在并发编程中,我们经常会使用容器来存储数据或对象,可以依据场景的变化选择多种容器。
Map并发容器
因为在 JDK1.7 之前,在并发场景下使用 HashMap 会出现死循环,从而导致 CPU 使用率居高不下,而扩容是导致死循环的主要原因。虽然 Java 在 JDK1.8 中修复了 HashMap 扩容导致的死循环问题,但在高并发场景下,依然会有数据丢失以及不准确的情况出现。
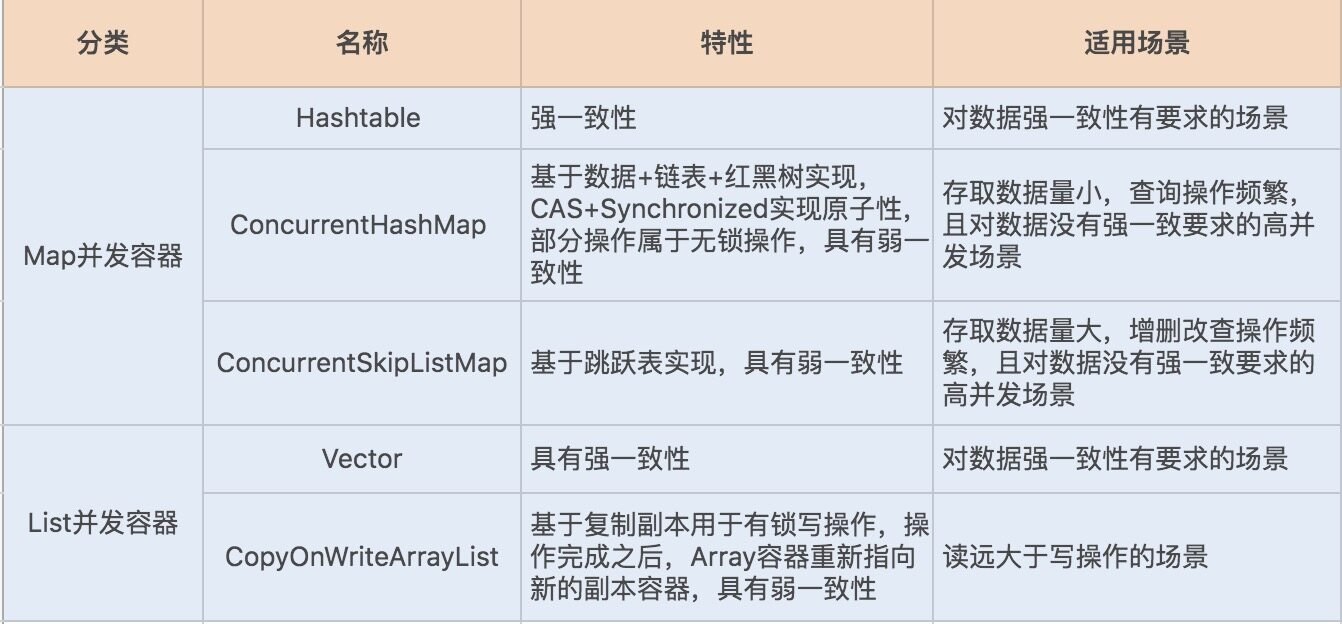
Java 实现了线程安全的 Hashtable、ConcurrentHashMap 以及ConcurrentSkipListMap 等 Map 容器。
Hashtable、ConcurrentHashMap 是基于 HashMap 实现的,对于小数据量的存取比较有优势。
ConcurrentSkipListMap 是基于 TreeMap 的设计原理实现的,略有不同的是前者基于跳表实现,后者基于红黑树实现,ConcurrentSkipListMap 的特点是存取平均时间复杂度是 O(log(n)),适用于大数据量存取的场景,最常见的是基于跳跃表实现的数据量比较大的缓存。
1、注意ConcurrentHashMap弱一致
要注意一点,虽然 ConcurrentHashMap 的整体性能要优于 Hashtable,但在某些场景中,ConcurrentHashMap 依然不能代替 Hashtable。例如,在强一致的场景中 ConcurrentHashMap 就不适用,原因是 ConcurrentHashMap 中的 get、size 等方法没有用到锁,ConcurrentHashMap 是弱一致性的,因此有可能会导致某次读无法马上获取到写入的数据。
2、大数据量应用ConcurrentSkipListMap
ConcurrentHashMap在数据量比较大的时候,链表会转换为红黑树。红黑树在并发情况下,删除和插入过程中有个平衡的过程,会牵涉到大量节点,因此竞争锁资源的代价相对比较高。
而跳跃表的操作针对局部,需要锁住的节点少,因此在并发场景下的性能会更好一些。为什么基于跳跃表实现的非线程安全的 SkipListMap 呀?这是因为在非线程安全的 Map 容器中,基于红黑树实现的 TreeMap 在单线程中的性能表现得并不比跳跃表差。
因此就实现了在非线程安全的 Map 容器中,用 TreeMap 容器来存取大数据;在线程安全的 Map 容器中,用 SkipListMap 容器来存取大数据。
如果对数据有强一致要求,则需使用 Hashtable;在大部分场景通常都是弱一致性的情况下,使用 ConcurrentHashMap 即可;如果数据量在千万级别,且存在大量增删改操作,则可以考虑使用 ConcurrentSkipListMap。
List并发容器
Java 在并发编程中提供的线程安全数组,包括 Vector 和 CopyOnWriteArrayList。
1、数据强一致性使用Vector
Vector 也是基于 Synchronized 同步锁实现的线程安全,Synchronized 关键字几乎修饰了所有对外暴露的方法,所以在读远大于写的操作场景中,Vector 将会发生大量锁竞争,从而给系统带来性能开销。
2、读远大于写使用CopyOnWriteArrayList
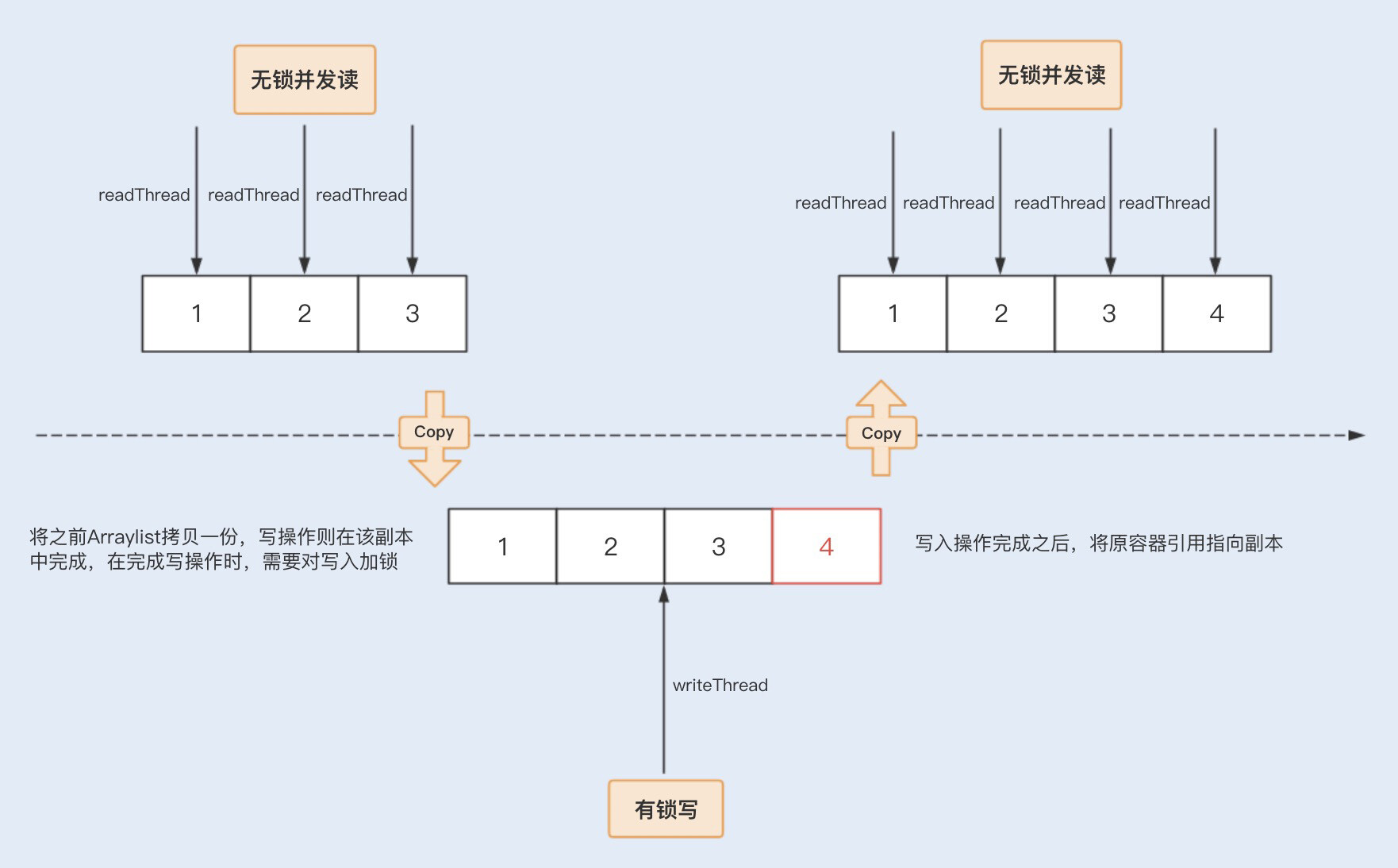
相比之下,CopyOnWriteArrayList 是 java.util.concurrent 包提供的方法,它实现了读操作无锁,写操作则通过操作底层数组的新副本来实现,是一种读写分离的并发策略。我们可以通过以下图示来了解下 CopyOnWriteArrayList 的具体实现原理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号