from voc dataset to coco dataset
文件结构
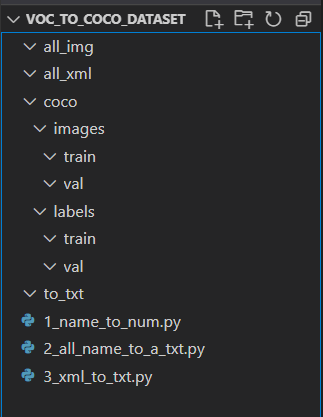
1_name_to_num.py
import os
all_ = os.listdir('all_img')
count = 0
for i in all_:
filename = os.path.join('all_img', i)
new_name = os.path.join('all_img', '{}.jpg'.format(count))
#print(filename, new_name)
os.rename(filename, new_name)
filename = os.path.join('all_xml', i[:-3]+'xml')
new_name = os.path.join('all_xml', '{}.xml'.format(count))
#print(filename, new_name)
#input("!!")
os.rename(filename, new_name)
count+=1
2_all_name_to_a_txt.py
import os
all_ = os.listdir('all_img')
for i in all_:
print(i[:-4])
#input("!!")
f = open('train.txt','a')
f.write(i[:-4]+'\n')
3_xml_to_txt.py
# 导包
import copy
from lxml.etree import Element, SubElement, tostring, ElementTree
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
# 类别列表(根据自己的开发需求的实际情况填写)
classes = ['brand', 'cucumber', 'eggplant', 'tomatoes'] #类别
# label中锚框坐标归一化
def convert(size, box): # size:(原图w,原图h) , box:(xmin,xmax,ymin,ymax)
dw = 1./size[0] # 1./w
dh = 1./size[1] # 1./h
x = (box[0] + box[1])/2.0 # 物体在图中的中心点x坐标
y = (box[2] + box[3])/2.0 # 物体在图中的中心点y坐标
w = box[1] - box[0] # 物体实际像素宽度
h = box[3] - box[2] # 物体实际像素高度
x = x*dw # 物体中心点x的坐标比(相当于 x/原图w)
w = w*dw # 物体宽度的宽度比(相当于 w/原图w)
y = y*dh # 物体中心点y的坐标比(相当于 y/原图h)
h = h*dh # 物体高度的高度比(相当于 h/原图h)
return (x,y,w,h) # 返回相对于原图的物体中心的(x坐标比,y坐标比,宽度比, 高度比),取值范围[0-1]
# Label格式转化
def convert_annotation(image_id):
in_file = open('all_xml/%s.xml'%(image_id)) # 需要转化的标签路径
out_file = open('to_txt/%s.txt'%(image_id),'w') # 生成txt格式的标签文件(label)的保存路径
tree=ET.parse(in_file) # 解析xml文件
root = tree.getroot() # 获取xml文件的根节点
size = root.find('size') # 获取指定节点的图像尺寸
w = int(size.find('width').text) # 获取图像的宽
h = int(size.find('height').text) # 获取图像的高
for obj in root.iter('object'):
cls = obj.find('name').text # xml里的name参数(类别名称)
if cls not in classes :
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
image_ids_train = open(r'./train.txt').read().strip().split() # 汇总所有.jpg图像文件名称的txt清单(上述生成的)
for image_id in image_ids_train:
print(image_id)
convert_annotation(image_id) # 转化标注文件格式
yolov5 demo
主要修改 3 个文件
- coco.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# COCO 2017 dataset http://cocodataset.org by Microsoft
# Example usage: python train.py --data coco.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco ← downloads here (20.1 GB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
#path: ./dataset/coco # dataset root dir
train: ./dataset/coco/images/train # train images (relative to 'path') 118287 images
val: ./dataset/coco/images/val # val images (relative to 'path') 5000 images
#test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
nc: 2 # number of classes
names: ['no_mask', 'mask'] # class names
# Download script/URL (optional)
#download: |
# from utils.general import download, Path
#
#
# # Download labels
# segments = False # segment or box labels
# dir = Path(yaml['path']) # dataset root dir
# url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
# urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labels
# download(urls, dir=dir.parent)
#
# # Download data
# urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images
# 'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images
# 'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)
# download(urls, dir=dir / 'images', threads=3)
- yolov5s.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
- train.py 中的几个参数
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='coco.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=64, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号