
关于hashmap的底层实现
注:以下内容并非基于最新的jdk版本
q1:hashmap为什么叫hashmap?
答:hashmap基于hashtable(不是hashtable类)实现。
q2:hashtable(不是hashtable类)又什么?
答:hashtable是一个数组加链表的数据结构,以下使用hashmap举例说明
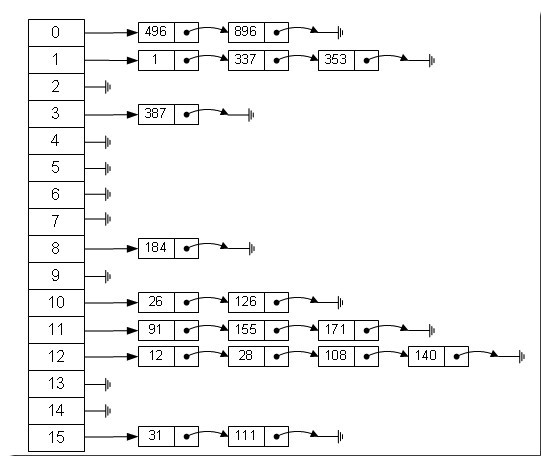
当我们new 一个hashmap()的时候,会生成一个length=16的数组,当然我们也可以使用hashmap()的有参构造方法初始化一个更合适的length,通过key的hashcode%length作为这个键值对node要放在哪个数组元素的链表中。那么问题又来了,为什么hashmap要用这种结构,而不是数组或者链表,那么我们就要考虑到两者的弊端,而hashtable综合了两者的优点,在数据同时需要增删和查询的时候hashtable无疑是更好的选择。
public V put(K key, V value) { if (key == null) //如果key是null的话 return putForNullKey(value); //获得hashcode int hash = hash(key.hashCode()); //得到索引 int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { //通过遍历链表查看是否有相同的key,map中不予许有相同的key Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { //这里就是替换老的值值得注意的是put()方法是有返回值的,返回相同key值得value V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } }</p><p> modCount++; //这里如果没有我们就建立一个新的节点,注意后来的要放在链表前面,它不像linkedlist是双向链表,这里是单向的 addEntry(hash, key, value, i); return null; }
这里的hashmap是key是可以为null的,这时候不会去求它的hashcode,而是直接放在了table0的位置。
private V putForNullKey(V value) { for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(0, null, value, 0); return null; }
这里不用多解释
q3:hushmap和hashtable的区别
两者在数据结构的实现上基本相同,区别在于hashtable线程安全,hashmap不安全,而且hashtable的key值是不支持null对象的。否则抛出nullpointerException
猜想:hashmap通过hashtable的方式很好的实现了数组和链表的结合,但是它是有取舍的,也就是它的综合性能好,我们可以通过我们的实际需求来决定我们是更快的增删还是更快查询

 浙公网安备 33010602011771号
浙公网安备 33010602011771号