

jemalloc总结
jemalloc支持SMP系统和并发多线程,多线程的支持是依赖于多个‘arenas’,并且一个线程第一次调用内存mallocer,与其相关联的是一个特殊的arena。
线程分配arena只有三种可能的算法:
- TLS启用的情况下就是线程ID的哈希值
- TLS不可用并定义MALLOC_BALANCE的情况下通过内置线性同余随机数生成器
- 使用传统的循环算法
对于后两种情况,线程的整个生命周期中线程和arena的关联不会一直保持不变。
核心概念
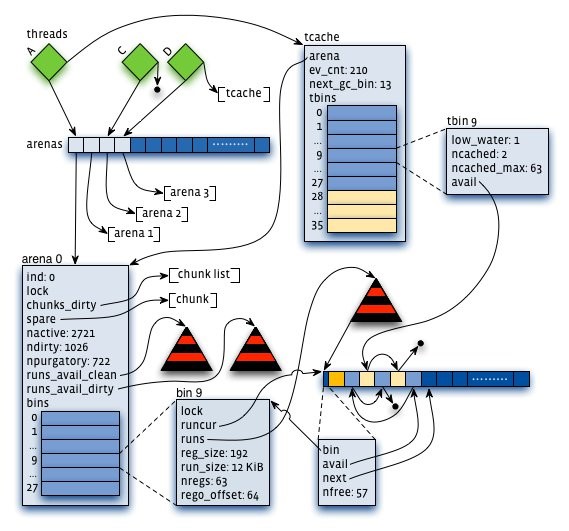
- arena:jemalloc的核心分配管理区域,对于多核系统,会默认分配4*cores的Arena,线程第一次分配small和large对象采用轮询的方式来选择相应的arena来进行内存分配(以后固定)。
struct arena_s {
...
/* 当前arena管理的dirty chunks */
arena_chunk_tree_t chunks_dirty;
/* arena缓存的最近释放的chunk, 每个arena一个spare chunk */
arena_chunk_t *spare;
/* 当前arena中正在使用的page数. */
size_t nactive;
/*当前arana中未使用的dirty page数*/
size_t ndirty;
/* 需要清理的page的大概数目 */
size_t npurgatory;
/* 当前arena可获得的runs构成的红黑树, */
/* 红黑树按大小/地址顺序进行排列。 分配run时采用first-best-fit策略*/
arena_avail_tree_t runs_avail;
/* bins储存不同大小size的内存区域 */
arena_bin_t bins[NBINS];
};
- chunk:具体进行内存分配的区域,目前的默认大小是4M。chunk以page(默认为4K)为单位进行管理,每个chunk的前几个page(默认是6个)用于存储后面所有page的状态,比如是否待分配还是已经分配;而后面的所有page则用于进行实际的分配。
/* Arena chunk header. */
struct arena_chunk_s {
/* 管理当前chunk的Arena */
arena_t *arena;
/* 链接到所属arena的dirty chunks树的节点*/
rb_node(arena_chunk_t) dirty_link;
/* 脏页数 */
size_t ndirty;
/* 空闲run数 Number of available runs. */
size_t nruns_avail;
/* 相邻的run数,清理的时候可以合并的run */
size_t nruns_adjac;
/* 用来跟踪chunk使用状况的关于page的map, 它的下标对应于run在chunk中的位置,通过加map_bias不跟踪chunk 头部的信息
* 通过加map_bias不跟踪chunk 头部的信息
*/
arena_chunk_map_t map[1]; /* Dynamically sized. */
};
- bin:与ptmalloc的bin功能类似
struct arena_bin_s{
// 作用域当前数据结构的锁*
malloc_mutex_t lock;
/* 当前正在使用的run */
arena_run_t *runcur;
/* 可用的run构成的红黑树, 主要用于runcur用完的时候。在查找可用run时,
* 为保证对象紧凑分布,尽量从低地址开始查找,减少快要空闲的chunk的数量
*/
arena_run_tree_t runs;
/* 用于bin统计 */
malloc_bin_stats_t stats;
};
- run:每个bin在实际上是通过对它对应的正在运行的Run进行操作来进行分配的,一个run实际上就是chunk里的一块区域,大小是page的整数倍,具体由实际的bin来决定,比如8字节的bin对应的run就只有1个page,可以从里面选取一个8字节的块进行分配。在run的最开头会存储着这个run的信息,比如还有多少个块可供分配。
struct arena_run_s {
/* 所属的bin */
arena_bin_t *bin;
/*下一块可分配区域的索引 */
uint32_t nextind;
/* 当前run中空闲块数目. */
unsigned nfree;
};
- tcache:线程私有缓存
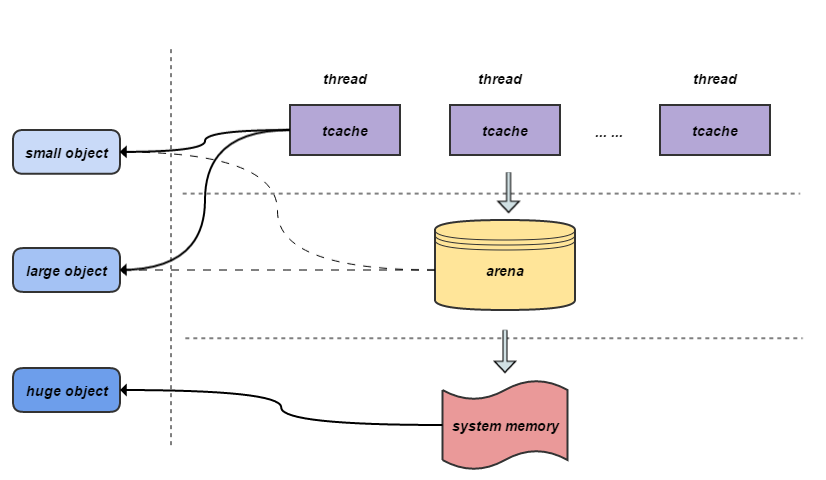
Jemalloc 把内存分配分为了三个部分:
- Small objects的size以8字节,16字节,32字节等分隔开的,小于页大小
- Large objects的size以分页为单位,等差间隔排列,小于chunk的大小
- Huge objects的大小是chunk大小的整数倍
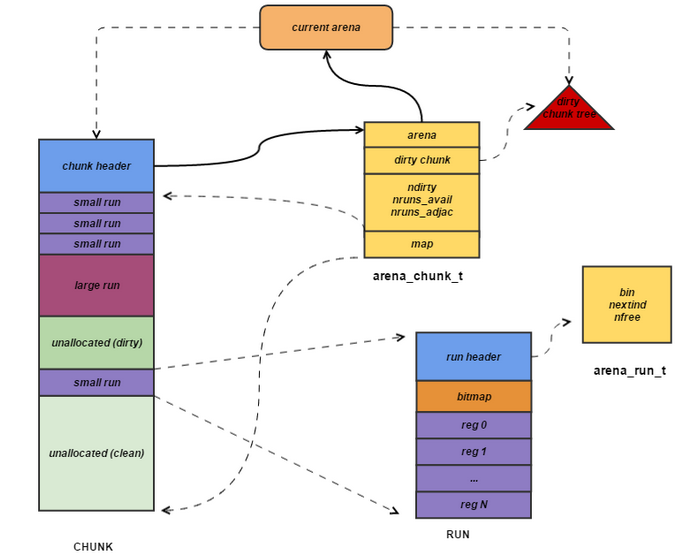
相互关系
arena -> bin数组 -> 通过正在运行的run分配
tcache -> tbin数组(比arena中的长,可以缓存到32K)
chunk(默认4M) -> 多个run(实际分配的操作对象,页的整数倍)
内存分配
申请small内存(小于4K)
- tcache分配,通过size的大小确定属于哪个tbin。如果tbin中有缓存,分配返回。如果没有,跳到2
- 获取一个arena,对bin加锁。从arena的bin中分配一个run,如果没有剩余run,通过红黑树从bin中里面找到run,然后分配给tcache;如果bin的红黑树也没有run,那么从aarena的红黑树中申请run;如果arena的红黑树也没有run,那就只能申请一个新的chunk了。将这个run,加入tcache,然后资源从tcache返回。
申请large内存(4k - 32k)
- tcache分配,通过size的大小确定属于哪个tbin。如果tbin中有缓存,分配返回。如果没有,跳到2
- 获取一个arena。因为此时申请的size大于bin的最大长度,所以直接从通过areba的红黑树申请一块run;如果arena的红黑树也没有run,那就只能申请一个新的chunk了。
申请large内存(大于32K,小于4M)
同上第2步
申请huge的内存(大于等于4M)
直接mmap分配
内存释放
在内存分配时,jemalloc 按照 small/large/huge allocation 来特殊处理。因此,释放时,需要由地址来判断为何种分配类型。
我们知道分配出去的空间,都属于某个 chunk,首先通过将地址对齐到 标准 chunk 大小,找到所属 chunk
- 对于 huge allocation,free 的地址本身在 chunk 边界上。搜索全局的 huge 树来获得本次分配的长度。
- 对于 small/large allocation,根据 free 的地址所在页在 chunk 内的相对页号,访问 chunk 头部的 arena_chunk_map_t 数组。如下图所示
![image]()
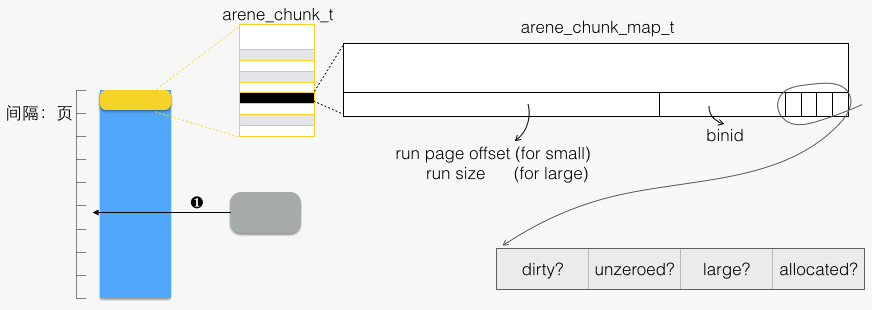
tcache中释放对象
- 释放一段 region,首先要知道所属 bin(tcache_bin_t)。Q:如何找到所属 bin?可以从对应 arena_chunk_map_t 成员中的 binid 域。
- tcache_bin_t 用指针数组来收纳释放的内存,这是一个栈的结构。最近释放的内存放在栈顶,使得下次被先分配出去。如此能保持 cache 热度。
- tcache_bin_t 满了以后,或者 GC 事件被触发,则降低 tcache_bin_t 中缓冲内存的数量(栈底 N 个内存刷回)
- 当region归还给run,这时会产生两个可能影响。Q:如何找到run,通过arena_chunk_map_t 成员中的 run page offset域
- 当原来全用完的 run,现在有一个 region 可分配了,将其插入所属 bin 中,供分配。
- 当 run 全空了,则释放之:从所属 bin中移除,并将空间交还给arena.runs_avail。
- 当chunk中的run完全回收后,可能会导致chunk的回收。对于chunk的回收,如果是mmap分配的页面,会通过ummap释放,而不是放入chunks_szad 全局红黑树。如果是sbrk分配的页面,会通过madvise释放物理页面,虚拟地址放入全局红黑树中。
垃圾回收
jemalloc 中,有两个层面的回收,一是 tcache 中多余缓冲赶到 arena 中;二是将 arena.runs_avail 中多余的物理内存释放掉一些。
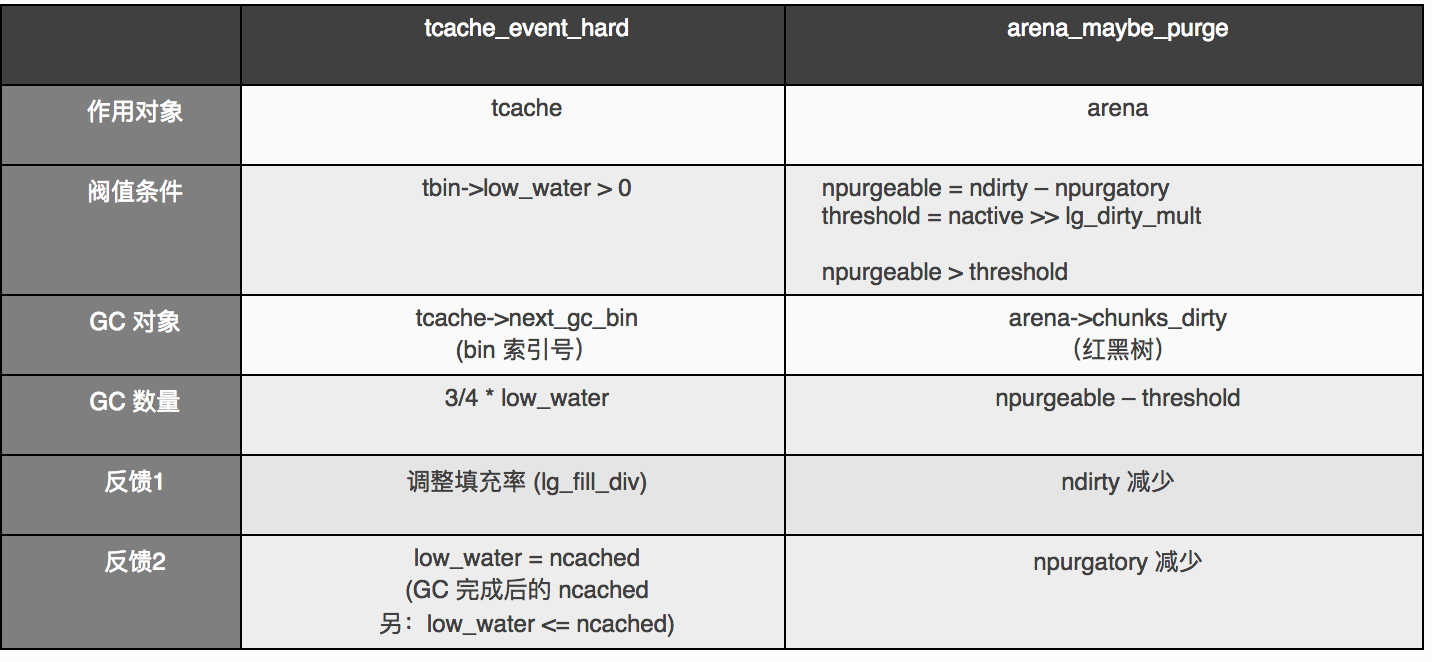
内存区域的额外属性
- dirty: 一个内存区域被分配出去以后,就是“脏”的。
- 一个run回收后会尝试与后半部分干净的run合并。或者与前半部分dirty的run进行合并。
总结
- jemalloc中的层层缓存
- tcache 过多的内存缓冲 —— GC 会处理的。
- arena.bins —— for small allocation,无处理。
- arena.avail_runs —— GC 会处理的。
- arena->spare —— 如果是 dirty 的,无处理。保持直到有新释放的 chunk 进入 spare,挤走本座。
- 内部使用的缓冲 —— 无处理。
- chunks_szad —— 无物理内存占用。
- jemalloc 的设计思路
-
减少多线程竞争。例如引入 tcache,以及线程均分布到若干个 arena(s)。
-
地址空间重用,减少碎片:
-
Small allocation,“归档位”、从各 runs 中分配
-
红黑树来保证同等条件下,总是从低地址开始分配
-
合并相邻的空闲空间
-
-
保持 cache 热度,例如 tcache,地址空间重用
-
各种对齐,自然对齐,cache line 对齐
缺点:
- 缓存过多,内部碎片严重

 浙公网安备 33010602011771号
浙公网安备 33010602011771号