
MDX Step by Step 读书笔记 - 个人专题(一) 如何理解 MDX 查询中WHERE 条件如何对应Cube 中的切片轴 Slicer Axis
2013-04-15 17:12 BIWORK 阅读(3456) 评论(0) 编辑 收藏 举报查阅我的其它有关 MDX 的学习笔记 - <<Microsoft SQL Server 2008 MDX Step by Step>> 学习笔记连载目录
这篇文章原本应该写在第四章的读书笔记里, 但是篇幅太长,而且主要示例和图解都是基于我自己的理解, 所以单独成文(可以先看看第四章读书笔记内容). 这一部分基础内容我个人觉得非常重要, 之前看过一次 MDX 可以说看过不用隔断时间就忘记了, 但是这一次发现基本上仔细看过就不会忘记. 主要原因就是看 MDX 不能光看语法和代码, 更重要的就是把 Member 成员, Tuple 元组, Cell 单元, Partial Tuple 局部元组, Set 集合 这些在 MDX 中基本的元素在所谓的多维空间的表现形式要理解清楚, 理解了这些背后的原理再回头看代码就会发现这些元素的所表现的结构非常清晰.
以下是我对 MDX 查询中 WHERE 条件对应的 Cube 中所谓切片空间的理解和分析.
先下定义和我的结论,加不加 WHERE 条件的区别就是:
- 不加 WHERE 条件整个查询是在一个完整的 Cube空间里查询.
- 加了WHERE 条件整个查询是基于在WHERE条件所定义的轴空间里查询.
通过几个非常小的示例来阐述我的理解 (为了方便理解, 使用 Chapter 3 Cube):

SELECT
{
([Date].[Calendar].[CY 2002])
} ON COLUMNS,
{
([Product].[Category].[Bikes])
} ON ROWS
FROM [Step-by-Step]
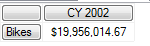
这个例子可以非常简单的理解为查询了 Bikes 在 2002 年的零售情况.
仍然根据我们在第三章的理解 (不要去看这个代码, 而是要去想象背后这些属性层次结构表示的轴在空间里是什么样的一个位置), 两个属性层次结构中的一个成员构成了一个局部元组 Partial Tuple
([Date],[Calendar].[CY2002], [Product].[Category].[Bikes]), SSAS 在处理这些元组的时候因为其它的属性层次结构或者叫轴上的成员没有被显示的写出, 因此将根据一定的规则默认补齐这个元组.
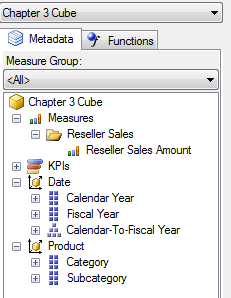
我们看到上图还有 Fiscal Year, Subcategory, Reseller Sales 等几个轴.
所以上面的查询等价于 (不要去考虑最终结果显示几层列的问题, 只考虑值是否相等的问题):
SELECT
{
(
[Date].[Calendar].[CY 2002],
[Date].[Fiscal Year],
[Product].[Subcategory],
[Measures].[Reseller Sales Amount]
)
} ON COLUMNS,
{
([Product].[Category].[Bikes])
} ON ROWS
FROM [Step-by-Step];
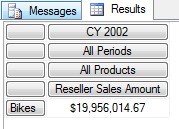
虽然在第一个示例中我们只显示的写出了两个轴 (不要去管 COLUMNS和ROWS 的位置, 而是去看 COLUMNS 和 ROWS 里面引用了几个属性层次结构, 几个轴 ) - ([Date],[Calendar].[CY2002], [Product].[Category].[Bikes]) 显示的引用了两个轴, 但是从上面的代码中可以发现, 实际我们的查询是交互了所有的轴, 我们的查询范围是从所有的轴上的点形成的空间里去寻找我们所需要的那一个或者多个点, 这个点就是显示在查询结果中的值 - $19,956,014.67.
先讲清楚这个问题, 然后我们再假设, 假设我们目前的Cube 只有四个属性层次结构, 三个纬度属性层次结构和一个度量值层次结构. 但是度量值层次结构我们不考虑画出来.
三个纬度属性层次结构是: Date纬度下的 Calendar, Product 纬度下的 Category 和 Geography 纬度下的Country, 其实还应该有一个度量值纬度 Measures 下 Reseller Sales Amount 但不在本图中.
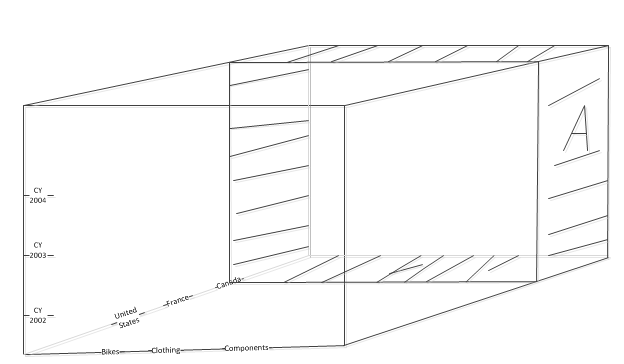
那么像这样的MDX 查询语句应该如何理解?
SELECT
{
([Date].[Calendar].[CY 2002])
} ON COLUMNS,
{
([Product].[Category].[Bikes] )
} ON ROWS
FROM [Step-by-Step]
WHERE {
([Geography].[Country].[United States]),
([Geography].[Country].[France]),
([Geography].[Country].[Canada])
}
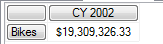
首先就应该看 WHERE 条件, 在WHERE 条件中出现一个集合 SET, 有3个Tuple, 每一个Tuple 中都有一个地理纬度的成员,合起来就是 United States, France和Canada. 理解到这个阶段,现在看这些引用就应该能很清楚的看明白成员 United States, France和 Canada就是Country 轴的3个点, WHERE 条件的作用就是告诉你我们的查询范围就是只限定于 United Sates ,France 和Canada 构成的轴与其它轴交互后形成的一个空间. 可以从阴影部分看到,在Country 这个轴上在Canada 这个点之后应该还有其它的国家, 但是因为WHERE 条件的限制, 使得阴影部分被排除在我们的查询之外, 所以WHERE 条件就是切除了没有出现在WHERE条件中的一个或者多个轴上的某一段子轴与其它轴交互的这么一个空间 – Slicer.
再来看上面的查询,千万不要认为查询的结果就应该是这三个国家在2002年 各自Bikes 的销售额, 不是的! 正确的理解是在除去 A 阴影部分的Cube 空间里查询 2002年的自行车的销售额, 返回的就一个值! 这个值等于 这三个国家在2002年各自Bikes 的销售额的总额. 这个仍然会按照 SSAS 对Partial Tuple 局部元组的补充原则进行填充. 以前没有WHERE 条件时是聚合所有Country得到的值,而现在是也是聚合“所有Country” 得到的销售额, 但是此时的”所有Country ”只包含United States, France 和Canada 三个国家, 这一点一定要分清楚.
来验证一下:
SELECT
{
([Date].[Calendar].[CY 2002],[Geography].[Country].[United States]),
([Date].[Calendar].[CY 2002],[Geography].[Country].[France]),
([Date].[Calendar].[CY 2002],[Geography].[Country].[Canada])
} ON COLUMNS,
{([Product].[Category].[Bikes] ) } ON ROWS
FROM [Step-by-Step];
查询结果 -

把这三个国家的销售额加起来得到的数字就是之前查询得到的 – 19,309,326.33
再来个复杂点的, 看看怎么理解WHERE条件和切片的关系 –
SELECT
{
([Date].[Calendar].[CY 2002])
} ON COLUMNS
FROM [Step-by-Step]
WHERE {
(
[Geography].[Country].[United States],
[Product].[Category].[Bikes]
)
}
查询结果
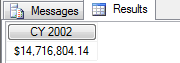
如果已经完全理解了之上的这些例子和分析, 现在一看这个写法就应该能和脑海中的空间图联系起来. Country 这个轴上只保留了 United States 这个点,这个点与其它的轴交互也能形成一个空间,Category这个轴上只保留了Bikes这个点, 这个点与其它的轴交互也能形成一个空间. 再换种方式理解就是认为这些轴本身还是轴, 只不过距离变短了,那么Cube空间自然也就变小了.
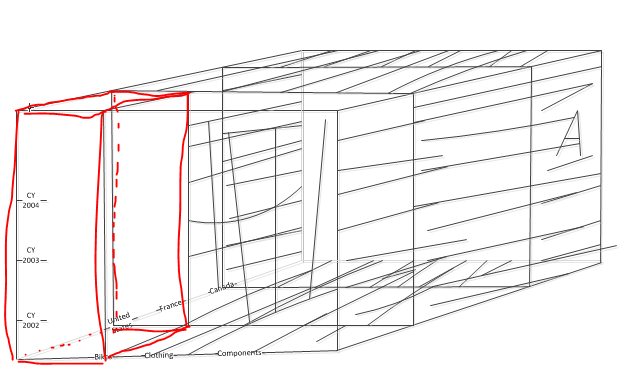
查询的范围就应该是红颜色线条表示的那一块空间, 在这个空间上来定位
CY 2002年时所有Category 在所有国家的销售额, 实际上看这个空间就可以理解为查询 CY2002年时United States的Bikes 销售额, 验证一下
SELECT
{
([Date].[Calendar].[CY 2002],[Geography].[Country].[United States])
} ON COLUMNS,
{
([Product].[Category].[Bikes])
}ON ROWS
FROM [Step-by-Step];
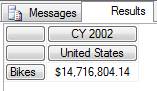
错误的写法 –
SELECT
{
([Date].[Calendar].[CY 2002],[Geography].[Country].[United States])
} ON COLUMNS,
{
([Product].[Category].[Bikes])
} ON ROWS
FROM [Step-by-Step]
WHERE {
([Geography].[Country].[United States])
}
错误的信息 –
Executing the query...
The Country hierarchy already appears in the Axis0 axis.
Execution complete
按照我们的理解, 在WHERE 条件中出现的 United States限定了我们查询的空间, 那么在Tuple 中出现应该是没有问题的. 但是在MDX查询中, 为了避免这种情况,即在限定了 United States 这一空间之后, 在Tuple中还引用了其它的国家, 那么这个引用的空间一定是不存在的,所以为了避免这种情况发生就以错误消息来提示我们要避免这样来引用.
SELECT
{
([Date].[Calendar].[CY 2002],[Geography].[Country].[France])
} ON COLUMNS,
{
([Product].[Category].[Bikes])
} ON ROWS
FROM [Step-by-Step]
WHERE {
([Geography].[Country].[United States])
}
比如像上面这个例子, France 所在的空间已经因为WHERE条件中的United States 被从整个Cube空间切掉了,那么France 这个Member成员自然也就不存在.
再次提醒最好能够把前面所讲的内容
MDX Step by Step 读书笔记 第三章 理解元组
MDX Step by Step 读书笔记 第四章 使用集合
理解透彻后,再来看这篇文章比较适合,因为有很多基础的概念都在里面, 没有这些基础的概念来铺垫可能理解起来会比较困难.


 派可数据,一站式企业级 BI 可视化分析平台
派可数据,一站式企业级 BI 可视化分析平台
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· .NET周刊【3月第1期 2025-03-02】
· [AI/GPT/综述] AI Agent的设计模式综述
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!