
Jacobian矩阵、Hessian矩阵和Newton's method
在寻找极大极小值的过程中,有一个经典的算法叫做Newton's method,在学习Newton's method的过程中,会引入两个矩阵,使得理解的难度增大,下面就对这个问题进行描述。
1, Jacobian矩阵矩阵
对于一个向量函数F:$R_{n}$ -> $R{m}$是一个从欧式n维到欧式m维空间的函数(好像有点难理解,请看下面),这个函数由m个实函数组成,每一个函数的输入自变量是n维的向量,即$(y_{1}(x_{1},\cdots,x_{n}), \cdots,y_{m}(x_{1},\cdots,x_{n}))^\mathrm{T}$,这些函数的偏导数(如果存在)将组成一个 m × n 的矩阵,称这个矩阵为 Jacobian矩阵
$J_{F}(x_{1},\cdots,x_{n}) = \left[ \begin{matrix}
\frac{∂y_{1}}{∂x_{1}}&\cdots&\frac{∂y_{1}}{∂x_{n}}\\
\vdots&\cdots&\vdots\\
\frac{∂y_{m}}{∂x_{1}}&\cdots&\frac{∂y_{m}}{∂x_{n}}
\end{matrix}\right]$
Jacobian矩阵的形式比较好理解;
首先我们已经有了 m × 1 的函数向量
$\left[ \begin{matrix}
y_{1}\\
\vdots\\
y_{m}
\end{matrix}\right]$
具体到每一个函数而言, 函数值y是标量, 对函数的每一个自变量 $x_{1},\cdots,x_{n}$求偏导,并将求偏导的结果横向放成一排,因为有 m 个函数,一共有 m 排:
$\left[ \begin{matrix}
\frac{∂y_{1}}{∂x_{1}}&\cdots&\frac{∂y_{1}}{∂x_{n}}\\
\vdots&\cdots&\vdots\\
\frac{∂y_{m}}{∂x_{1}}&\cdots&\frac{∂y_{m}}{∂x_{n}}
\end{matrix}\right]$
下面来讨论一下这个矩阵的几何意义: 首先看Jacobian的每一行:
每一行的节点值是函数在对应参数下的偏导,以向量的角度可以理解为梯度,梯度指向方向导数最大的方向,该最大值即为梯度向量的模
设 $\vec{u}$ 是梯度向量, $\vec{v} = x - p$,$\vec{t}$是 $\vec{v} $上的单位向量
现在已知梯度u,已知方向v,还定义了方向上的单位向量,根据方向导数的性质:
$\frac{∂f}{∂l} = \left\Vert u \right\Vert\left\Vert t \right\Vert cosθ$
再将单位向量延拓成v:
则$ <u, v> = \left\Vert u\right\Vert\left\Vert v\right\Vert cosθ = \frac{∂f}{∂l} \left\Vert v\right\Vert $
其中 $\frac{∂f}{∂l}$ 是方向导数,对应的几何意义就是切线的斜率k, $\left\Vert v \right\Vert$ 是梯度方向上的递增向量,对应 $\Delta x$,最后乘积的结果就是 $\Delta y$
通常,在点p的一个很小的范围内,我们认为函数y是线性的,可以用一个线性函数 y‘ 近似替代函数 y,而这个 y’ 的解析表达式就是:
$y' ≈ y_{p} + k\Delta x = y_{p} + <u, v>$
然后把 m 个函数都放在一起考虑, 用矩阵乘法代替 <u, v>可以得到:
$F(x) ≈ F(p) + J_{F}(p) (x - x_{p})$
2, Hessian矩阵
定义:Hessian矩阵是一个自变量为向量的实值函数的二阶偏导数组成的方块矩阵,此函数如下:
$f(x_{1}, x{2}, \cdots, x_{n})$
则Hessian矩阵为:
$H(f) = \left[\begin{matrix}
\frac{∂f^{2}}{∂x_{1}∂x_{1}}&\cdots&\frac{∂f^{2}}{∂x_{1}∂x_{n}}\\
\vdots&\cdots&\vdots\\
\frac{∂f^{2}}{∂x_{n}∂x_{1}}&\cdots&\frac{∂f^{2}}{∂x_{n}∂x_{n}}\\
\end{matrix}\right]$
那么Hessian矩阵是怎么来的呢?从定义出发:
首先 f 是一个自变量为向量的函数,函数值是一个标量(这个跟Jacobian矩阵的出发点就不一样)
对于标量函数 f, 对其求一阶偏导数,并将求导的结果按列排列
$\left[\begin{matrix}
\frac{∂f}{∂x_{1}}\\
\frac{∂f}{∂x_{2}}\\
\vdots\\
\frac{∂f}{∂x_{n}}\\
\end{matrix}\right]$
在一阶导数的基础上,对每个节点求二阶导数,并将求导的结果以列进行排列:
$\left[\begin{matrix}
\frac{∂f^{2}}{∂x_{1}∂x_{1}}&\cdots&\frac{∂f^{2}}{∂x_{1}∂x_{n}}\\
\vdots&\cdots&\vdots\\
\frac{∂f^{2}}{∂x_{n}∂x_{1}}&\cdots&\frac{∂f^{2}}{∂x_{n}∂x_{n}}\\
\end{matrix}\right]$
3, 泰勒级数
在讲解牛顿法之前,我们先来讲一下泰勒级数,考虑如下物理模型:
有一个物体,它以某种方式运动(现在还不知道到底是什么方式),现在能够观测到的是它在一段时间内的运动轨迹 s(t),并且有一把神器的尺子,可以测量指定点的任意阶导数(如果存在的话):
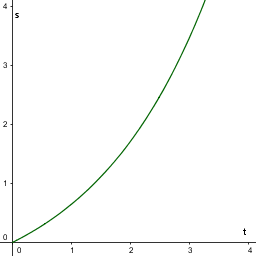
现在我们假设物体是匀速运动,v = const
并且 速度 v = 初始时刻的速度 = s'(t) (位移的导数是速度)
按照我们的假设,物体的运动轨迹应该就是这样:

虚线是物体实际的运动轨迹,实现是拟合出来的轨迹。可以看到,在 $t = t_{0}$附近,实际轨迹与拟合轨迹比较接近,一点时间$\Delta t$后,差距就出来了:物体实际运动到了位置C,我们拟合的位置还在B
问题在哪里?因为我们假定物体是匀速运动,并且假定0点之后的速度一直等于0点的速度,但是很明显,物体实际是加速运动。
现在我们来修改我们的假设模型,物体是加速运动,并假定加速度 a = const
并且 加速度 a = 初始时刻的加速度 = s‘’(t) (位移的二阶导数是加速度)
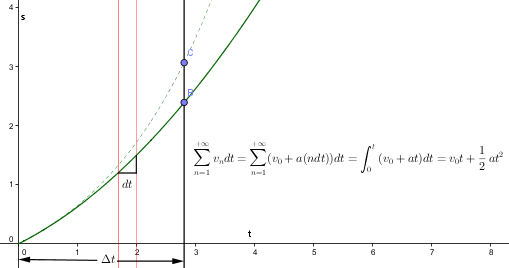
采用加速运动模型更能反映物体的实际运动状态,但还是达不到我们的要求
很显然,物体比我们拟合的运动还是要快一些,以我们目前的加速度还跟不上物体的速度
让我们再来修改一下假设模型,物体是加速运动,并且加速度不是恒定的,加速度的加速度 w 才是恒定的
并且 加速度的加速度 w = 初始时刻加速度的加速度 s'''(有点绕口令的感觉)

离我们的目标更进了一步,理论上,只要 n 阶导数存在,我们可以按照这种思想,不断加速加速,最终让B -> C
为了描述方便,我故意将初始状态设为 t = 0, s = 0, 其实我们也不一定非得局限于此,初始状态设为 $t = t_{0}, s = s_{0}$也是可以的
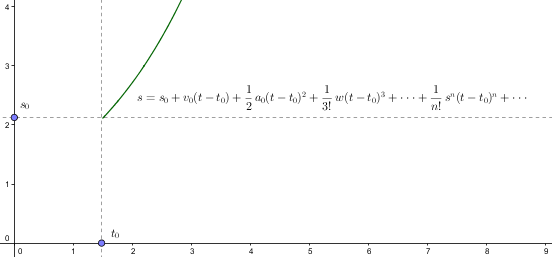
最后,我们来做一下变量替换,就成我们的泰勒级数了
$f(x) = f(x_{0}) + f'(x_{0})(x - x_{0}) + \frac{1}{2}f''(x_{0})(x - x_{0})^{2} + \frac{1}{3!}f'''(x_{0})(x-x_{0})^{3} + \cdots + \frac{1}{n!}f^{(n)}(x-x_{0})^{n} + \cdots $
泰勒级数向我们展示了一种思想:函数上的任一点的值,都可以用函数上某点的值$f(x_{0})$与第n(n >= 1)阶导数 = 常数 这个模型去逼近
4, Newton‘s method
但对于非线性优化问题,牛顿法提供了一种求解的办法. 假设任务是优化一个目标函数 f , 求函数 f 的极大极小问题。直接求解 f 的极小值比较困难,常将这种问题转换为求 f’ = 0的问题。
首先我们来看一下牛顿法怎么来找 f(x) = 0的点
为了求解 f(x) = 0,常将f(x)在 $x = x_{n}$处用泰勒级数展开:
$f(x) = f(x_{n}) + f'(x_{n})(x - x_{n}) + o(x - x_{n})^{2}$
这个公式的意思是:我知道函数上某一点 $f(x_{n})$的值是不为0的,我现在就用 $y = f(x_{n})$ + $f'(x)(x - x_{n}) $这个模型来逼近函数 f(x)(当然也可以用高阶导数,但是高阶导数徒增计算的困难外没有任何好处)

很明显,我用线性方程拟合出来的函数衰减比较快,线性函数与实际函数都是从P出发, 线性函数会提前到达 y = 0的位置,这个时候它会回过头取查看实际函数的位置,发现它还在点 S, 于是他又退回到S, 并用S处的导数重新拟合出新的线性函数,然后.....
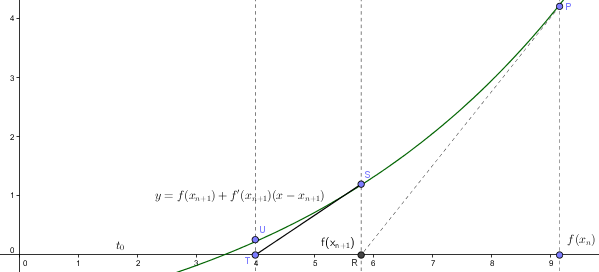
从图形的变化趋势可以看出,算法收敛到 f(x) = 0 的点
整个过程就好比:A、B从同一起点以同样的速度向0点赛跑,A的速度是恒定的,B的耐力不好,速度越跑越慢,于是A先到达了终点,A到达之后,觉得没意思,回过头去找B(穿越过去),并且参考B当前的速度,再次在同一起跑线采用相同的速度一起向终点进发,来回折腾了几次之后,A和B终于一起手牵手走向了终点(0点)。
归纳后的算法思想为:
$x_{n+1} := x_{n} - \frac{f(x_{n})}{f'(x_{n})}$
从几何上很容易理解,不需要过多的说明。
牛顿法求 f(x) = 0 一般是有效的,不过我们现在的问题是求 f(x)的极大值或极小值,即 f'(x) = 0 的位置,所以牛顿法正确的使用方式是:
$x_{n+1} := x_{n} - \frac{f'(x_{n})}{f''(x_{n})}$
上面我们讨论的都是单变量问题,如果输入参数 x 是一个向量,牛顿法就演变成:
$X_{n+1} := X_{n} - \frac{J_{f}(X_{n})}{H(X_{n})} = X_{n} - H^{-1}(X_{n})J_{f}(X_{n})$
$J_{f}(X_{n})$是我们前面介绍过的 Jacobian 矩阵,对应标量方程组的一阶导数
$H(X_{n})$ 是Hessian矩阵,对应标量方程的二阶导数
posted on 2018-05-28 15:53 bingjianing 阅读(1919) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号