| 这个作业属于哪个课程 |
软件工程 |
| 这个作业要求在哪里 |
在这里 |
| 这个作业的目标 |
实现文章查重 |
PSP
| PSP |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
| Planning |
计划 |
20 |
30 |
| Estimate |
估计这个任务需要多少时间 |
10 |
13 |
| Development |
开发 |
1000 |
1200 |
| Analysis |
需求分析 (包括学习新技术) |
150 |
180 |
| Design Spec |
生成设计文档 |
20 |
60 |
| Design Review |
设计复审 |
30 |
30 |
| Coding Standard |
代码规范 (为目前的开发制定合适的规范) |
10 |
10 |
| Design |
具体设计 |
150 |
200 |
| Coding |
具体编码 |
500 |
700 |
| Code Review |
代码复审 |
10 |
20 |
| Test |
测试(自我测试,修改代码,提交修改) |
60 |
80 |
| Reporting |
报告 |
70 |
120 |
| Test Repor |
测试报告 |
20 |
30 |
| Size Measurement |
计算工作量 |
20 |
30 |
| Postmortem & Process Improvement Plan |
事后总结, 并提出过程改进计划 |
30 |
60 |
|
合计 |
2100 |
2763 |
# 获取文件内容
def get_file_contents(path):
str = ''
f = open(path, 'r', encoding='UTF-8')
line = f.readline()
while line:
str = str + line
line = f.readline()
# f.close()
return str
# 删除标点符号
def filter(str):
str = jieba.lcut(str)
result = []
for tags in str:
if (re.match(u"[a-zA-Z0-9\u4e00-\u9fa5]", tags)):
result.append(tags)
else:
pass
return result
# 去除停用词
def out_stopword(list):
stop = open('C:\\Users\\86139\\Desktop\\stopwords.txt','r+',encoding='utf-8')
stopwords = []
stopword = stop.readline()
while stopword != '':
stopwords.append(stopword)
stopword = stop.readline().strip('\n')
newlist = []
for key in list: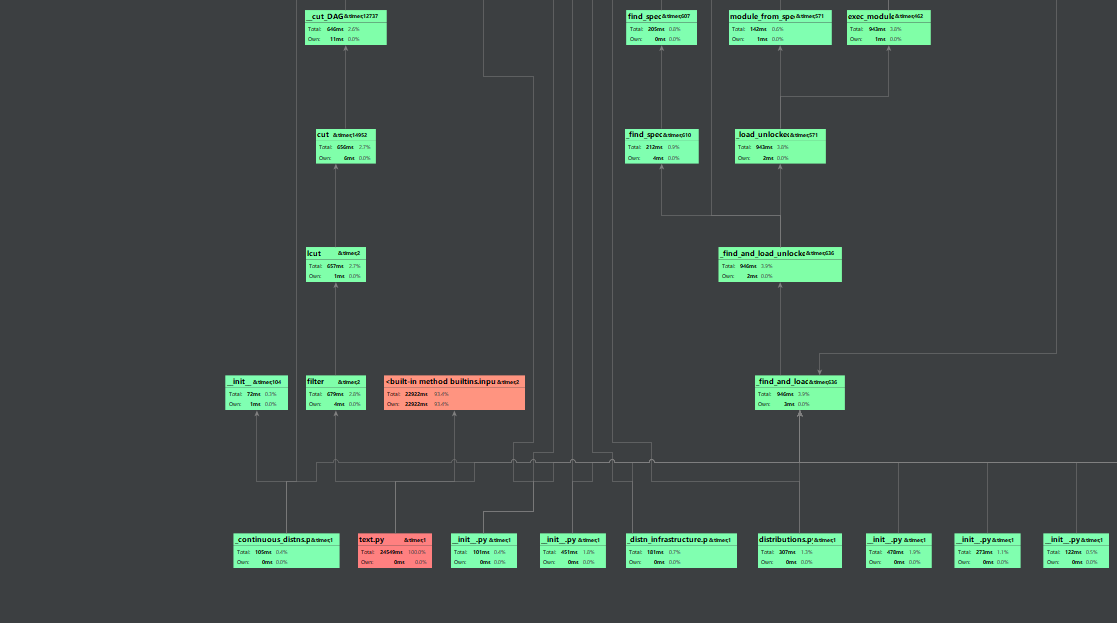
if not(key in stopwords):
newlist.append(key)
return newlist
# 利用余弦相似度来计算文章的相似度
def calc_similarity(text1,text2):
texts=[text1,text2]
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
similarity = gensim.similarities.Similarity('-Similarity-index', corpus, num_features=len(dictionary))
test_corpus_1 = dictionary.doc2bow(text1)
cosine_sim = similarity[test_corpus_1][1]
return cosine_sim
性能分析
![]()
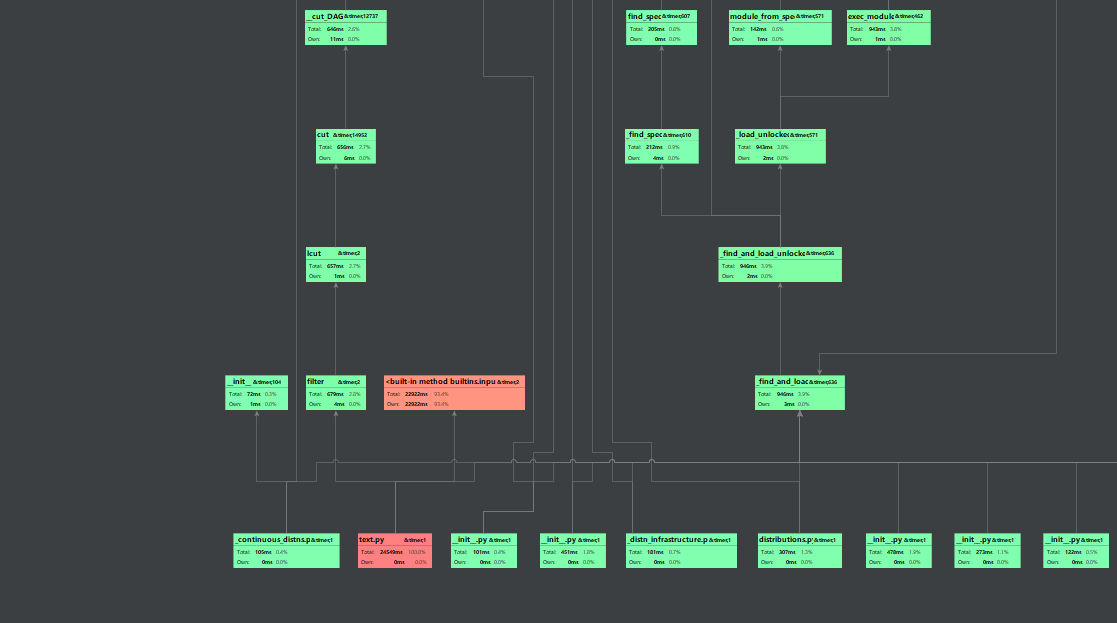
关系图
![]()
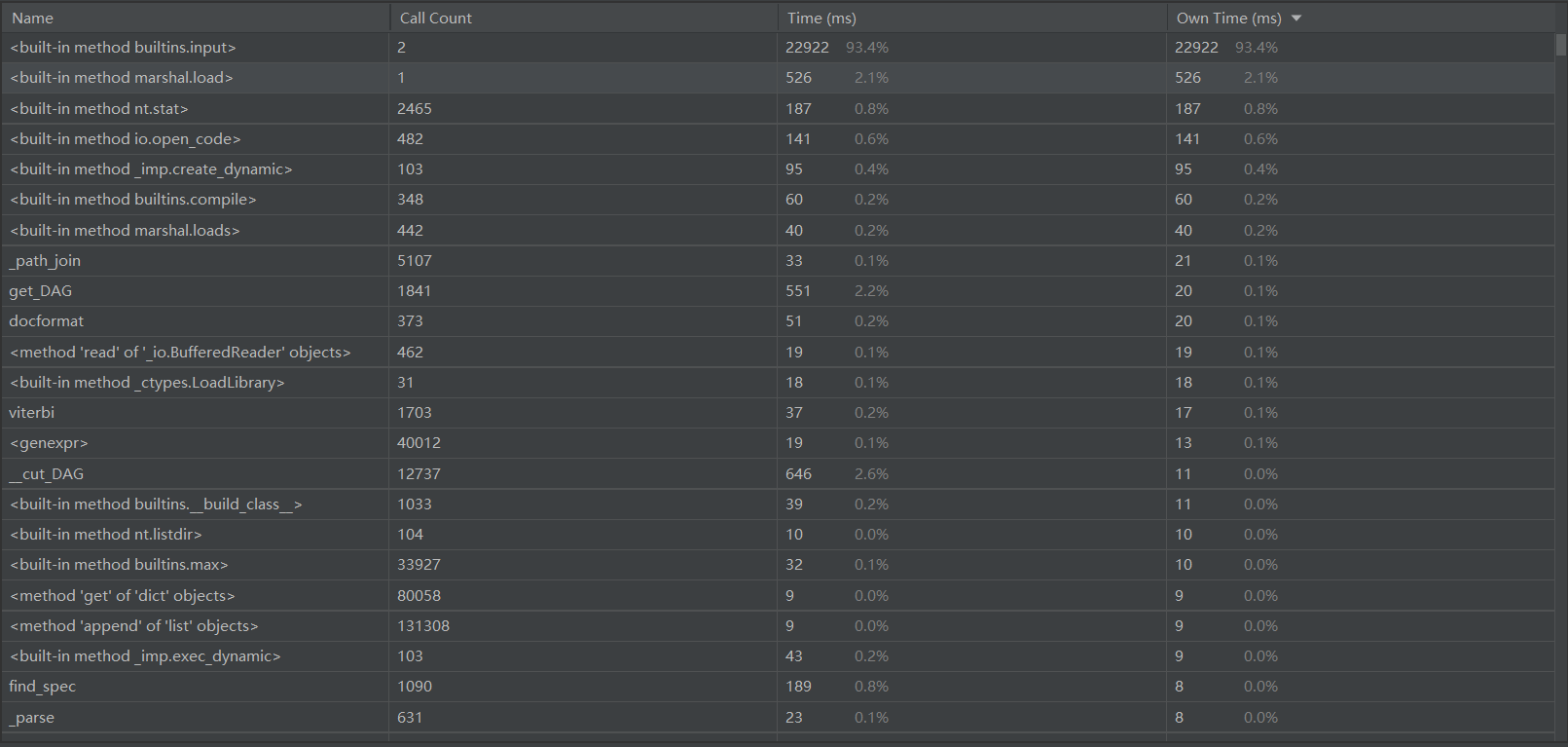
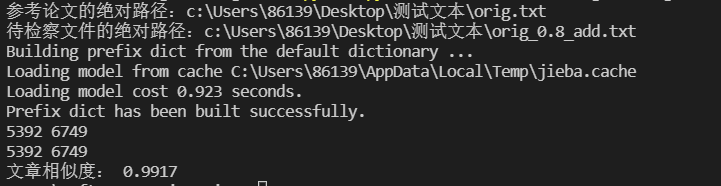
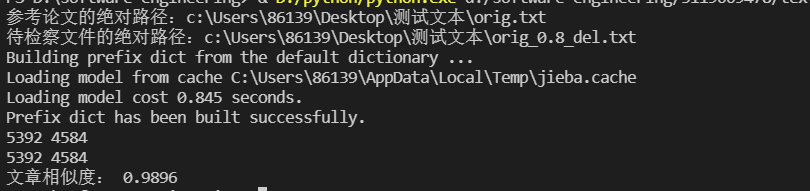
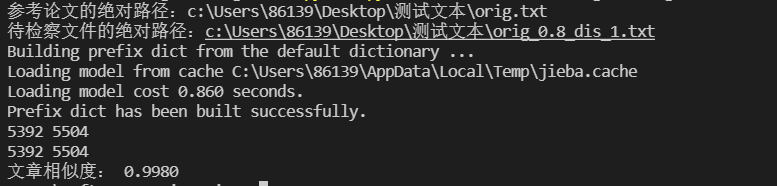
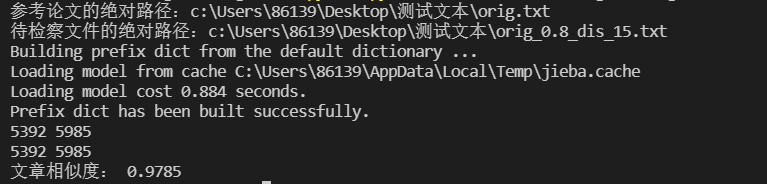
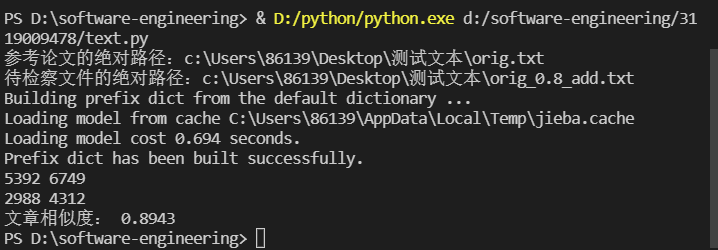
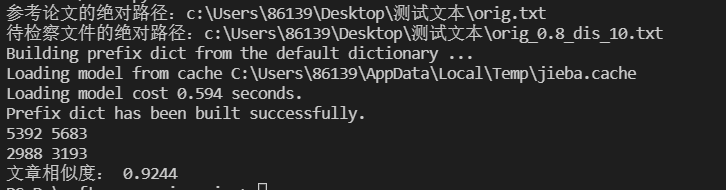
测试结果
去除停用词前
![]()
![]()
![]()
![]()
![]()
增加去除停用词后
![]()
![]()
![]()
![]()
![]()






 浙公网安备 33010602011771号
浙公网安备 33010602011771号