
Hadoop权威指南 - 学习笔记
初识Hadoop、关于MapReduce
Hadoop宏观介绍
相对于其他系统的优势
- 关系型数据库管理系统
为什么不能用配有大量硬盘的数据库进行大规模分析?为什么需要Hadoop?
因为计算机硬盘的发展趋势是:寻址时间的提升远远不如传输速率的提升,如果访问包含大量地址的数据,读取就会消耗很多时间,如果使用Hadoop,更好的利用传输速率,读取花费的时间远远小于传输的时间,提高分析效率。
Hadoop发展历史
- 起源于开源网络搜索引擎Apache Nutch,该项目开始于2002年,
- 2003年,谷歌提出GFS,发现可以解决他们在网页爬取和索引过程中产生的超大文件存储需求
- 2004年,Nutch开始做NDFS的开源实现,同年,谷歌发表论文介绍MapReduce系统
- 2005年初,Nutch的开发人员在Nutch上实现了一个MapReduce系统,到年中,所有算法移植完成,用MapReduce和NDFS运行
- 2006年,将NDFS和MapReduce移出Nutch形成一个Lucene的子项目,命名为Hadoop
MapReduce简介
使用Hadoop分析数据
MapReduce任务过程分为两个阶段,map阶段和reduce阶段,每个阶段都是以键值对作为输入输出,类型由程序员确定。
横向扩展
Hadoop Streaming
提供MapReduce API,允许使用非Java的其他语言写map和reduce函数。Hadoop Streaming使用Unix标准流作为Hadoop和应用程序之间的接口,所以使用任何编程语言通过标准输入输出来写MapReduce程序。
第3章 Hadoop分布式文件系统
HDFS的概念
数据块block
- 默认128M,比磁盘的块(512字节)大,最小化寻址开销,那么传输一个由多个块组成的文件的时间取决于传输速率
datanode、namenode
- namenode管理文件系统的命名空间,维护文件和目录,以两个文件的形式永久保存在本地磁盘上(命名空间镜像文件,编辑日志文件),保存文件与数据块的引用关系。datanode是文件系统的工作节点,根据需要存储并检索数据块(受namenode调度)。
- 备份组成文件系统元数据的文件
- 运行辅助namenode定期合并编辑日志与命名空间镜像(之后于主节点,难免有数据丢失)
块缓存
- 对于频繁访问的文件,以堆外缓存的形式存在,用户通过缓存池(cache pool)管理缓存权限和资源使用
联邦HDFS
- 2.x版本引入,允许系统通过添加namenode进行横向扩展,每个namenode管理文件系统命名空间的一部分,每个namenode维护一个命名空间卷(namespace volume),由空间的元数据和数据块池组成(block pool,多个块)
HDFS的高可用性
- 若namenode失效,必须启动一个拥有文件系统元数据副本的新namenode(1,将命名空间映像导入内存,2,重演编辑日志,3,接收到足够多的datanode的数据块报告并退出安全模式,对于一个大型集群,冷启动需要30分钟甚至更长)
- Hadoop2.x针对上述问题增加了对HDFS HA的支持。配置一对活动-备用(active-standby)namenode。活动节点失效,备用节点会接管它的任务,不会有任何中断,实现这一目标需要在架构上做以下更改
- 1,namenode之间通过高可用实现编辑日志的共享,备用namenode接管后,实现和活动namenode的状态同步
- 2,datanode需要向两个namenode发送数据块报告,因为数据块的映射信息存储在内存中而非磁盘
- 3,客户端使用特定的机制处理namenode失效的问题,对用户透明
- 4,辅助namenode的角色被备用namenode包含,备用namenode为活动namenode设置周期性检查点
- QJM:是一个专用的HDFS实现,为提供一个高可用的编辑日志而实现,每一次写入必须写入多个日志节点
- 故障转移控制器(failover controller):默认使用ZooKeeper来确保仅有一个活动namenode,每一个namenode运行一个轻量级故障转移控制器,监视宿主namenode是否失效(通过一个简单的心跳机制)。
- 也可以手动发起故障转移进行日常维护,称为平稳的故障转移gracefull failover
- 在非平稳故障转移下,无法确切知道失效namenode是否已停止工作,高可用实现做了优化,确保之前的namenode不会执行危害系统的操作
- QJM仅允许一个namenode向编辑日志写数据,但对于之前的活动namenode,扔有可能相应用户请求,设置一个SSH杀死namenode进程
- Hadoop2.x针对上述问题增加了对HDFS HA的支持。配置一对活动-备用(active-standby)namenode。活动节点失效,备用节点会接管它的任务,不会有任何中断,实现这一目标需要在架构上做以下更改
命令行接口
- fs.defaultFS,设置为hdfs:localhost/,用于设置hadoop的默认文件系统url,HDFS守护程序通过该属性确定HDFS namenode的主机和端口,默认端口8020
- dfs.replication,设为1,默认为3,不然会有副本不足的警告
文件系统的基本操作
- hadoop fs -copyFromLocal [-f] [-r|-R] <src> <dst>,往HDFS拷贝文件
- hadoop fs -put
- -f:表示如果文件不存在不会显示任何信息
- -r:递归删除,删除文件夹
- src可以有多个(多个时最后一个必须是目录,单个时可以重命名)
- 左斜杠右斜杠都表示根目录,*表示通配
- hadoop fs -copyToLocal <> <>,往本地拷贝文件
- hadoop fs -mkdir <>,新建文件夹
- hadoop fs -ls <>,list
Hadoop文件系统
hadoop有一个抽象的文件系统概念,HDFS只是其中一个实现,Java抽象类org.apache.hadoop.fs.FileSystem定义了hadoop中一个文件系统的客户端接口,该抽象类有几个具体实现:hadoop fs -ls file:///,列出本地根目录下所有文件,
- Local,URI方案:file ,Java实现:fs.LocalFileSystem
- HDFS,URI方案:hdfs,hdfs.DistributedFileSystem ......
接口
- http
- c语言
- NFS
- FUSE
Java接口
从hadoop URL读取数据
- 每个java虚拟机只能调用一个setURL...方法,所以如果其他程序的一些组件已经声明了就无法用这种方法读取数据了
- 参数
- 本地文件系统:file:/home/xxx
- hadoop文件系统:hdfs://localhost:9000/home/xxx
- www,file,hdfs表示通信协议,//后加主机名,
- 参考[https://blog.csdn.net/s646575997/article/details/51336943]
package ex3_HDFS;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.io.IOUtils;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
//从Hadoop URL读取数据
//通过URLStreamHander实例以标准输入输出方式显示Hadoop文件系统的文件
public class URLCat {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) throws Exception {
InputStream in = null;
try {
in = new URL(args[0]).openStream();
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
通过FileSystem API读取数据
- hadoop文件系统中通过Hadoop Path对象来代表文件(非java.io.File对象,它的语义与本地系统太紧密),可以将路径视为hadoop文件系统URI
- FileSystem是一个通用的文件系统API,所以首先要检索需要使用的文件系统实例,获取FileSystem实例有以下几个静态工厂方法:
//返回默认文件系统(core-site.xml中指定的,没有指定使用默认的本地文件系统)
public static FileSystem get(Configuration conf) throws IOException
//通过给定的URI和权限确定要使用的文件系统,如果URI中没有给定,使用默认文件系统
public static FileSystem get(URI uri, Configuration conf) throws IOException
//作为给定用户访问文件系统,对于安全至关重要(参见10.4)
public static FileSystem get(URI uri, Configuration conf, String user) throws IOException
//Configuartion对象风阿航了客户端或服务器的配置,通过设置配置文件读取路径实现(如etc/hadoop/core-site.xml)- 获取本地文件系统实例:
public static LocalFileSystem getLocal(Configurature conf) throws IOException- 有了FileSystem实例,就可以使用open()函数获取文件的输入流
public static FSDataInputStream open(Path f) throws IOException //缓冲区默认4KB
public abstract static FSDataInputStream open(Path f, int buffersize) throws IOException
package ex3_HDFS;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
//通过FileSystem API读取数据
//直接使用FileSystem以标准输出格式显示hadoop文件系统中的文件
public class FileSystemCat {
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);//通过uri够构建URI
// 对象,获得FileSystem对象
InputStream in = null;
try {
in = fs.open(new Path(uri)); //通过uri构建Path对象
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}- FSDataInputStream对象
实际上open()返回的是FSDataInputStream对象,不是标准的java.io对象,是继承了java.io.DataInputStream的一个特殊类,并支持随机访问,可以从流的任意位置读取数据。
FSDataOutputStream对象与FSDataInputStream对象类似,也有一个查询文件当前位置的方法getPos(),没有seek(),对于输出流定位没有什么意义
package org.apache.hadoop.fs
public clsss FSDataInputStrean extends DataInpuStream
implements Seekable, PositionedReadable {
//implementation elided
}
//Seekable接口支持在文件中找到指定位置,并提供一个当前位置相对于起始位置的偏移量getPos()
public interface Seekable {
void seek(long pos) throws IOException;//定位大于文件位置会抛出异常
long getPos() throws IOException;//与java.io.InputStream的skip()不同,seek可以移动到文件中任意一个绝对位置,skip只能相对于当前位置定位到另一个位置
}
//PositionedReadable接口,从指定偏移量处读取文件的一部分
public interface PositionedReadable {
public int read(long position, byte[] buffer, int offset, int length) throws IOException;//从文件指定position处,读取length长度字节数据到buffer的偏移量offset处,返回实际读取的字节数,需要检查这个值,有可能小于length
public void readFully(long position, byte[] buffer, int offset, int length) throws IOException;//将指定长度length的字节数读到buffer中,在文件末尾会引发EOFException
public void readFully(long position, byte[] buffer) throws IOException;
}
//所有这些方法会保留文件当前偏移量,并且是线程安全的(FSDataInputStream并不是为并发访问设计的,
//因此最好新建多个实例),它提供了在读取文件主体时,访问文件其他部分的便利方法
//seek()是一个相对开销高的操作,谨慎使用。建议用流数据来构建应用的访问模式比如MapReduce,而非执行大量的seek()
package ex3_HDFS;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.IOException;
import java.net.URI;
//使用seek()方法,将hadoop文件系统中的一个文件在标准输出上显示两次
public class FileSystemDoubleCat {
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
FSDataInputStream in = null;
try {
in = fs.open(new Path(uri)); //返回的是FSDataInputStream对象
IOUtils.copyBytes(in, System.out, 4096, false);
in.seek(0); //go back to the start of the file
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
写入数据
- FileSystem有一系列新建文件的方法,最简单的就是指定一个Path对象,然后返回一个输入流:
- 其他重载方法:指定是否强制覆盖文件,文件备份数量,写入文件所用缓冲区大小,文件块大小,文件权限
- create()方法自动创建不存在的父目录,如果不希望,使用exists()检查,另一种是使用FileContext控制是否创建父目录
public FSDataOutputStream create(Path f) throws IOExcepction
//重载方法Progressable用于回调接口,可以把写进datanode的进度通知个应用
package org.apache.hadoop.util;
public interface Porgressable {
public void progress();
}
//追加数据
//可以创建无边界文件并非所有的文件系统都支持追加操作
public FSDataOutputInstream append(Path f) throws IOException
package ex3_HDFS;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Progressable;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
public class FileCopyWithProgress {
public static void main(String[] args) throws IOException {
String localSrc = args[0];
String dst = args[1];
InputStream in = new BufferedInputStream(new FileInputStream(localSrc));
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(dst), conf);
OutputStream out = fs.create(new Path(dst), new Progressable() {
//每写一次打印一次
@Override
public void progress() { //匿名内部类,重写Progressable类progress方法
System.out.printf(".");
}
});
IOUtils.copyBytes(in, out, 4096, true);
}
}
创建目录
//一次性创建所有必要目录,返回true
public boolean mkdirs(Path f) throws IOException查询文件系统中文件状态
- 文件元数据:FileStatus
- FileStatus类封装了文件系统中文件和目录的元数据,包括文件长度、块大小、副本、修改时间、所有者、权限信息
- FileSystem的getFileStatus()方法获取文件或目录的FileStatus对象
- 列出文件元数据:FileSystem的listStatus()方法,(FileStatus返回一个文件或目录的FileStatus,listStatus列出Path中所有的FileStatus
- FileUtiil.stat2path2()将FileStatus对象数组转为Path对象数组
//传入参数为文件,返回长度为1的FileStatus数组,参数为目录时,返回0或多个FileStatus对象
//PathFilter可以限制匹配的文件和目录
//传入多个Path时,相当于依次调用listStatus
public FileStatus[] listStatus(Path f) throws IOException
public FileStatus[] listStatus(Path f, PathFilter filter) throws IOException
public FileStatus[] listStatus(Path[] files) throws IOException
public FileStatus[] listStatus(Path[] files, PathFilter filter) throws IOExceptionpackage ex3_HDFS;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
//显示hadoop文件系统中的一组路径的文件信息
public class ListStatus {
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);//获取FS对象
Path[] paths = new Path[args.length];
for (int i = 0; i < paths.length; i++) { //创建Path对象素组
paths[i] = new Path(args[i]);
}
FileStatus[] status = fs.listStatus(paths);//通过fs.listStatus()
// 方法获得FileStatus数组
Path[] listedPaths = FileUtil.stat2Paths(status);//再将FileStatus转为Path对象
for (Path p : listedPaths) {
System.out.println(p.toString());
}
}
}
- 文件模式:无需列出每个文件的目录来指定输入,使用通配(globbing),hadoop提供了两个通配FileSystem方法:
public FileStatus[] globStatus(Path pathPattern) throws IOException
public FileStatus[] globStatus(Path pathPattern, PathFilter filter) throws IOException通配符与unix bash shell相同
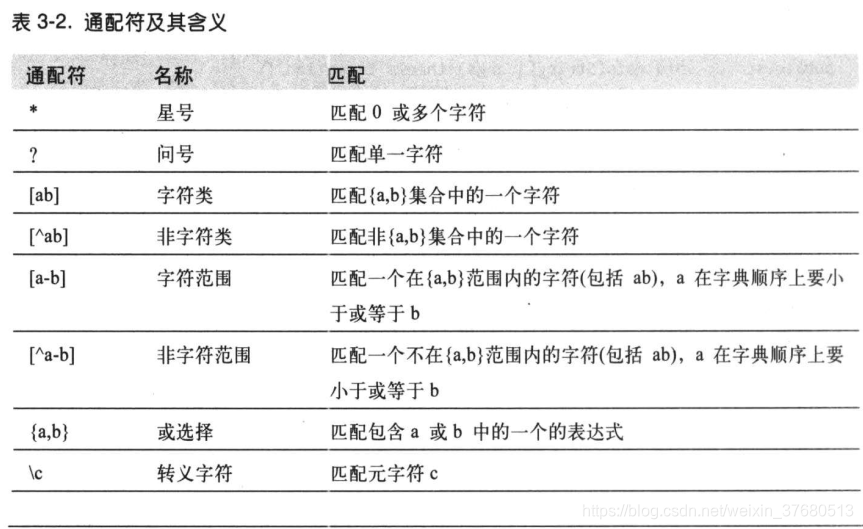

- PathFilter对象:通配符并不总能精确的描述想要的文件集,比如排除一个文件就不太可能。FileSystem中的listStatus和globStatus方法提供了可选了PathFilter对象,以编程方式控制通配符:
package org.apache.hadoop.fs
public interface PathFilter {
boolean accept(Path path);
} //与java.io.FileFilter一样,是Path对象而不是File对象
//例子,用于排除匹配正则表达式的路径
public class RegexExcludePathFilter implements PathFilter {
private final String regex;
public RegexExcludePathFilter(String regex) {
this.regex = regex;
}
public boolean accept(Path path) {
return !path.toString().matches(regex);
}
}- 删除数据:FileSystem的delete方法可以永久删除文件或目录
public boolean delete(Path f, boolean recursive) throws IOException
//recursive为true,非空目录及其内容才会删除,否则抛出IOException数据流
- 文件读取
- 文件写入
一致模型
描述文件读写的数据可见性,hdfs为性能牺牲了一些POSIX要求
- 新建文件,命名空间立即可见,写入文件的内容不保证立即可见,即使数据流已经刷新并存储
- hflush强行将所有缓存刷新到datanode中,不保证已经写到磁盘上,仅确保在内存中
- 为确保写入磁盘上,可以用hsync代替,类似于POSIX的fsync系统调用,hdfs关闭文件隐含调用hflush
- 不调用hflush或hsync,系统发生故障时可能会丢失数据块。hflush有很多额外的开销,hsync开销更大,权衡具体的应用,使用不同的刷新频率
通过distcp并行复制
- hadoop distcp file1 file2,复制文件
- hadoop distcp dir1 dir2,复制文件夹
- 目标文件夹不存在:新建dir2,将dir1下的内容复制到dir2,dir2/xxx
- 目标文件夹存在:直接将dir1复制到dir2下 ,dir2/dir1/xxx
- hadoop distcp 查看命令
- --overwrite强行覆盖原文件
- --update仅更新发生变化的文件(不确定操作效果先测试)
- --delete删除没在源路径中出现的文件或目录(必须有overwrite或update)
- -p保留文件状态
- distcp是通过map作业进行的,保持HDFS集群均衡,-m控制map数量
第4章 关于yarn
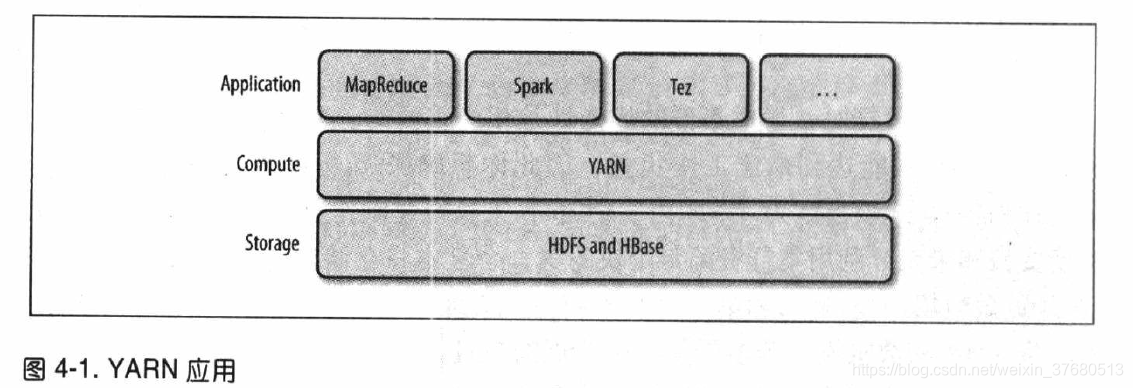
- Apache YARN(Yet Another Resource Negotiator)是hadoop集群资源管理系统。被引入hadoop2
- yarn提供请求和使用集群资源的API,但这些API很少直接用于用户代码。用户使用的是分布式计算框架提供的更高层API,这些API建立在yarn之上且向用户隐藏了资源管理细节,分布式计算框架作为yarn应用运行在计算层yarn和存储层HDFS和Hbase上。
- 还有一层应用是建立在所示框架之上的,Pig,Hive,Crunch,他们不和yarn直接打交道
剖析yarn应用运行机制
资源请求
- yarn资源请求很灵活,请求多个容器时可以指定每个容器的cpu和内存,也可以指定对容器的本地限制要求
- 通常会先向存储数据块三个副本的节点申请容器,都失败则申请集群中的任意节点
- yarn应用可以在运行中的任意时刻提出资源申请
- spark在集群上启动固定数量的执行器,MapReduce分两步走,开始时申请map任务容器,后期再启用reduce任务容器
应用生命期
构建yarn应用
yarn与mapreduce 1相比
- 可扩展性
- 可用性
- 利用率
- 多租户
yarn中的调度
调度选项
- FIFO调度器,先进先出队列
- 容量调度器,预留一定的资源,用一个独立的队列保证小作业一提交就可以启动,以整个集群的利用率为代价
- 公平调度器,不预留,当有其他作业来时,直接平分资源,后来的作业获得资源会有滞后(等之前的作业释放)
容量调度器配置
- 允许多个组织共享一个hadoop集群,每个组织可以分配到全部资源的一部分。每个组织被配置一个专门的队列,每个队列被配置使用一定的集群资源
- 弹性队列,队列中有多个作业,队列资源不够用,会从别的资源调度给这个队列,哪怕超过它的队列容量(可以配置最大容量)
- yarn.scheduler.capacity.<queue-path>.user-limit-factor设置为大于1(默认值)那么作业可以使用超过其队列的资源
- 配置:capacity-site.xml,yarn.scheduler.root.queues,设置根队列,下面可以设多个子队列
- .queues设置队列
- .capacity设置队列的容量
- .maximum-capacity设置最大容量
- 队列放置:mapreduce.job.queue.name指定要用的队列,不存在的话在递交时会出错。不指定则放在default队列中
公平调度器配置
旨在为所有的应用公平的分配资源,每启动一个新的作业,这个作业所在的队列(一个用户一个队列)就会分配一半的资源给这个作业
- 启用公平调度器:yarn-site.xml中,设置属性yarn.resourcemanager.scheduler.class为公平调度器的完全限定名org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler.默认使用容量调度器
- 配置:fair-scheduler.xml,可以通过yarn.scheduler.fair.allocation.file修改文件名,没有配置文件时使用默认的
- 队列的层次使用嵌套queue元素定义
- 设置权重时,要考虑默认队列和用户动态创建的队列,虽然没有分配,但仍有值为1的权重
- 每个队列可以有不同的策略,通过顶层defaultQueueSchedulingPolicy设置默认策略,省略默认使用公平,
- 队列放置
- 使用基于规则的系统确定应该放在哪个队列queuePlacementPolicy
- 默认:除非明确定义队列,否则必要时以用户名为队列名创建队列
- 不使用分配文件:将属性yarn.scheduler.fair.user-as-default-queue设为false应用就会被放入default队列而不是用户队列,将属性yarn.scheduler.fair.allow-undeclared-pools设为false用户便不能随意创建队列了
- 抢占
- 为了使作业从提交到执行所需的时间可预测,公平调度器支持抢占功能。抢占会降低集群效率,被终止的container需要重新执行
- 通过将yarn.scheduler.fari.preemptin设为true,可以全面启用抢占功能。
- 超时设置:最小共享超时(minimum share preemption timeout)公平共享超时(fair share preemption timeout),默认两个都不设置,所以为了抢占至少设置一个
- 分配文件顶层元素defaultMinSharePreemptionTimeout,单个指定minSharePreemptionTimeout
- 分配文件顶层元素defaultFairSharePreemptionTimeout,单个指定defaultFairSharePreemptionTimeout,defaultFairSharePreemptionThreshold和FairSharePreemptionThrehold可以修改超时阈值,默认0.5
延迟调度
所有的yarn调度器都试图以本地为重,当本地节点正在运行时,应当放宽本地性需求,在同一机架上分配一个容器。然而,通过实践发现,如果等待一小段时间,能够增加在所请求节点上分配到容器的机会
- 容量调度器配置延迟调度:yarn.scheduler.capacity.node-locality-delay,配置为正整数表示准备错过的调度机会的数量
- 公平调度器配置延迟调度:yarn.scheduler.fair.locality.threhold.node,表示集群规模的比例(0.5,表示在接受同一机架其他节点之前,将一直等待一半的调度机会),yarn.scheduler.fair.locality.threshold.rack表示接受其他机架等待的时间阈值
主导资源公平性(Dominant Resource Fariness, DRF)
不同应用占用的资源类型重点不同(有的占内存,有的占cpu),计算主导资源,主导资源多的分配容器多
- 默认不使用DRF
- 容量调度器配置:capacity-site.xml将yarn.scheduler.capacity.resource-calculator设为org.apache.hadoop.yarn.util.resource.DominantResourceCalculator
- 公平调度器配置:通过将配置文件中的顶层元素defaultQueueSchedulingPolicy设为drf即可
第5章 Hadoop的IO操作
数据完整性
Hadoop ChecksumFileSystem使用CRC-32计算校验和,HDFS用于校验和的是一个更有效的变体CRC-32C
HDFS的数据完整性
- dfs.bytes-per-checksum指定字节的数据计算校验和,默认512字节,CRC-32是4个字节,开销小于1%
- open方法读取文件之前,FileSystem对象的setVerifyChecksum(false)可以禁用校验和验证
- 可以用hadoop fs -checksum 检查一个文件的校验和
LocalFileSystem
hadoop的LocalFileSystem执行客户端的校验和验证,在写入filename文件时,文件系统会在包含每个文件块校验和的同一目录内新建.filename.crc隐藏文件,文件块的大小由file.bytes-per-checksum控制,默认512字节。文件块大小的元数据存储在.crc文件,所以当文件块的大小变化时,仍可以正确读回原文件
禁用校验和:
- 使用RowLocalFileSystem
- 在应用中实现全局校验和,将fs.file.impl设为org.apache.hadoop.fs.RowLocalFileSystem进而实现对文件URI的重新映射
- 针对一些读操作禁用:新建一个RowLocalFileSystem实例,FileSystem fs = new RowLocalFileSystem; fs.initialize(null, conf)
ChecksumFileSystem
LocalFileSystem通过ChecksumFileSystem来完成自己的任务,有了这个类向其他文件系统中添加校验和就很容易了,一般用法:
FileSystem rawFs = ... //底层文件系统称为源文件系统
FileSystem checksummedFs = new ChecksumFileSystem(rawFs);//把源文件系统添加校验和
//可以使用ChecksumFileSystem的实例checksummedFs的getRawFileSystem()获取它(源文件系统)
//其他方法
//getChecksumFile(),获取任意文件校验和路径如果读取文件时检测到错误,会调用字节的reportChecksumFailure()方法,默认为空方法,LocalFileSystem会将这个错误的文件及其校验和移到同一存储设备名为bad_files的边际文件夹中
压缩
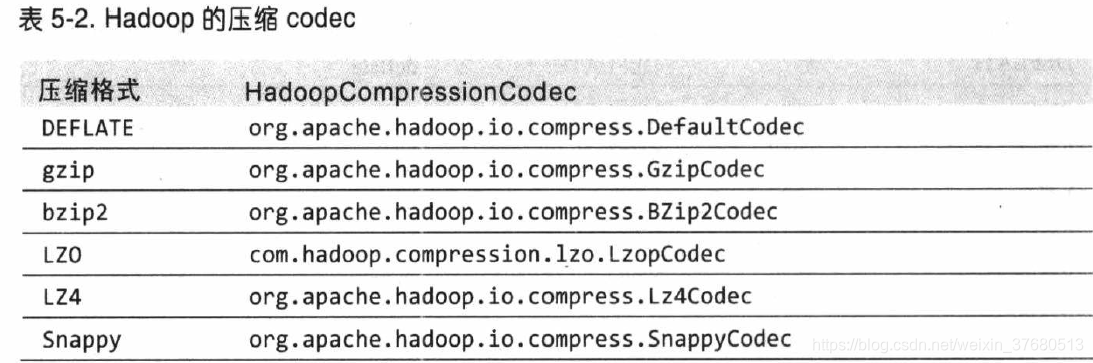
与hadoop结合使用的常见压缩算法:
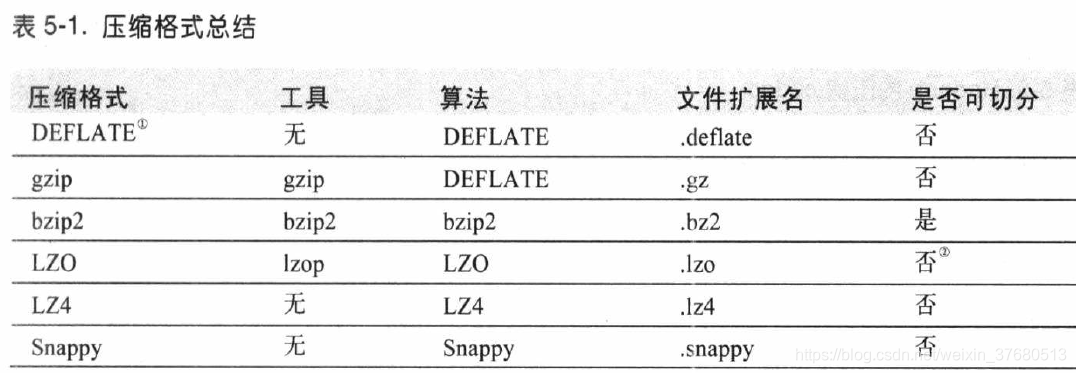
是否支持切分是指:是否可以搜索数据流的任意位置并进一步往下读数据。可切分压缩尤其适合MapReduce
codec
是压缩-解压缩算法的一种实现,在hadoop中,一个对CompressionCodec接口的实现代表一个codec
- 通过CompressionCodec对数据流进行压缩和解压缩
- 通过CompressionCodecFactory推断CompressionCodec
- 原生类库:为了提高性能
- CodecPool,如果使用原生代码库并且需要在应用中执行大量压缩解压缩操作,可以考虑CodecPool,它支持反复使用压缩解压缩,以分摊创建这些对象的开销
压缩和输入分片
在MapReduce中使用压缩
序列化
序列化是指将结构化对象转化为字节流以便在网络上传输或写进磁盘进行永久存储的过程,反序列化是将字节流转回结构化对象。
序列化用于分布式处理的两大领域,进程间通信,永久存储
基于文件的数据结构
第6章 MapReduce应用开发
第7章 MapReduce的工作机制
MapReduce作业运行机制
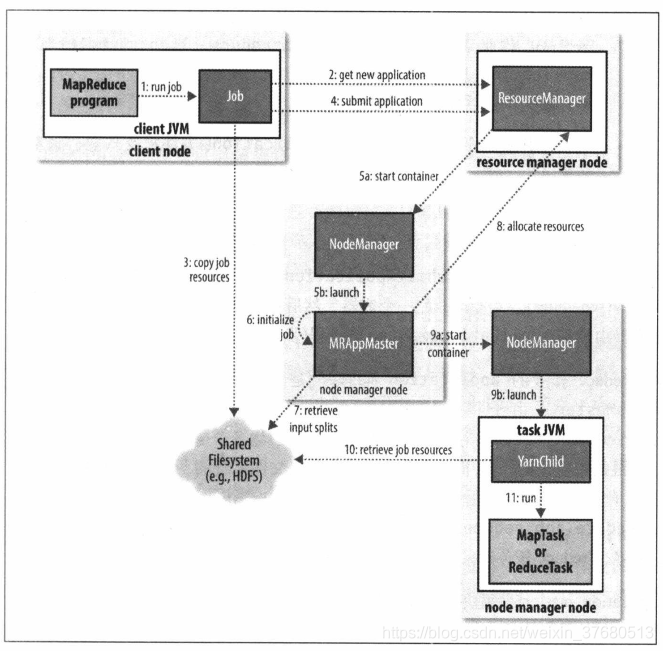
- 在最高层有5个独立的实体:
- 客户端:提交MapReduce作业
- yarn资源管理器,负责计算机资源的分配
- yarn节点管理器,负责启动和监视机器上的计算容器
- MapReduce的application master 负责协调运行MapReduce作业任务,它和MapReduce任务在容器中运行
- 分布式文件系统hdfs,与其他实体间共享作业文件
-
作业的提交:Job的sumbit()方法创建一个内部的JobSubmiter实例并调用submitJobInternal()方法,提交过程:
- 向资源 管理器请求新ID,用于MapReduce作业,步骤2
- 检查作业的输出说明,如没有指定输出目录或已存在,不提交,错误抛回MapReduce程序
- 计算作业的输入分片,如无法计算,没有输入目录,不提交,错误抛回MapReduce程序
- 将运行作业所需要的资源(jar,配置文件,计算所得分片)复制到一个以作业ID命名目录下的共享文件系统,步骤3
- 调用资源管理器的submitApplication()提交作业,步骤4
- 作业的初始化
- 资源管理器收到调用它的submitApplication消息后,将请求传递个yarn调度器,调度器分配一个容器,然后资源管理器在节点管理器的管理下在容器中启动application master进程,步骤5a,5b
- application master创建多个簿记对象以保持对作业进度的跟踪来进行作业的初始化,步骤6
- application master是一个java应用程序,主类是MRAppMaster
- 接受来自共享文件系统的、在客户端计算的输入分片,步骤7,对每个切片创建map任务对象及由mapreduce.job.reduces属性确定的多个reduce任务对象,分配任务ID
- application master必须决定如何运行构成MapReduce作业的各个任务,如果在新的容器中分配和运行任务的开销大于并行运行他们的开销时,就选择和自己在同一个JVM上运行,这样的作业称为uberized,或者作为uber任务运行
- 任务的分配
- 如果作业不适合作为uber任务运行,那么application master就会该作业中所有map任务和reduce任务向资源管理器请求容器,步骤8
- map任务的请求先发出,优先级高于reduce任务,因为所有的map任务必须在reduce的排序阶段启动前完成,直到有5%的map任务完成,为reduce任务的请求才会发出
- reduce任务能够在集群中任意位置运行,但是map任务有着本地化局限(所有的yarn调度器都试图以本地请求为重)
- 如果作业不适合作为uber任务运行,那么application master就会该作业中所有map任务和reduce任务向资源管理器请求容器,步骤8
- 任务的执行
- 一旦资源管理器的调度器为任务分配了一个节点上的容器,application master就通过与节点管理器通信来启动容器,步骤9a,9b
- 该任务由一个主类为YarnChild的java应用程序执行,运行任务前,首先将任务需要的资源本地化(配置文件,jar文件,所有来自分布式缓存的文件),最后运行map或reduce任务
- yarn在指定的JVM中运行,因此用户定义的map,reduce函数甚至是YarnChild中的任何缺陷都不会影响到节点管理器
- 一旦资源管理器的调度器为任务分配了一个节点上的容器,application master就通过与节点管理器通信来启动容器,步骤9a,9b
- Streaming运行特殊的map任务和reduce任务,目的是运行用户提供的可执行程序,并与之通信
- 进度和状态的更新
- 一个作业和它的每个任务都有一个状态(作业或任务的状态,map和reduce的进度,作业计数器的值,状态消息或描述)
- map或reduce任务运行时,每隔3秒钟,任务通过umbilical接口和父application master通信,报告自己的进度和状态,application master会形成一个作业的汇聚视图
- 作业期间,客户端每秒钟轮询一次application master,以接受最新状态
- 作业的完成
- application master收到最后一个任务完成的通知后,把作业的状态设置为成功,在Job轮询时,打印消息通知用户,从waitForCompletion返回。Job的统计信息和计数值输出到控制台
- 作业完成时,application master和任务容器清理其工作状态,OutputCommiter的commitJob()调用,作业信息由作业历史服务器存档
失败
-
任务运行失败
- 任务长时间没有收到进度会标记为失败,可以设置超时mapreduce.task.timeout,通常为10分钟
- 任务失败4次后application master 将不会重新执行,mapreduce.map.maxattempts,mapreducer.reduce.maxattempts
- 不希望失败几个任务整个作业都失败,设置百分比,mapreduce.map.failure.maxpercent,mapreduce.reduce.failure.maxpercent
- 任务尝试是可以被终止的,不会被记入失败运行次数
-
application master运行失败
- application master失败2次不再尝试,mapreduce.am.max-atttempts
- yarn在集群上对yarn application master最大尝试次数做了限制,yarn.resourcemanager.am.max-attempts,默认2,要增加MapReduce application master尝试次数,必须增加集群上的yarn设置
- 恢复过程,application master向资源管理器发送周期性心跳,资源管理器检测到该失败在新的容器里开始新的master
- MapReduce application maser 可以使用作业历史恢复失败的,yarn.app.mapreduce.am.jon.recover.enable,false关闭
-
节点管理器运行失败
- 如果10分钟内节点管理器没有向资源管理器发送心跳信息,yarn.resourcemanager.nm.liveness-monitor.expiry-interval-ms,资源管理器将从节点池中移出该节点,该节点上的所有任务都要进行恢复
- 节点管理器失败次数过高,可能会被拉黑,mapreduce.job.maxtaskfailures.per.tracker
-
资源管理器运行失败
- 运行一对资源管理器,关于运行中的应用程序的信息存储在一个高可用的状态存存储区中,备机到主机的切换由故障转移器处理,使用zookeeper的leader选举机制以确保同一时刻只有一个资源管理器
shuffle和排序
map输出传入reducer的过程称为shuffle
- map端
- 每一个map任务都有一个环形内存缓冲区,线程根据最终要传入的reducer把数据划分成相应的分区,按键进行内存中排序(如果有一个combiner函数,它就在排序后的输出上运行,使map输出结果跟紧凑),一旦缓存内容达到阈值,就会新建一个溢出文件写入磁盘(如果溢出文件超过3个,combiner会在输出文件写到磁盘之前再次运行)。
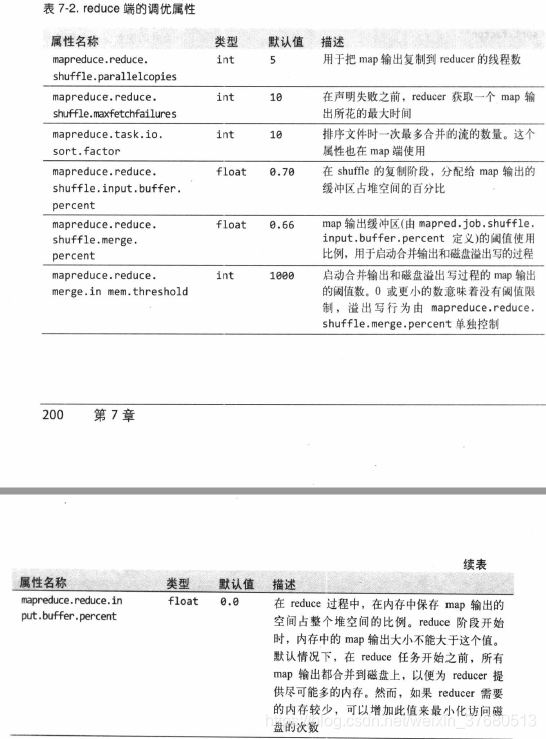
- reduce端
- 现在tasktracker需要为分区文件运行reduce任务,reduce任务需要集群上若干个map任务的输出作为其特殊的分区文件,每个map任务完成时,reduce任务就开始复制其输出,这是reduce的复制阶段(小的话复制到JVM内存,大的话复制到磁盘,超过某个阈值,合并后写到磁盘中,如果指定combiner,则在合并期间运行它降低写入磁盘的数据量)
- 随着磁盘上副本增多,后台线程会将他们合并为更大的、排好序的文件
- 复制完所有map输出,reduce任务进入合并阶段,合并map输出,维持其顺序排序,循环进行(并不是每次合并设置的合并因子,读取文件合并后再写入磁盘,减少文件写入磁盘的数据量,最后一趟总是直接合并到reduce)
- 在reduce阶段,对已排序输出中的每个键调用reduce函数,函数的输出直接写到文件系统,一般为hdfs
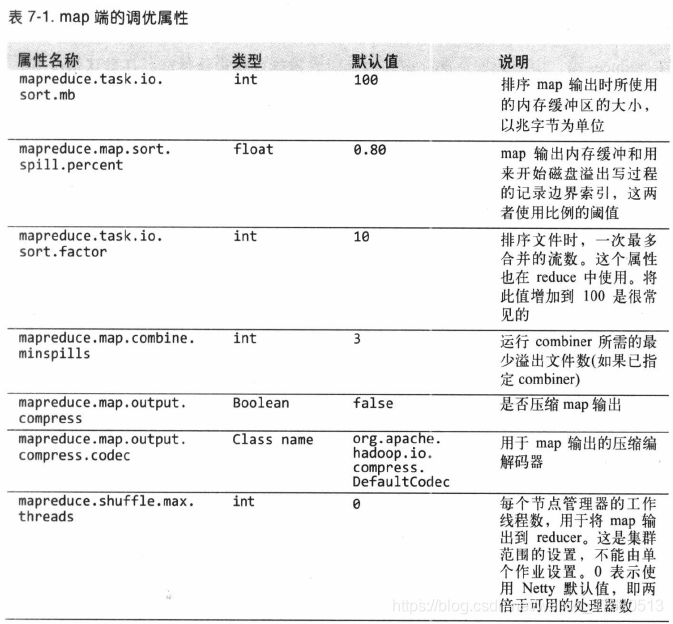
- 配置调优
- 调优shuffle过程提高mapreduce性能,总的原则是给shuffle尽可能多的内存
- 在map端,可以通过避免多次溢写磁盘来获得最佳性能
- 在reduce端,中间数据全部驻留内存就能获得最佳性能
任务的执行
- 任务执行环境,其属性可以从传递Mapper或reducer的所有方法的相关对象中获取

- 推测执行:对于一个作业中拖后腿的一些任务,如果比预期慢的时候,hadoop会尽量检测,并启用另外一个相同的任务作为备份,这就是所谓的推测执行。其中一个运行成功,另外一个都会被终止
- 推测执行是一种优化措施,默认启动,可以基于集群或某个作业单独为map或reduce启用会禁用该功能
- 推测执行是以降低集群效率为代价的,推测执行会减少整体的吞吐量。
- 关闭reduce任务推测执行有益,因为reduce任务都必须先取得所有的map输出,这可能大幅度增加集群上的网络传输
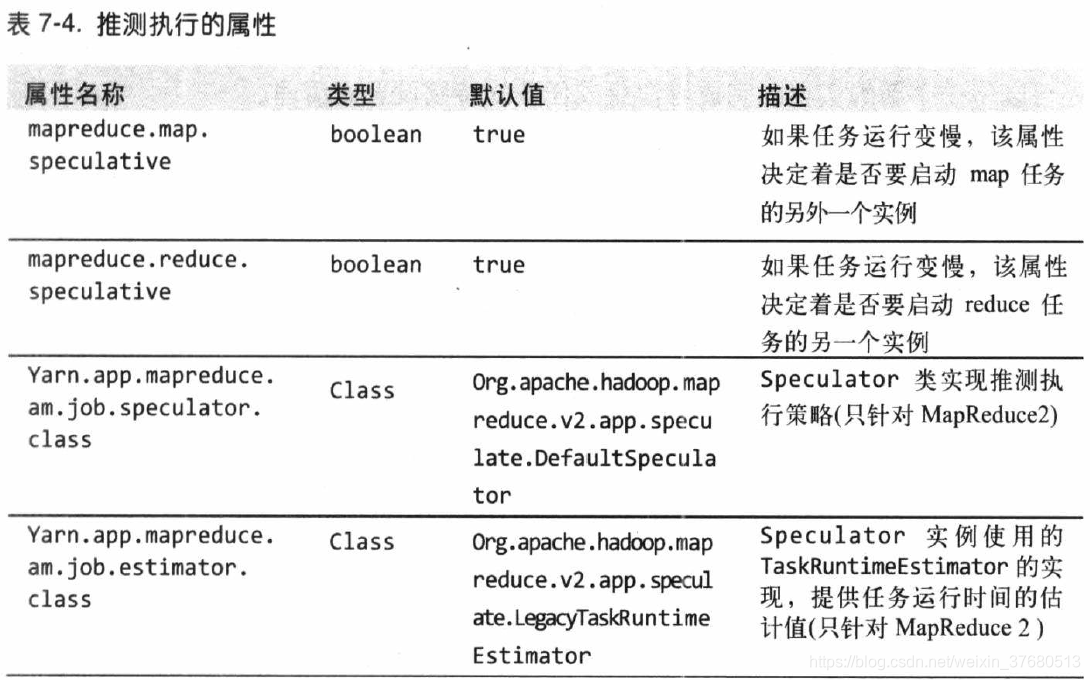
- 关于OutputCommitters:hadoop MapReduce使用一个提交协议来确保作业和任务都完全成功或失败,这个行为通过对作业使用OutputCommitter来实现
- 任务附属文件
第17章 关于Hive
Hive是一个构建在hadoop上的数据仓库框架,被设计用mapreduce操作hdfs数据
安装
- 解压 tar xzf
- ~/.bashrc,/etc/profile,添加HIVE_HOME、添加bin到PATH
- hive
- 在非交互模式,-f指定文件中的命令,hive -f script.q
- 较短的脚本,-e内嵌命令,hive -e 'SELECT * FROM table'
- 强制不显示信息,-S
示例
- 创建表
CREATE TABLE records (year STRING, temperature INT, quality INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
//row format HiveQL特有,声明数据文件的每一行是由\t分隔
//fields terminated- 向Hive输入数据
LOAD DATA LOCAL INPATH 'xxx/xxx.txt' //把本地文件放入仓库目录中,不加Local是在hdfs,复制还是移动??
OVERWRITE INTO TABLE records; //overwrite删掉表对应目录中已有的所有文件,省略则简单的加入此文件
//仓库目录由选项hive.metastore.warehouse.dir控制,默认/usr/hive/warehouse- 简单查询
SELECT year, MAX(temperature)
FROM records
WHERE temperature != 1 AND quiality IN (1, 2 ,3)
GROUP BY year;
//data
2000 10 1
2000 12 1
2001 1 1
2001 2 1运行Hive
配置hive
conf目录下配置hive-site.xml,设置每次运行hive使用的选项,该目录下还有hive-default.xml(默认值)
- 重新设置Hive查找配置文件hive-site.xml的目录
hive --config /xxx/xxx/hive-conf //指定目录而不是文件
//或者设置环境变量
HIVE_CONF_DIR- 单个会话设置
hive -hiveconf fs.defaultFS=hdfs://localhost \
-hiveconf mapreduce.framework.name=yarn \\
-hiveconf yarn.resourcemanager.address=localhost:8032
SET hive.enforce.bucketing=true; //使用SET更改设置
SET hive.enforce.bucketing //只有属性名,查询
SET-v //列出所有属性
- 设置优先级
- SET命令
- 命令行 -hiveconf选项
- hive-site.xml和hadoop本地配置文件(core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml)
- hive-default和hadoop默认文件(core-default.xml,...)
-
执行引擎 默认mapreduce
-
日志记录 ${java.io.tmpdir}${user.name}/hive.log
-
修改日志目录hive -hiveconf hive.log.dir='/tmp/${user.name}'
-
配置文件conf/hive-log4j.properites
-
hive -hiveconf hive.root.logger=DEBUG,console 在对话中配置
-
hive服务
- hive --service help 获取服务列表
- cli,hiveserve2,beeline,hwi,jar,metastore
- 不同服务提供不同的与hive通信方式
metastore,hive元数据的集中存放地
- 内嵌配置
- 本地配置
- 远程配置
hive与传统数据库相比
- 读时模式vs写时模式
- 传统数据库:写时模式,写的时候匹配模式
- hive:读时模式,对数据加载时不验证,读时验证
- 更新、事务、索引
- 紧凑索引、位图索引
- 其他SQL-on-hadoop技术
- impala
HiveQL
- 数据类型
- 操作与函数
- SHOW FUNCTION 获取函数列表
- DESCRIBE FUNCTION xxx 获取函数的使用说明
- 类型转换,小到大,文本也可以转double或decimal,强制转换 CAST
表
hive的表由存储的数据和描述数据形式的元数据组成,数据一般存在hdfs中,元数据存放在关系型数据库中,而不是hdfs
托管表和外部表
- 托管表,把数据移入它的仓库目录,一张表对应一个文件夹/user/hive/warehouse/table_name
- drop 删除元数据和数据
- 外部表,hive到仓库以外的位置访问数据,hive不管理的数据(也可以是hdfs),创建表时使用external关键字
- drop只删除元数据
- 一般是初始数据集当做外部表使用,可以用来导出数据供其他应用使用
分区和桶
- 分区,hive把表组织成分区,根据分区列对表进行粗略划分,使用分区加快数据分片的查询速度
//分区是在创建表的时候定义的
CREATE TABLE logs (ts BIGINT, line STRING)
PARTITIONED BY (dt STRING, country STRING);
//把数据加载到分区时要显式指定分区值
LOAD DATA LOCAL INPATH '/xxx/xxx/file1'
INTO TABLE logs
PARTITION (dt='2000-01-01', country='GB'); //文件系统级别分别会创建对应的子目录
//创建表之后可以使用ALTER TABLE 增加或移出分区
//显示分区
SHOW PARTITION logs- 桶,把表或分区组织成桶,1是获得更高的查询效率,桶为表添加了额外的结构,查询时可以用到这个(连接两个在相同列上划分桶的表,可以使用map端连接);2是采样更高效
//指定划分桶的列和个数
CREATE TABLE bucketed_users (id INT, name STRING)
CLUSTERED BY(id) INTO 4 BUCKETS; //物理上每个桶就是一个文件
//排序桶,进一步提升map端连接效率
CREATE TABLE bucketed_users (id INT, name STRING)
CLUSTERED BY(id) SORTED BY (id ASC) INTO 4 BUCKETS;
//向分桶后的表中插入数据需要设置hive.enforce.bucketing为true
INSERT OVERWRITE TABLE bucketed_users
SELECT * FROM users;
//TABLESAMPLE对表进行取样
SELECT * FROM bucketed_users
TABLESAMPLE(BUCKET 1 OUT OF 4 ON id); //返回1/4的桶
SELECT * FROM bucketed_users
TABLESAMPLE(BUCKET 1 OUT OF 2 ON id); //返回一半的桶存储格式
- 默认存储模式:分割的文本
- 二进制存储格式:顺序文件,Avro数据文件,Parquet文件,RCFile,ORCFile
- 使用定制的SerDe:RegexSerDe
- 存储句柄
导入数据
- INSERT语句,使用PARTITION()指明分区,可以在SELECT中使用分区值动态指明分区
- 多表插入,FROM source 可以放在INSERT前面,之后可以写多个INSERT语句,使用一个源表
- CREATE TABLE...AS SELECT...,原子性的,查询失败不会创建新表
表的修改
- 重命名,添加列....
表的丢弃
- DROP TABLE table 删除元数据和数据
- TRUNCATE TABLE table 删除数据,保留元数据(表结构),类似方法:CREATE TABLE table LIKE existing_table
查询数据
- 排序和聚集
- MapReduce脚本,TRANSFORM,MAP,REDUCE可以在hive中调用外部脚本或程序,运行之前使用ADD注册脚本,通过这一操作,hadoop把脚本传到hadoop集群上
- 连接
- 内连接,查询前使用EXPLAIN,查看使用了多少MapReduce作业,EXPLAIN EXTENDED更详细的信息
- 外连接,左外连接,右外连接
- 半连接
- map连接,表很小可以放入每个mapper的内存,map连接可以充分利用分桶的表,需要启动优化选项:SET hive.optimize.bucketmapjoin=true
- 子查询,只允许子查询出现在select的from语句中,或where子句的in或exists中,不支持相关子查询
- 视图,create view as select...,视图是select语句定义的虚表,创建视图时并不物化存储到磁盘,视图只读
用户定义函数
必须用java写,hive本身也是用java写的,对于其他语言,可以使用select transform查询,流经用户的脚本
- UDF:作用于单个数据行,产生一个输出数据行
- UDAF:多个输入数据行,产生一个输出数据行
- UDTF:作用于一个数据行,产生多个输出数据行(一个表)
- 写UDF
- 必须是org.apache.hadoop.hive.ql.exec.UDF的子类
- 至少实现了evaluate方法
- 打成jar包 create function fname as '类路径及名' using jar ‘jarpath’,删除drop function fname
- add jar create temporary function fname as ‘类路径及名’设置临时函数,最好在主目录中建立.hiverc文件,以及包含这些UDF的命令,这个文件会在每个hive会话开始时自动运行
- 写UDAF,比普通的UDF难写,此处省略步骤
第19章 关于Spark
第20章 关于Hbase
Hbase基础
Hbase是一个在HDFS上开发的面向列的分布式数据库,如果需要实时的随机访问超大规模数据集,就可以使用Hbase这一Hadoop应用。可以简单的增加节点来扩展
概念
- Hbase表
- 列族,列族的前缀:列族修饰符,info:format,info:geo,列族的前缀必须预先给出,列族成员可以随时按需加入
- 单元格有版本
- 行是排序的
- 区域:Hbase自动把水平划分成区域(超过设定阈值)
- 加锁:对行访问都是原子的,使得枷锁模型保持简单
- 实现
- 一个master主控机协调管理一个或多个regionserver从属机,负载启动一个全新的安装,把区域分配给注册的regionserver,活肤regionsrver故障,
- 依赖于zookeeper
- 从属节点在conf/regionservers文件中
- 使用SSH机制运行远程命令
- 站点配置在conf/hbase-site.xml,hbase-env.sh文件中
- 通过hadoop文件系统API存储数据
- Hbase保留名为hbase:meta的特殊目录表,维护这当前集群上所有区域的列表,区域名作为键
- 区域名:【表名, 起始行, 创建的时间戳.MD5哈希值.】
安装
- tar xzf xxx
- 正确配置JAVA_HOME
- 添加HBASE_HOME,添加HABSE_HOME/bin到PATH
- hbase获取选项列表
- 测试驱动start-hbase.sh,关闭hbase实例,stop-hbase.sh
- hbase-site.xml,hbase.tmp.dir配置存储位置,默认 ${java.io.tmpdir}/hbase-${user.name}
- 启动hbase shell,管理hbase实例
create 'test', 'data' //新建一个test表,有一个data列族,列族属性为默认值
list //列出空间里所有的表
put 'test', 'row1', 'data:1', 'value1' //添加数据
put 'test', 'row2', 'data:2', 'value2'
put 'test', 'row3', 'data:3', 'value3'
get 'test', 'row1' //获取row1
scan 'test' //列出整个表
disable 'test' //把表设为离线
drop 'table'
enable 'test' //重新设为在线客户端
- java
- MapReduce
- REST和Thrift
创建在线查询应用
模式设计
- 在shell环境中,创建表
create 'stations', {NAME => 'info'}
create 'observation', {NAME => 'data'}
//只对最新数据感兴趣,把version改为1,默认3加载数据
在线查询
Hbase与RDBMS比较
- Hbase是一个分布式的、面向列的存储系统,通过在HDFS上提供随机读写来解决hadoop不能解决的问题
第21章 关于ZooKeeper
ZooKeeper是hadoop的分布式协调服务
安装和运行
- 解压 tar xzf xxx
- 添加ZOOKEEPER_HOME,添加bin目录到PATH
- conf目录下配置zoo.cfg
指定基本时间单元
tickTime=2000
指定存储数据的本地文件系统位置
dataDir=/user/xxx
指定连接客户端监听的端口
clientPort=2181- 启动,zkServer.sh start
- 使用nc发送ruok命令,echo ruok | nc localhost 2181

示例
zookeeper服务
本文来自博客园,作者:Bingmous,转载请注明原文链接:https://www.cnblogs.com/bingmous/p/15643729.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号