solo2试跑报错记录
跑自己训练集前,注意自己的gpu个数和选用的训练文件对应!
1.solov2训练自己数据集
1.1先跑通demo
demo跑通说明环境配置没有问题
出现UserWarning: This overload of nonzero is deprecated,说torch的nonzero要用个as_type的参数(nonzero(*, bool as_tuple))
跳到相应文件下把inds = inds.nonzero改成inds = inds.nonzero(as_type=false)就行
1.2整理自己的数据集
1.2.1数据集格式
labelme标注后转为coco格式(annotations下放labelme转coco后的合并json文件,train和val里面放的是你用来训练的原图!),路径如下
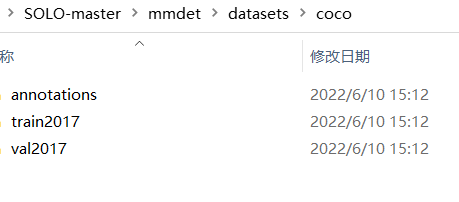
1.2.2添加上自己的数据集
-
路径:SOLO-master/mmdet/core/evaluation/class_names.py
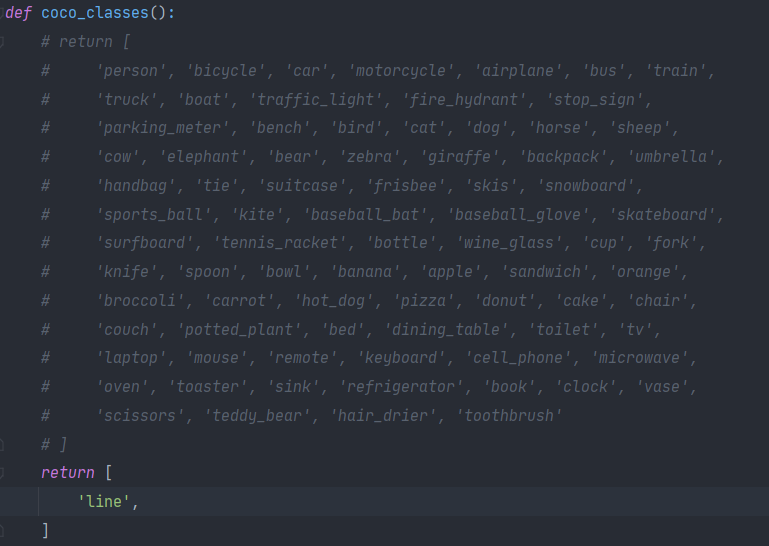
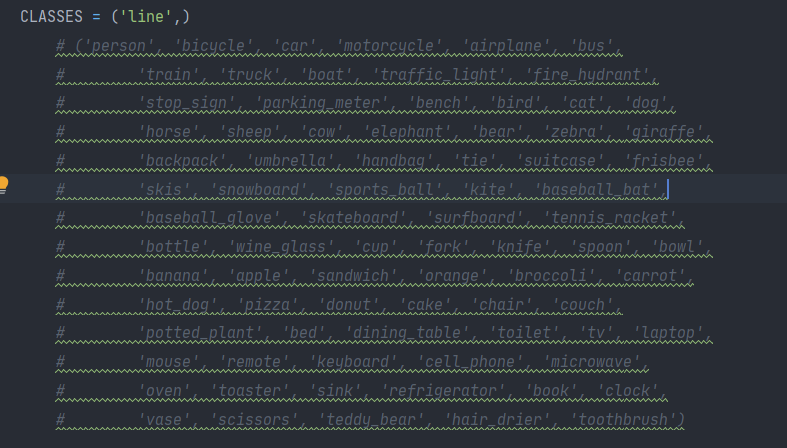
-
路径:SOLO-master/mmdet/datasets/coco.py
1.2.3修改配置文件
按照自己的需求选择配置文件,我用的是SOLO-master\configs\solov2\solov2_r50_fpn_8gpu_3x.py,对应的权重文件是SOLO-master\checkpoints\SOLOv2_R50_3x.pth(要自己下载放到对应路径,solo项目里给出了)
# model settings
model = dict(
type='SOLOv2',
pretrained='torchvision://resnet50',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3), # C2, C3, C4, C5
frozen_stages=1,
style='pytorch'),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=0,
num_outs=5),
bbox_head=dict(
type='SOLOv2Head',
num_classes=2,
in_channels=256,
stacked_convs=4,
seg_feat_channels=512,
strides=[8, 8, 16, 32, 32],
scale_ranges=((1, 96), (48, 192), (96, 384), (192, 768), (384, 2048)),
sigma=0.2,
num_grids=[40, 36, 24, 16, 12],
ins_out_channels=256,
loss_ins=dict(
type='DiceLoss',
use_sigmoid=True,
loss_weight=3.0),
loss_cate=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0)),
mask_feat_head=dict(
type='MaskFeatHead',
in_channels=256,
out_channels=128,
start_level=0,
end_level=3,
num_classes=256,
norm_cfg=dict(type='GN', num_groups=32, requires_grad=True)),
)
# training and testing settings
train_cfg = dict()
test_cfg = dict(
nms_pre=500,
score_thr=0.1,
mask_thr=0.5,
update_thr=0.05,
kernel='gaussian', # gaussian/linear
sigma=2.0,
max_per_img=100)
# dataset settings
dataset_type = 'my_data'
data_root = 'D:/view/things/SOLO-master/mmdet/datasets/coco/'
# data_root = 'mmdet/datasets/coco/'# 自己的数据集路径
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(type='Resize',
img_scale=[(548,192),],# 自己要训练的图片大小
# img_scale=[(1333, 800), (1333, 768), (1333, 736),
# (1333, 704), (1333, 672), (1333, 640)],
multiscale_mode='value',
keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale = (548,192),
# img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
imgs_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/train.json',
img_prefix=data_root + 'train/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/val.json',
img_prefix=data_root + 'val/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/val.json',
img_prefix=data_root + 'val/',
pipeline=test_pipeline))
# optimizer
optimizer = dict(type='SGD', lr=0.00125, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
# learning policy
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.01,
step=[27, 33])
checkpoint_config = dict(interval=1)
# yapf:disable
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook'),
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
# runtime settings
total_epochs = 36
device_ids = range(8)
dist_params = dict(backend='nccl')
log_level = 'INFO'
work_dir = './work_dirs/solov2_release_r50_fpn_8gpu_3x'
load_from = None
resume_from = None
workflow = [('train', 1)]
python tools/train.py configs/solov2/solov2_r50_fpn_8gpu_3x.py
2.一堆报错
2.1 KeyError: Caught KeyError in DataLoader worker process 0.KeyError: -2
是torch报错:在迭代过程中,测试集没有重置索引,索引混乱
看到
我初次接触这种图像分割的内容,参考了
后来我修改workers_per_gpu=0,成为报错gt_labels.append(self.cat2label[ann['category_id']]),不再是torch的报错
跳转,锁定到

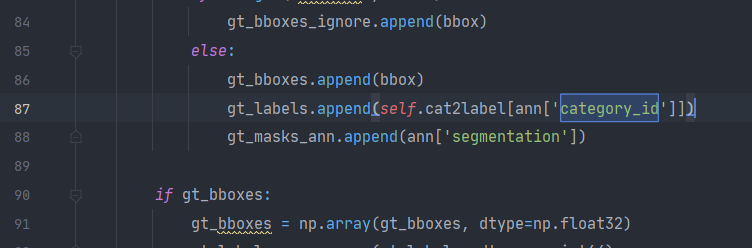
这里的category_id对应错误,我打开annotations下的json文件查看

print(ann)发现category_id不同

是我曾在labelme转化coco格式的脚本中修改了category_id的定义,之前有个博文说这里-1能将背景也作为一个标记出来,先改回原来的默认值
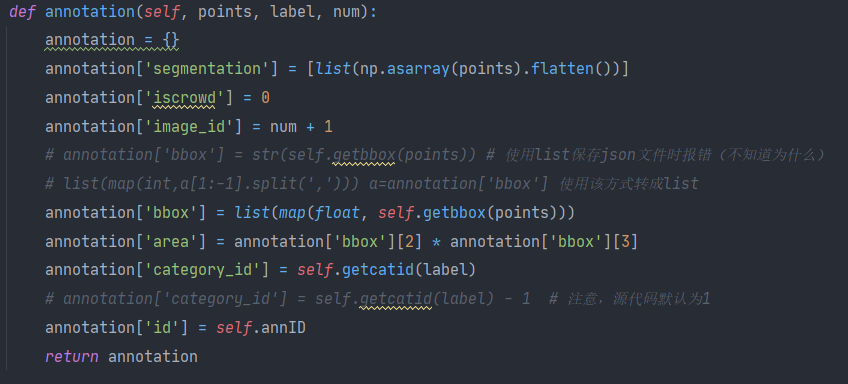
2.2 File "<array_function internals>", line 6, in concatenate.ValueError: need at least one array to concatenate
出现这个问题一定是和数据集有关的错误(路径、标签格式)【对,路径错误也会报这个错】
说标签错误,跳到实现迭代的函数下康康,在循环最后输出indices发现为空,在循环中间输出indice康康,这里发现print(indice)却没有任何输出
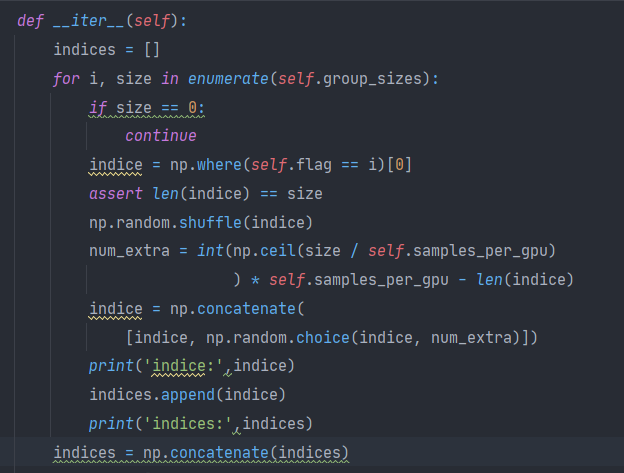
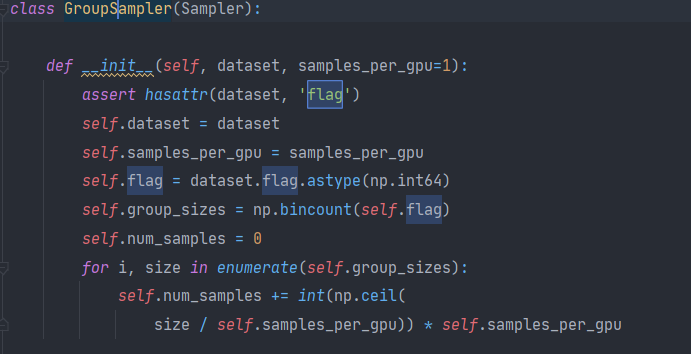
调了半天发现是flag为空list,上翻flag的定义,发现flag是在自定义的Sampler下,且已检查flag为存在,说明整理数据集时,flag就没有做好。但是我找了加载数据的地方,并没有提到flag,这里是第一次定义,也就是说数据本身是存在flag标签的,但是我用来训练的数据没有
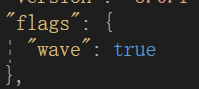
重新把数据集整理后,可以看到每张图单个的json文件里出现了flag
不必要添加background,有人想把背景和标签分隔开,如果只是做前景的标签识别,不用
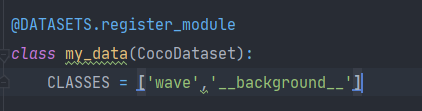
检查数据集每一个部分的读取是否对应
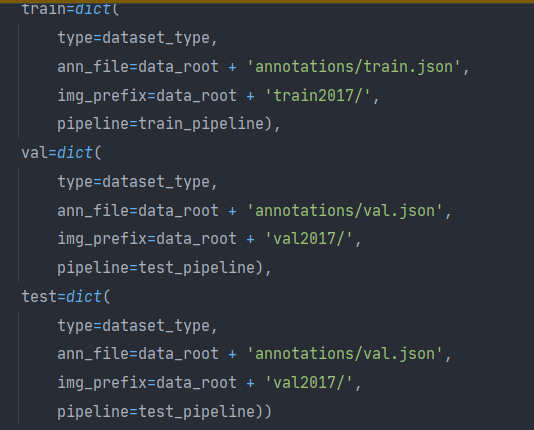
解决方案:
再把数据集的绝对路径改为相对路径(

注意用的数据集,train和val文件夹下放的都是标注前的原图!不要用经过标注中的图像->也会导致相应错误!!
2.3 OSError: symbolic link privilege not held
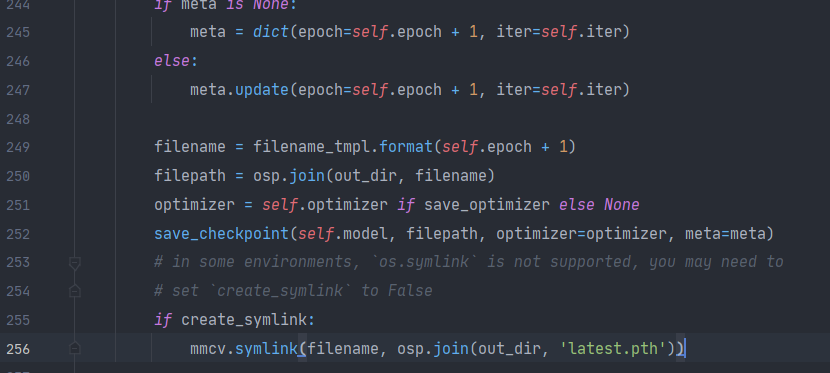
解决方案:尝试用管理员权限打开pycharm再跑一遍
其他可能:参考这篇
题外话,可算是跑起来了,只能说在跑网络前多检查几遍自己数据集的配置,以免训练自己数据集的时候因为它配置不对而报错(尤其是这时候的报错信息很难让人联想到本身的数据集出错了,error列出的内容和实际有问题的地方偏差会很大)
调试工具
除了pycharm自带的调试功能,推荐一个也很方便的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号