十月十二日
本地excel/csv文件-->hive-->mysql
前提:Hadoop集群、hive配置完成
1、在node01开启hadoop集群 : start-dfs.sh , start-yarn.sh
2、node01 : 开启 metastore
hive所在路径/hive/bin/hive --service metastore3、克隆node01-->node01(1),开启 hive
hive所在路径/hive/bin/hive4、将本地文件上传至虚拟机
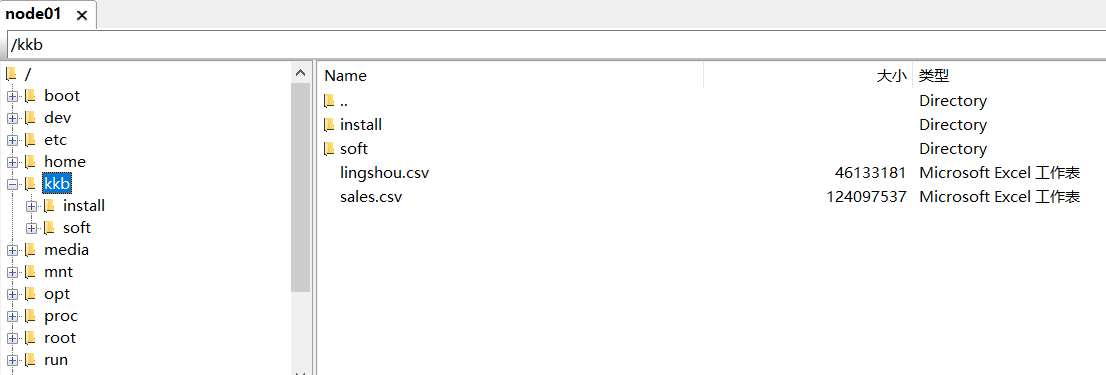
5、在hive中创建表
create table lingshou_csv (InvoiceNo String,
StockCode String,
Description String,
Quantity String,
InvoiceDate String,
UnitPrice String,
CustomerID String,
Country String)
ROW format delimited fields terminated by ',' STORED AS TEXTFILE;6、本地文件导入hive
load data local inpath '/kkb/install/hive/lingshou.csv' into table lingshou_csv;7、查看是否导入成功
select * from lingshou_csv limit 10;注意要用 limit 限制 ,否则数据过多等待时间太长
8、在mysql中的node01数据库(hive中对应mysql)中新建表
create table lingshou_csv (InvoiceNo VARCHAR(255),
StockCode VARCHAR(255),
Description VARCHAR(255),
Quantity VARCHAR(255),
InvoiceDate VARCHAR(255),
UnitPrice VARCHAR(255),
CustomerID VARCHAR(255),
Country VARCHAR(255));
ROW format delimited fields terminated by ',' STORED AS TEXTFILE;9、hive数据表导入mysql
bin/sqoop export \
--connect jdbc:mysql://node01:3306/lingshu_csv \
--username root \
--password 20194023 \
--table testtable \
--num-mappers 1 \
--export-dir /user/hive/warehouse/lingshu_csv \
--input-fields-terminated-by ","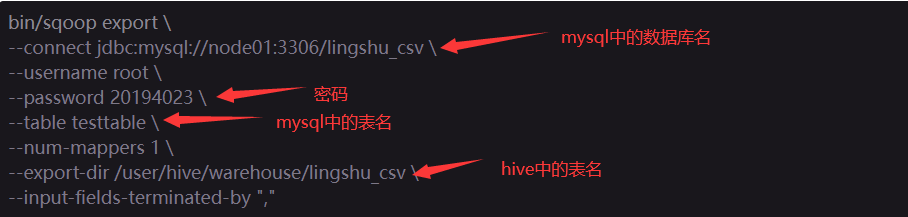
10、完成,可通过可视化工具查看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号