
Execution Plan 执行计划介绍
2013-04-11 22:59 BIWORK 阅读(9271) 评论(0) 收藏 举报后面的练习中需要下载 Demo 数据库, 有很多不同的版本, 可以根据个人需要下载. 下载地址 - http://msftdbprodsamples.codeplex.com/
1. 什么是执行计划
- 查询优化器对输入的 T-SQL 查询语句通过"计算"而选择出效率最高的一种执行方案,这个执行方案就是执行计划.
- 执行计划可以告诉你这个查询将会被如何执行或者已经被如何执行过,可以通过执行计划看到 SQL 代码中那些效率比较低的地方.
- 查看执行计划的方式我们可以通过图形化的界面,或者文本,或者XML格式查看,这样会比较方便理解执行计划要表达出来的意思.
- 系统需要更多内存的时候
- 倒数计数器减到 0 了.
- 当前的链接没有引用到这个执行计划.
- Query 所引用的表或者架构等结构发生改变
- Query 所引用的索引发生改变,比如修改或者删除了
- 调用了 sp_recompile 重新编译的时候.
11. 查看系统中已有的执行计划
SELECT [cp].[refcounts]
,[cp].[usecounts]
,[cp].[objtype]
,[st].[dbid]
,[st].[objectid]
,[st].[text]
,[qp].[query_plan]
FROM sys.dm_exec_cached_plans cp
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st
CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle)
qp
执行结果

可以打开一个 Query Plan 来看

12. 为什么 Estimated Execution Plan 和 Actual Execution Plan 不一样
- Estimated Execution Plan 所统计的数据和实际执行的时候数据有变化, 比如Estimated Execution Plan 创建的时候, 数据库只有1000条数据 , 但是在实际执行的时候可能数据在这期间已经发生改变, 因此产生出来的 Actual Execution Plan 可能就不同.
- Estimated Execution Plan 实际上在关系型引擎中创建产生, 因为并不会真正执行SQL 语句. 那么类似于这样的代码在得到 Estimated Execution Plan 的时候会发生错误, 原因就是这个对象不可能在 Estimated Execution Plan 阶段创建因此就会发生错误, 这和 Actual Execution Plan也不同.
CREATE TABLE TempTable
(
Id INT IDENTITY(1, 1)
,Dsc NVARCHAR(50)
);
INSERT INTO TempTable ( Dsc )
SELECT Value
FROM dbo.Brand
SELECT *
FROM TempTable;
DROP TABLE TempTable;
如果点击 "Display Estimated Execution Plan" 将会产生以下错误信息:
Msg 208, Level 16, State 1, Line 6
Invalid object name 'TempTable'.
原因就是 TempTable 是不可能在 Estimated Execution Plan 阶段创建的, 因为还处于在关系引擎控制阶段, 还没有到存储引擎.
13. Execution Plan Formats 执行计划的3种格式 (个人比较喜欢图形执行计划, 但有时也会使用文本执行计划查看具体的数据)
- 图形执行计划 – 非常容易查看和阅读, 但是有一些细节数据被隐藏了
- 文本执行计划 – 读起来有些困难, 但是很多信息可以直接查看. 文本执行计划有3种格式:
- SHOWPLAN_ALL – 显示”估算执行计划”的所有内容
- SHOWPLAN_TEXT – 显示一部分”估算执行计划”的内容
- STATISTICS PROFILE – 和SHOWPLAN_ALL 一样, 不同的是它显示的是”实际执行计划”
- XML 执行计划 - XML 执行计划能够以XML格式反映大多数数据内容.
- SHOWPLAN_XML – 可以理解为”预估执行计划”
- STATISTICS_XML – 显示实际执行计划
SELECT *
FROM [dbo].[DatabaseLog]

Table scan – 出现在当存储引擎强制性的一行一行的遍历整张表或者返回所有内容, 因为我们并没有使用任何的 WHERE 条件并且我们也没有使用到任何的索引(索引上应该包含它所在表上的所有列).
16.对于 Estimated Execution Plan 执行计划

查看查询优化器给出 SELECT 操作符的执行成本情况
- Cached plan size – 在存储过程缓存中由这个查询语句产生的计划所占用内存的大小, 这个数字比较有用, 可以用来调查缓存的性能问题, 特别是某个计划所占的内存非常大的情况下.
- Estimated Operator Cost – 就应该是上图中 SELECT 的耗费
- Estimated Sub tree Cost – 告诉我们这个步骤和之前所有的步骤所累加起来的一个耗费值, 但是看它之前的步骤要注意要从右往左读, 目前 SELECT 步骤的左边没有其他的步骤. 这个值表示的是查询优化器认为这个运算符可能要花费的时间.
- Estimated number of rows – 查询优化器基于一些统计数据得到的, 这里指的是返回的行数.
查看 Table Scan

- Logical Operations – 查询优化器认为对在 Query 语句执行时应该发生的操作 .
- Physical Operations – 实实在在发生的操作. 这两个值大多数情况相同, 但也有不同的时候.
- Estimated number of rows – 再次看到这个值, 实际上每一个步骤的操作可能不相同, 每一个步骤要处理和传递的数据量大小都不一样, 所以从每个步骤中就能看到数据量大小的变化, 有哪些增加了, 有哪些被过滤掉了, 这样也会帮助我们理解整个流程发生了什么.
- Ordered – 告诉我们这个步骤的操作符是否对数据进行了排序操作.
17. 预估的文本执行计划 Getting the Estimated Text Plan
在启用文本的预估执行计划时, 先要打开这个计划.
SET SHOWPLAN_ALL ON; 并且要注意在使用完了之后也一定要 SET SHOWPLAN_ALL OFF.
18. 实际文本执行计划 Getting the Actual Text Plan
SET STATISTICS PROFILE ON SET STATISTICS PROFILE OFF
19. XML 执行计划
Estimated Plan - SET SHOWPLAN_XML ON / SET SHOWPLAN_XML OFF
20. XML 实际执行计划
Actual Plan – SET STATISTICS XML ON / SET STATISTICS XML OFF
21. 如何将XML 计划保存为图形执行计划
可以将XML 格式的执行计划保存为后缀为 “.sqlplan” 的文件, 这个文件显示的就是图形执行计划. 因为有的时候需要把某个执行计划的结果发给其他人来调整我们的SQL 语句.
22. 在 SQL Profiler 中自动捕获执行计划
在实际开发过程中, 可能随时需要查看不同SQL 语句的执行计划, 并且最好是能够自动捕获 SQL 的执行计划以便随时查看有哪些查询耗费的成本比较高, 或者像这种有 Table Scan 的情况都需要被截获并查看他们的执行计划.
在SQL Server 2005可以通过 SQL Profiler 来帮助捕获这些计划, 后期的版本也支持这个功能. 捕获后的计划可以直接在SQL Profiler 中浏览或者保存到文件, 再或者存放到数据库.
在 SQL Profiler 中选中以下几种事件
-
- Showplan XML
-
- RPC:Completed
-
- SQL:BatchStarting
-
- SQL:BatchCompleted

选中 Showplan XML 事件后会出现一个新的Tab – Events Extraction Settings. 在这里可以配置 XML Execution plan 保存的地点以便以后查看, 还可以选择将Execution Plan 保存在一个文件还是每个单独放在一个文件里.
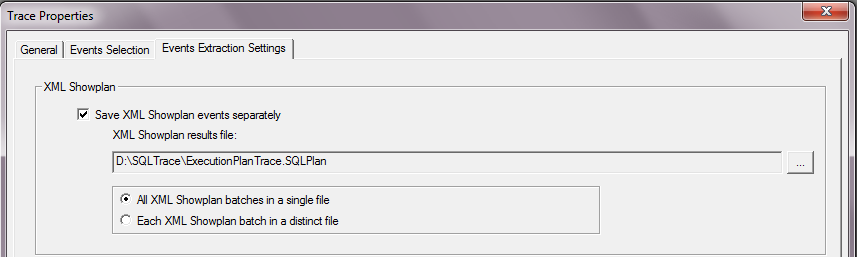
配置完成后点击 ”Run”, 然后就可以在 SQL Profiler 中查看SQL 的执行计划, 并且还可以单独保存成一个文件作为以后分析的依据.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号