([Product].[Subcategory].[Mountain Bikes])}
)
它返回的就是与 Subcategory 中 Mountain Bikes 有关联的那些 Category 的成员.
EXISTS (SET A, SET B) – 返回在 A 中与 B 相关联的那些 A 的成员 这就是我对这个函数的理解.
通过查看示例一,可以发现只有 Bikes 这个 Category 与 Mountain Bikes 相关联,所以
EXISTS(
{[Product].[Category].[Category].Members},
{([Product].[Subcategory].[Mountain Bikes])}
)
在我们的这个例子等于
{[Product].[Category].[Category].Bikes}
因此这个查询语句就可以变形为 –
SELECT
{
([Date].[Calendar].[CY 2002])
} *
{
([Measures].[Reseller Sales Amount])
} ON COLUMNS,
{[Product].[Category].[Category].Bikes}
ON ROWS
FROM [Step-by-Step]
WHERE ([Geography].[Country].[United States]);
查询结果是一样的.
示例三
上面的例子中,EXISTS 的参数都在一个纬度中,并且相互之间存在直接的关联关系,比如 Category 和 Sub Category 就是很直接的一对多的关系. 那么可以尝试一下没有直接关系的两个集合在 Exists 函数里的表现.
SELECT
{ ([Measures].[Reseller Sales Amount]) } ON COLUMNS,
EXISTS(
{[Product].[Category].[Category].Members},
{[Product].[Color].&[White]}
)
ON ROWS
FROM [Step-by-Step]
WHERE ([Geography].[Country].[United States]);
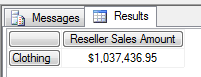
EXISTS(
{[Product].[Category].[Category].Members},
{[Product].[Color].&[White]}
)
可以这么理解, 这段代码返回的是颜色为白色相关的 Category, 看上面查询结果为 Clothing. 但是事实上 Clothing 这个分类应该没有白色这个属性,但是 Clothing 下面的某类子分类下的某一个产品可能具备白色这个属性,它是通过多张表传递关联两者关系的.
看看通过 Auto-Exists 能不能验证一下
SELECT
{[Measures].[Reseller Sales Amount]} ON COLUMNS,
{[Product].[Category].[Category].Members}*
{[Product].[Color].[White]} ON ROWS
FROM [Step-by-Step]
WHERE ([Geography].[Country].[United States]);
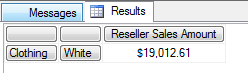
结果证明两者是可以关联起来的, 否则通过 * 或者Cross Join 是返回不了这个结果的.
理解了上面这些内容,再看书上的例子, 这里按顺序写成 示例四
SELECT
{
([Date].[Calendar].[CY 2002]),
([Date].[Calendar].[CY 2003]),
([Date].[Calendar].[CY 2004])
} *
{
([Measures].[Reseller Sales Amount]),
([Measures].[Internet Sales Amount])
} ON COLUMNS,
{[Product].[Category].[Category].Members} *
{[Product].[Color].[Color].Members} ON ROWS
FROM [Step-by-Step]
WHERE ([Geography].[Country].[United States],
[Product].[Subcategory].[Mountain Bikes]);
在这个例子中 COLUMNS 上的内容是两个集合的交叉合集, 直接构成列头.
ROWS 上 Category 的各个成员相对应的根据 Auto-Exists 去关联相应的颜色.
在WHERE条件上 有United States 限定了 地理轴的长短就是 United States 这一个点, 同样的道理 Mountain Bikes 限定了 Subcategory 的范围.
因此查询的效果就是 – 查询 从2002年到2004年间在美国的山地车零售和网售额,并显示该它们属于哪个分类和颜色.

示例五 – 使用Exists
SELECT
{
([Date].[Calendar].[CY 2002]),
([Date].[Calendar].[CY 2003]),
([Date].[Calendar].[CY 2004])
} *
{
([Measures].[Reseller Sales Amount]),
([Measures].[Internet Sales Amount])
} ON COLUMNS,
Exists(
{[Product].[Category].[Category].Members} *
{[Product].[Color].[Color].Members},
{([Product].[Subcategory].[Mountain Bikes])}
) ON ROWS
FROM [Step-by-Step]
WHERE ([Geography].[Country].[United States])
查询结果

对比这个查询结果 发现 Bikes – Silver 这一行的数据和示例四中完全相同, 但是 Bikes – Black 却不一致. 并且将 ([Product].[Subcategory].[Mountain Bikes]) 从WHERE 处提前到 Exists 有什么区别呢?
区别就在于 WHERE 条件中是完全限制了我们查询的空间在 Subcategory 这个轴上就只有 Mountain Bikes 这一个点, 所以查询的结果一定是与 Mountain Bikes 相关的.
但是在Exists中,只是说能够关联到 Mountain Bikes 的有哪些Category 和 Color的组合, 但是同时 Category 和 Color 的组合也有可能能关联其它非 Mountain Bikes的Subcategory 元素.
还是按照我们之前的理解
SELECT
{
([Date].[Calendar].[CY 2002])
} *
{
([Measures].[Reseller Sales Amount])
} ON COLUMNS,
{[Product].[Category].[Category].Members} *
{[Product].[Subcategory].[Subcategory].Members}*
{[Product].[Color].[Color].Members} ON ROWS
FROM [Step-by-Step]
WHERE ([Geography].[Country].[United States]);
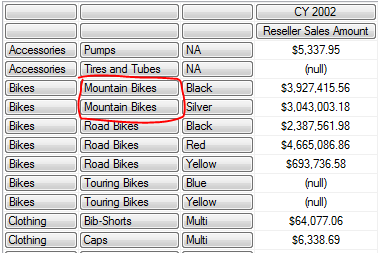
Exists(
{[Product].[Category].[Category].Members} *
{[Product].[Color].[Color].Members},
{([Product].[Subcategory].[Mountain Bikes])})
跟Mountain Bikes 相关联的如上图所示,只返回 Category 和 Color 部分的内容.
([Product.Category].[Category].[Bikes],[Product].[Color].[Color].[Black]),
([Product.Category].[Category].[Bikes],[Product].[Color].[Color].[Silver])
这样就 Exists 返回了关联后的集合就是这样的代码了
SELECT
{
([Date].[Calendar].[CY 2002]),
([Date].[Calendar].[CY 2003]),
([Date].[Calendar].[CY 2004])
} *
{
([Measures].[Reseller Sales Amount]),
([Measures].[Internet Sales Amount])
} ON COLUMNS,
{
([Product.Category].[Category].[Bikes],[Product].[Color].[Color].[Black]),
([Product.Category].[Category].[Bikes],[Product].[Color].[Color].[Silver])
} ON ROWS
FROM [Step-by-Step]
WHERE ([Geography].[Country].[United States]);

查询结果和使用 Exists 函数完全一样, 为什么 Bikes-Black 行的值比使用 WHERE 条件要大,原因就是上面图中Bikes – Black 不光包含了 Mountain Bikes 也包含了 Road Bikes.
NON EMPTY 关键字
SELECT
{[Measures].[Reseller Sales Amount]} ON COLUMNS,
{[Date].[Month].[May 2002]} *
{[Employee].[Employee].Members} ON ROWS
FROM [Step-by-Step];
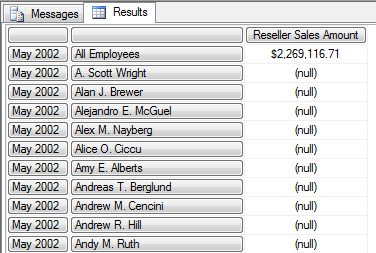
查询结果中包含有很多 NULL 值, 但这并不说明 Employee 中的成员不能和 Month 中 May 2002关联, 它们通过 Auto-Exists 自动关联, 只不过是表示这些 Employee 成员在 2002 年5月没有任何的零售记录.
那么可以通过 NON EMPTY 关键字来去除那些为空的纪录.
SELECT
{[Measures].[Reseller Sales Amount]} ON COLUMNS,
NON EMPTY {[Date].[Month].[May 2002]} *
{[Employee].[Employee].Members} ON ROWS
FROM [Step-by-Step];
查询结果
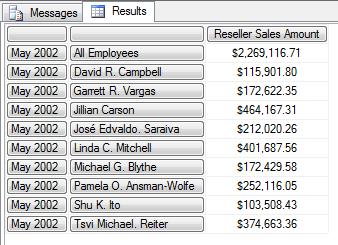
在上面的这个例子中使用 NON EMPTY 可以过滤掉那些为空的信息.
从业务角度来看这个示例,这个示例也仅仅告诉了我们如何使用 NON EMPTY 这个关键字,如果使用这个查询来筛选销售部门所有员工的零售业绩或者只认为有查询结果的员工一定是属于销售部门的员工,那么这个理解可能就有问题. 因为有一部分员工可能就没有销售任务所以零售额一定为空, 而有些员工可能正好这个月没有销售纪录所以零售额也一定为空.
这种情况下可以考虑使用 Exists, 不过这次的语法结构和之前的示例有所不同, 多了一个 MeasureGroupName
Exists( Set_Expression1 , Set_Expression2 [, MeasureGroupName] )
这样的话 SET 1 不光要和 SET 2 关联,还要和特定的 Measure Group 进行关联, Measure Group中的数据是事实数据,它们对纬度的某些成员的引用在 SET 1 中是可以找到的.
比如, 有一个 Measure Group 叫做 Reseller Sales Target,这个Group 中保存的是所有零售部门的员工的销售纪录. 比如另外一个 Measure Group 叫做 Internet Sales Target, 它保存的是所有网售部门员工的销售纪录. 那么 SET 1 集合和不同的 Measure Group 交互时所返回的信息是不一样的, 一个可能是返回所有零售部门的员工, 另一个是返回所有网售部分的员工信息.
书上有一个示例描述的就应该是这样的一个例子
SELECT
{[Measures].[Reseller Sales Amount]} ON COLUMNS,
{[Date].[Month].[May 2002]} *
Exists(
{[Employee].[Employee].Members},
{[Date].[Calendar].[Q2 CY 2002]},
"Sales Targets"
) ON ROWS
FROM [Step-by-Step]
Sales Target 这个度量值组表示的是员工的季度销售目标, 通过使用 EXISTS 可以查询在 2002年第二季度有记录的员工, 并有季度销售目标的人在2002年5月份的零售情况.
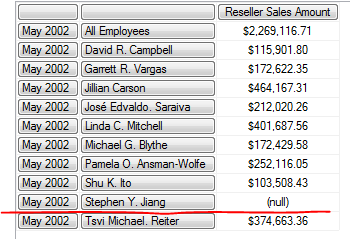
通过查询可以看到 Stephen Y. Jiang 的销售纪录是空的.
还有一种情况就是第一个集合为空 -
SELECT
{[Measures].[Reseller Sales Amount]} ON COLUMNS,
{[Date].[Month].[May 2002]} *
Exists(
{[Employee].[Employee].Members},
,
"Sales Targets"
) ON ROWS
FROM [Step-by-Step]
这样的查询就表示有销售目标的员工在 2002年5月份的零售额
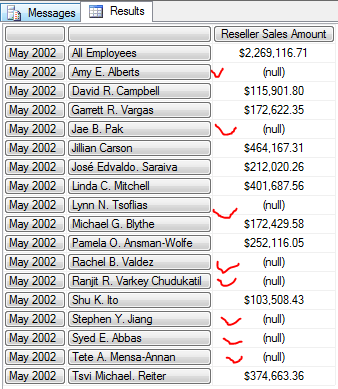
没有 {[Date].[Calendar].[Q2 CY 2002]} 这个 SET, 可以看到其它不在 Q2 CY 2002 季度的其它销售人员的信息.
有关 Exists 和 MeasureGroup 参数, MSDN 也给出了一些总结, 包括 NON EMPTY 和 Exists 在处理 NULL 值的问题上已经讲的很清楚了
Exists 函数返回与第二个集中的一个或多个元组共存的元组以及在指定度量值组的事实数据表中具有关联行的元组
如果指定了 MeasureGroupName 参数, 则带有包含 Null 值的度量值的度量值组行会影响 Exists. 下面是此形式的 Exists 和 Nonempty 函数之间的差异:如果这些度量值的 NullProcessing 属性设置为 Preserve, 则意味着在对该部分的多维数据集运行查询时这些度量值将显示 Null 值; NonEmpty 始终从集中删除具有 Null 度量值的元组, 而具有 MeasureGroupName 参数的 Exists 将不筛选具有关联的度量值组行的元组, 甚至在度量值为 Null 时也是如此.
查阅我的其它有关 MDX 的学习笔记 - <<Microsoft SQL Server 2008 MDX Step by Step>> 学习笔记连载目录

