团队作业5——测试与发布(Alpha版本)
0.作业声明
| 这个作业属于哪个课程 | 信安1912-软件工程 (广东工业大学 - 计算机学院) |
|---|---|
| 这个作业要求在哪里 | 团队作业5——测试与发布(Alpha版本) |
| 这个作业的目标 | Alpha版本测试报告、Alpha版本发布说明 |
1.作业gitee链接
2.团队展示
1、队名:is-good-bro
2、队员学号
| 队员 | 学号 |
|---|---|
| 陈梓浩(组长) | 3119005455 |
| 罗行健 | 3119005470 |
| 黄浩 | 3119005414 |
| 何子阳 | 3119005413 |
| 苏泽 | 3119005473 |
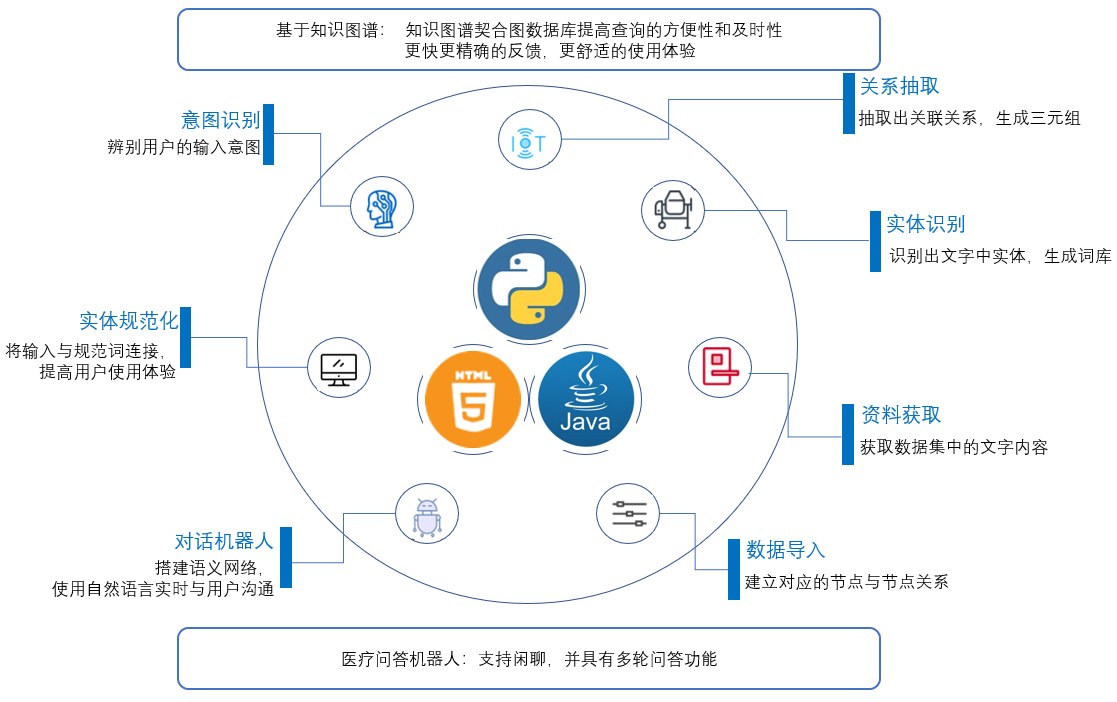
3、拟作的团队项目描述:基于知识图谱的医疗问答机器人
3.Alpha版本测试报告
1、测试过程
①产品背景与定义
针对学龄儿童需要一个准确的医疗诊断机器人,青年群体需要一个即时的医疗咨询机器人,中老年群体需要一个便捷的医疗问答机器人的时代发展背景,我们开发一个基于知识图谱的医疗问答机器人,要求医疗数据包含疾病的定义、症状、治疗方法,拓展疾病的忌吃食物、宜吃食物、通用药品、推荐药品、并发症、治疗科室;要求辨识用户,识别用户输入内容中的意图、实体,缓存用户对话信息,并支持槽位继承和意图继承实现多轮对话
②测试定义与目的
此次测试为模块测试,目的在于已开发好的进行测试,如测试实体识别模块是否能对输入内容进行实体识别,分割出文字中的实体,测试关系抽取模块是否能抽取出文字中的实体关系,测试要求广泛收集测试数据,确保测试的客观准确性,提高测试可信度,并据测试结果向开发人员反馈意见
③测试工具与环境
测试工具:Pycharm
测试环境:
python==3.7
tensorflow==1.14.0
keras==2.3.1
bert4keras==0.10.6
h5py==2.8.0
④测试时间与人员
| 测试内容 | 测试时间 | 测试人员 |
|---|---|---|
| 实体识别模块 | 2天 | 罗行健、苏泽、陈梓浩 |
| 意图识别模块 | 2天 | 黄浩、何子阳、陈梓浩 |
| 模块衔接测试(多轮对话模块) | 3天 | 陈梓浩、罗行健、黄浩 |
⑤测试资源
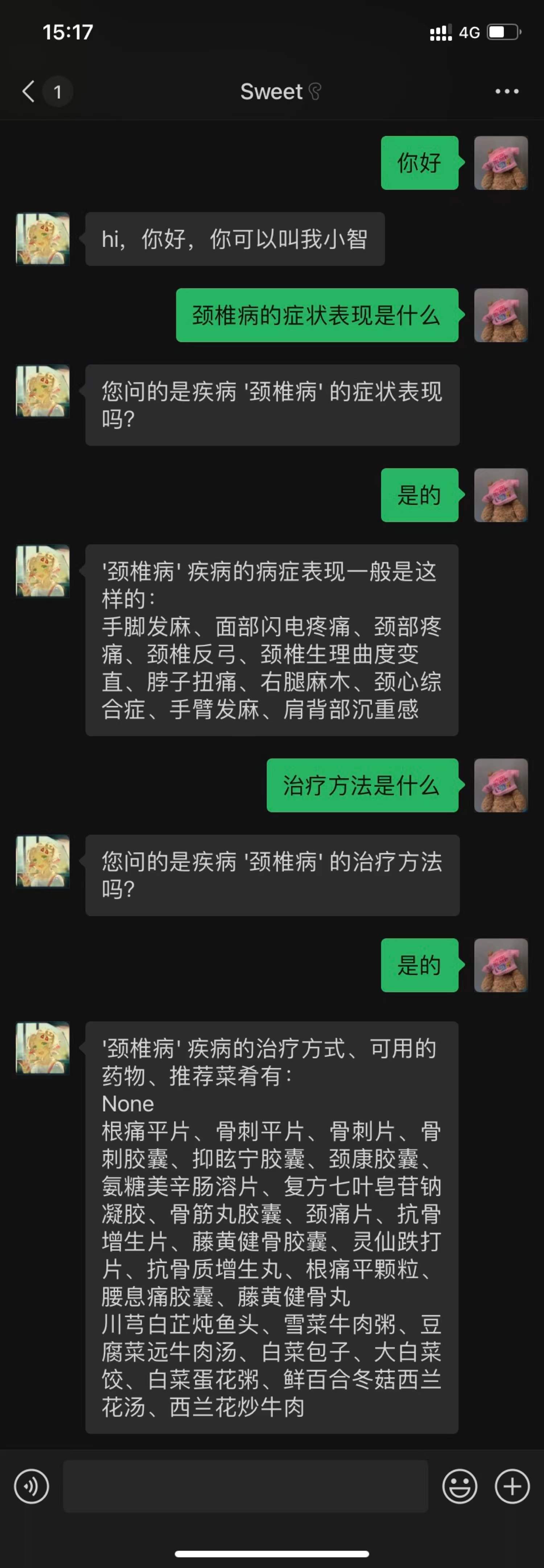
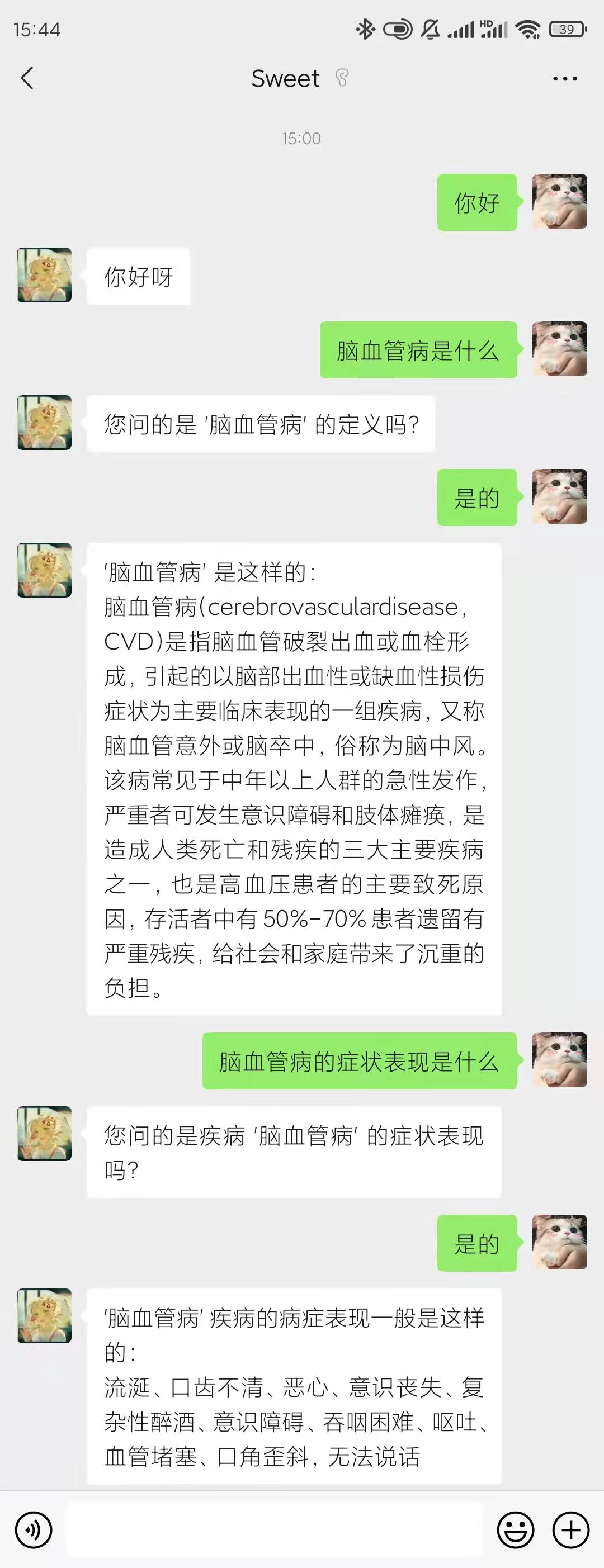
每项测试,测试数据均为100条,30%为测试人员结合自身生活生成,40%为网络收集,30%为交叉测试人员生成,例如实体识别模块,测试数据为“我昨天晚上肠胃炎犯了,而且头痛”,实体识别模块识别出“肠胃炎”疾病实体和“头痛”症状实体,意图识别模块测试数据“你是机器人吗”,模块识别出这句话的意图是闲聊意图范围中的isrobot,多轮对话模块测试数据“心脏病是什么”->“那怎么治疗呢”,模块识别出“那怎么治疗呢”的意图是医疗咨询范围中的询问治疗方法,但对应槽位并没有填充信息,于是继承上一句对话的槽位信息,即做到了多轮对话
⑥测试过程中发现的各类型bug
| 类型(数量) | 简述 | 描述 |
|---|---|---|
| 修复的bug(3) | 无用户标识信息(本地端) | 原因:本程序因为含有多轮对话功能,所以需要程序具有记录用户对话缓存的功能,因此需要获取用户的标识信息,但在本地端中因为只有对话过程,而没有登录过程,所以无用户标识信息。 修复:在对话过程的开始前询问用户的名称,当作用户的标识信息 |
| 无用户标识信息(微信端) | 原因:本程序因为含有多轮对话功能,所以需要程序具有记录用户对话缓存的功能,因此需要获取用户的标识信息,但在微信端不同于本地端,无法识别用户输入的是不是名称,无法通过与本地端相同的办法获取用户标识信息。 修复:将从微信端接收到的消息直接输出,找到微信自带的用户标识信息FromUserName,当作本程序的用户标识信息 |
|
| 查询数据库返回异常 | 原因:后台查询数据库数据,语句是没有错误,在数据库中查询能查询出数据,但是通过项目查询时,返回的数据没办法接收到,由于返回的数据与接收的实体类型不能一一对应,不能直接写入,需要在 cypher 中进行属性的标注,进行写入;还可能发生这样的原因就是在未加@Autowired的注解,导致java.lang.NullPointerException: null异常。 修复: @Query("MATCH (a:疾病)-[r]->(b) WHERE a.name={diseaseName} RETURN type(r) as type,b.name AS name") List @Query("MATCH (a:疾病)-[r]->(b) WHERE b.name={name} RETURN type(r) as type,a as disease") List |
|
| 不能重现的bug(2) | 程序运行卡死 | 原因:本程序的资源较多和所需运行内存较大,需要调用多个模型以实现项目功能,所以需要一定程度的硬件配置,当运行机器的配置在瞬时达不到要求时,程序运行将会卡死,但该bug出现的几率较低,所以不能重现 修复:提高硬件配置,或刷新机器内存 |
| 缓存增删查改异常 | 原因:在管理员对缓存进行增删查改的期间,由程序原本逻辑产生的缓存写入会被覆盖或无法写入,修改缓存的过程需要先将缓存读入内存后再对缓存项进行操作,在管理员读取缓存进入内存之后程序原本逻辑对缓存文件的写入将无法被读取到,由于管理员实际操作缓存的时间非常短,碰撞出现机率低; 修复:即使碰撞出现,造成的后果是程序缓存写入失败,此后果影响很小,下次再次写入即可 |
|
| 这个产品就是这样设计的,不是bug(1) | 无法回复用户的其他意图信息 | 原因:本程序仅设计了闲聊和医疗咨询功能,不具备文学、工学、网络词互动等其他功能,面对此类信息,程序将会识别为其他意图,并回复机器人暂不能理解 |
| 没有能力修复,将来也不打算修复(1) | 无法回复用户发送的动画表情和emoji信息 | 原因:想要做到识别动画表情和emoji信息,需要具有多模态交互,联邦学习的知识,才可以做到让程序理解表情中的信息,并转化为文字信息,目前团队成员不具备这个知识,且该知识点所需的学习时间较长,所以此bug不作修复打算 |
| 这个bug的确应该修复,但是没有时间在这个版本修复,延迟到下一个版本修复(1) | 无法回复用户发送的部分闲聊和医疗咨询信息 | 原因:本程序由于所需知识点较多和所需搭建时间较长,所以目前仅设计了部分闲聊意图和咨询意图的数据集供程序模型学习,并不能实现识别大部分闲聊和咨询信息 修复:扩增数据集和重新训练模型,理论和知识储备上都可以实现,因为目前阶段没有时间修复,所以延迟到下一个版本修复 |
2、测试结果
①预期不同的用户的使用、需求和目标
| 用户群体 | 需求 | 目标和使用 |
|---|---|---|
| 学龄儿童 | 一个准确的医疗诊断机器人 | 询问身体上的异常,由于人口老龄化趋势导致年轻人的压力增大,越来越多的年轻人选择外出打拼,将孩子交给祖辈看护,但是祖辈的科学知识并不充裕,存在很多封建土方,比如孩子发烧通过厚被闷汗出热治病,但是这其实没有任何正效应,甚至可能导致加重发烧,避免因误判或过晚发现身体上的异常,容易造成不可估量的无法挽回后果,保证准确性 |
| 青年群体 | 一个即时的医疗咨询机器人 | 询问一些日常生活中的不适情况,青年身体有异常习惯通过挺两天尝试自愈,但是并非每种情况都可以靠身体自愈,而且为了方便,通常选择网络查病,但例如百度,经常随便一问都是癌症征兆或者晚期,不仅没实际效果,而且会导致心理焦虑,保证即时性,及时保障自身健康 |
| 中老年人 | 一个便捷的医疗问答机器人 | 询问服用药品的剂量和时间,防止影响治疗效果,且保证便捷性 |
②如何满足用户的需求
| 需求 | 实现 |
|---|---|
| 用户输入信息 | 本地端、微信端、网页端界面 |
| 识别输入中的实体 | 实体识别模块,实体规范化模块 |
| 识别输入中的意图 | 意图识别模块 |
| 多轮对话 | 用户标识,对话缓存 |
| 准确性 | 搜索引擎、医院等数据集 |
| 即时性 | neo4j图数据库,比mysql数据库更快的响应速度 |
| 便捷性 | 本地端、微信端、网页端 |
③测试矩阵
| 配置配置 | 服务端/客户端 | 本地端 | 微信端 |
|---|---|---|---|
| 联想拯救者 Y7000P GTX 1660Ti i5-9300H DDR4 16GB python 3.7 PyCharm 2020.3 wechat 3.4.5.22 |
服务端 客户端 |
√ | √ |
| 联想拯救者 Y7000 GTX 1650 i5-9300H DDR4 8GB python 3.7 PyCharm 2020.3 wechat 3.4.0.38 |
服务端 客户端 |
√ | √ |
| 联想 82DM AMD Radeon Graphics AMD Ryzen 5 4600U RAM 16384MB wechat 3.4.5.22 |
客户端 | / | √ |
| 联想拯救者 Y7000 GTX 1650 i5-9300H DDR4 8GB wechat 3.4.0.38 |
客户端 | / | √ |
| 戴尔 G3 GTX 1650 i7-9750H DDR4 16GB wechat 3.4.0.38 |
客户端 | / | √ |
| 戴尔 Inspiron i5-9300H GTX 1050 DDR4 8GB wechat 3.4.0.38 |
客户端 | / | √ |
| 黑鲨游戏手机 2 Pro JOYUI 12.5 21.10.20 wechat 8.0.16 |
客户端 | / | √ |
| iPhone XR ios 14.4.1 wechat 8.0.16 |
客户端 | / | √ |
| iPhone 13 ios 15.1.1 wechat 8.0.16 |
客户端 | / | √ |
| 红米 K20 Pro MIUI 12.5.6 wechat 8.0.16 |
客户端 | / | √ |
| 华为 NOVA7 HarmonyOS 2.0.0 wechat 8.0.16 |
客户端 | / | √ |
| 红米 Note10 Pro MIUI 12.5.8 wechat 8.0.15 |
客户端 | / | √ |
| 真我 GT realmeUI 2.0 wechat 8.0.16 |
客户端 | / | √ |
| 小米 10 MIUI 12.5.10 wechat 8.0.15 |
客户端 | / | √ |
| 红米 K20 Pro MIUI 12.0.2 wechat 8.0.15 |
客户端 | / | √ |
| 华为 P30 Pro HarmonyOS 2.0.0 wechat 8.0.16 |
客户端 | / | √ |
④出口条件
通过以上16个不同配置的设备的测试,实现在0.5s内回复本地端咨询,在1s内回复微信端咨询,本团队认为该项目已经足够好,可以发布Alpha版本
⑤部分测试截图

4.Alpha版本发布说明
1、功能
| 功能模块 | 实现需求解决说明 |
|---|---|
| 前端 | 提供输入界面和输入方法,获取用户输入 |
| 后端 | 使用Java语言进行设计开发,使用版本为Java11。在设计过程中采用了SpringBoot框架进行开发,期间调用了Neo4j图形数据库进行数据存储,后续通过Java语言设计接口,实现了对数据库中节点数据的模糊搜索 |
| 实体识别 | 使用BILSTM-CRF模型对用户输入进行命名实体识别预测,识别出用户输入中疾病、器官、症状、人群、治疗、时间等实体,提供给后期对话机器人使用 |
| 关系抽取 | 使用CasRel模型对病症数据进行实体关系抽取预测,抽取出病症数据中疾病、器官、症状、人群、治疗、时间等实体的关联关系,生成三元组,保存为关系文本文件,提供给后期数据导入作为预处理后的数据使用 |
| 数据导入 | 将实体识别生成的词库文本文件和关系抽取获得的关系三元组文本文件,使用python编写批处理程序,先使用词库在neo4j图数据库建立对应的节点,并将关系三元组中的内容以此使用CQL语句向neo4j数据库输入,建立节点之间的关系,提供给后期对话机器人使用 |
| 实体规范化 | 当涉及到使用本项目进行查询相关信息时,为减少误输和错输对用户产生的体验影响,使用bm25算法+esim模型进行实体规范化训练,收集常错输入与规范词的数据,如将“你好”误输为“nihao”,将输入与规范词进行实体连接,使得即使错输部分词语也能正确反馈,提供给后期对话机器人使用 |
| 意图识别 | 使用bert+textCNN模型进行意图识别训练,可以用来辨别用户的输入意图是什么,如用户输入“你好”,对话机器人可以识别出这是问好意图,回复“你好,我是信息查询机器人”;用户输入“查询XXX信息”,机器人可以识别出这是查询意图,提供给后期对话机器人使用 |
| 对话机器人 | 调用前面的实体识别等多个部分,对用户的输入进行自然语言理解,得出用户的对话意图和关键词,如用户输入“心脏病是什么”,机器人就可以识别出这是查询意图,并且是查询关键词是心脏病,从neo4j数据库查询相关信息并返回给用户 |
| 对话缓存 | 将用户上一句查询意图输入经实体识别后得到的槽位信息保存,当下一句输入缺乏槽位信息时进行槽位继承,使得实现多轮对话 |
2、修复的缺陷
| 缺陷 | 描述 |
|---|---|
| 无用户标识信息(本地端) | 原因:本程序因为含有多轮对话功能,所以需要程序具有记录用户对话缓存的功能,因此需要获取用户的标识信息,但在本地端中因为只有对话过程,而没有登录过程,所以无用户标识信息。 修复:在对话过程的开始前询问用户的名称,当作用户的标识信息 |
| 无用户标识信息(微信端) | 原因:本程序因为含有多轮对话功能,所以需要程序具有记录用户对话缓存的功能,因此需要获取用户的标识信息,但在微信端不同于本地端,无法识别用户输入的是不是名称,无法通过与本地端相同的办法获取用户标识信息。 修复:将从微信端接收到的消息直接输出,找到微信自带的用户标识信息FromUserName,当作本程序的用户标识信息 |
| 查询数据库返回异常 | 原因:后台查询数据库数据,语句是没有错误,在数据库中查询能查询出数据,但是通过项目查询时,返回的数据没办法接收到,由于返回的数据与接收的实体类型不能一一对应,不能直接写入,需要在 cypher 中进行属性的标注,进行写入;还可能发生这样的原因就是在未加@Autowired的注解,导致java.lang.NullPointerException: null异常。 修复: @Query("MATCH (a:疾病)-[r]->(b) WHERE a.name={diseaseName} RETURN type(r) as type,b.name AS name") List @Query("MATCH (a:疾病)-[r]->(b) WHERE b.name={name} RETURN type(r) as type,a as disease") List |
3、运行环境要求
| 模式 | 环境要求 |
|---|---|
| 本地端(既为服务端又为客户端) | python 3.7 tensorflow 1.14.0 keras 2.3.1 bert4keras 0.10.6 h5py 2.8.0 运行内存 4GB |
| 微信端(服务端) | python 3.7 tensorflow 1.14.0 keras 2.3.1 bert4keras 0.10.6 h5py 2.8.0 itchat-uos 1.4.1 运行内存 4GB |
| 微信端(客户端) | wechat>=8.0.0 |
4、安装方法
| 模式 | 安装 |
|---|---|
| 本地端(既为服务端又为客户端) | 使用语句“pip install ...”按上表依次安装库,注意不要颠倒顺序,否则会因为各库的包版本不一致导致程序运行出错,运行“build_kg_utils.py”将数据写入本地的neo4j数据库,运行“terminal.py”开启本项目的本地端版本 |
| 微信端(服务端) | 使用语句“pip install ...”按上表依次安装库,注意不要颠倒顺序,否则会因为各库的包版本不一致导致程序运行出错,运行“build_kg_utils.py”将数据写入本地的neo4j数据库,运行“wechat_api.py”开启本项目的微信端版本,使用手机微信扫描二维码登录,即让本项目的问答机器人架设到登录的微信账号上 |
| 微信端(客户端) | 添加架设了本项目问答机器人的微信账号,在聊天框中直接输入内容进行咨询 |
5、系统已知的问题和限制
| 问题和限制 | 描述 |
|---|---|
| 无法回复用户的其他意图信息 | 原因:本程序仅设计了闲聊和医疗咨询功能,不具备文学、工学、网络词互动等其他功能,面对此类信息,程序将会识别为其他意图,并回复机器人暂不能理解 |
| 无法回复用户发送的动画表情和emoji信息 | 原因:想要做到识别动画表情和emoji信息,需要具有多模态交互,联邦学习的知识,才可以做到让程序理解表情中的信息,并转化为文字信息,目前团队成员不具备这个知识,且该知识点所需的学习时间较长,所以此bug不作修复打算 |
| 无法回复用户发送的部分闲聊和医疗咨询信息 | 原因:本程序由于所需知识点较多和所需搭建时间较长,所以目前仅设计了部分闲聊意图和咨询意图的数据集供程序模型学习,并不能实现识别大部分闲聊和咨询信息 修复:扩增数据集和重新训练模型,理论和知识储备上都可以实现,因为目前阶段没有时间修复,所以延迟到下一个版本修复 |
6、软件的发布方式以及发布地址
①本地端,在gitee上开源,作业gitee链接,直接下载
②微信端,在本团队开启微信测试号的时间,扫描下方二维码添加

③网页端,点击以下链接访问

 浙公网安备 33010602011771号
浙公网安备 33010602011771号