

我们抛开参数嗅探的话题,回到了本系列的最初关注点中:为什么语句在应用程序中慢,但是在SSMS中快?到目前为止,都是在说存储过程的情况。而存储过程的问题通常是因为SET ARITHABORT的不同设置项的原因。如果你的应用不使用存储过程,而是通过中间层提交客户端的查询,那么也有几个原因可能让你的查询因为不同的缓存条目从而使得在SSMS和应用程序中的运行有差异。
什么是动态SQL?
动态SQL是任意不属于存储过程(或其他类型模组)的SQL代码。包含:
- 使用EXEC()和sp_executesql执行的SQL语句。
- 直接从客户端发到服务器的SQL语句。
- 在SQLCLR中提交的SQL语句。
动态SQL来自于两种方式:非参数化和参数化。在非参数化SQL中,开发人员拼接参数到SQL字符串中。比如:
SELECT @sql = 'SELECT mycol FROM tbl WHERE keycol = ' + convert(varchar, @value)
EXEC(@sql)
或者在C#中:
cmd.CommandText = "SELECT mycol FROM tbl WHERE keycol = " + value.ToString();
非参数化SQL在某些情景下非常低效。可以参考我的文章:T-SQL动态查询(1)——简介 、T-SQL动态查询(2)——关键字查询、T-SQL动态查询(3)——静态SQL、T-SQL动态查询(4)——动态SQL
在参数化SQL中,你可以像存储过程那样传入参数,如:
EXEC sp_executesql N'SELECT mycol FROM dbo.tbl WHERE keycol = @value',
N'@value int', @value = @value
或者在C#中:
cmd.CommandText = "SELECT mycol FROM dbo.tbl WHERE keycol = @value";
cmd.Parameters.Add("@value", SqlDbType.Int);
cmd.Parameters["@value"].Value = value;
动态SQL的计划生成:
SQL Server编译动态SQL 的过程和存储过程类似。也就是说,如果批语句包含了多个查询,整个批并不整体编译,同时SQL Server也对批中的本地变量值不可知。在存储过程中,SQL Server嗅探参数值,然后使用这些值来产生查询计划。
相对地,对于只有一个语句的动态SQL,可以使用参数化来实现类似功能,SQL Server会替换语句中的参数,如:
SELECT * FROM Orders WHERE OrderID = 11000
如果你提交的是下面这种方式,那么编译后就得到了上面这个语句:
EXEC sp_executesql N'SELECT * FROM Orders WHERE
OrderID = @p1', N'@p1
int', @p1
= 11000
对于参数化,也有两种模式:简单和强制。对于简单参数化,SQL
Server仅参数化相当小的一部分简单查询。对于强制参数化,SQL Server会把所有参数用常量替换,这篇文章提到的情况除外:强制参数化(微软联机丛书) 默认模式是简单参数化,可以使用ALTER DATABASE命令对每个库进行修改。
强制参数化会对没有使用参数化的应用程序节省大量性能,但是也还是有少量情况下,即使是编码优秀的应用程序中都有 效。
动态SQL和计划缓存:
动态SQL的查询计划和存储过程类似,都会被放入计划缓存。正如存储过程一样,动态SQL的计划缓存会被某些原因冲刷掉,动态SQL中的独立语句可能被重编译。此外,对于同一个查询文本,也有可能因为不同的SET配置而出现多个计划。
但是,和存储过程相比,有两个特殊情况是动态SQL有,存储过程没有的:
查询文本作为哈希键:
当SQL Server从缓存中查找存储过程的查询计划时,使用的是存储过程名。但是对于动态SQL,由于没有名字,所以SQL Server会把查询文本算成一个哈希值(包括参数列表),然后在缓存中以哈希值来查找。但是注释会被过滤掉,但是空格不会被截断或收缩。同时区分大小写,即使数据库是大小写敏感。哈希值是按文本计算出来的,所有哪怕一丁点的文本不同(不如多一个空格)都会产生不同的缓存条目。
打开实际执行计划并运行下面语句:
USE Northwind
GO
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime',
'20000101'
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime',
'19980101'
EXEC sp_executesql N'select * from Orders where OrderDate > @orderdate',
N'@orderdate datetime',
'19980101'
执行计划如下图,你会发现前两个执行语句使用同一个查询计划:

而第三个查询使用聚集索引扫描。也就是说,第二次调用重用了第一次调用的查询计划,但是第三次调用时,SQL关键字为小写,计划缓存中不存在,所以创建了新的查询计划。如果想强制实现这种策略,可以使用下面语句:
USE Northwind
GO
DBCC FREEPROCCACHE
GO
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime',
'20000101'
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime',
'19980101'
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime',
'19980101'
这一次,三个查询计划都一样了。
默认架构的重要性:
另外一个在存储过程中表现不明显的,可以开启实际执行计划并运行下面语句:
USE Northwind
GO
DBCC FREEPROCCACHE
GO
CREATE SCHEMA Schema2
GO
CREATE USER User1 WITHOUT LOGIN
WITH DEFAULT_SCHEMA = dbo
CREATE USER User2 WITHOUT LOGIN
WITH DEFAULT_SCHEMA = Schema2
GRANT SELECT
ON Orders
TO User1,
User2
GRANT SHOWPLAN
TO User1,
User2
GO
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime',
'20000101'
GO
EXECUTE AS USER = 'User1'
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime',
'19980101'
REVERT
GO
EXECUTE AS USER = 'User2'
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime',
'19980101'
REVERT
GO
DROP USER User1
DROP USER User2
DROP SCHEMA Schema2
GO
执行计划如前面所示,前两个执行计划一样但是第三个不一样。这个脚本创建了两个数据库用户,并授权给他们运行查询。然后语句被执行了三次。第一次由默认架构(即dbo),然后使用两个新建的账号运行。
SQL Server在查找对象时,先查找其默认架构,如果找不到,就会从dbo架构上找。对于dbo和User1,查询是没有什么混淆的,因为dbo是Orders表的默认架构。但是对于User2就不同了。由于只有dbo.Orders表,如果后面才添加Schema2.Orders会怎么样?按规则,User2会获取Schema2.Orders表上的数据而不是dboOrders的数据。但是如果User2还使用User1和dbo所产生的缓存条目,情况就不一样了。所以,User2需要自己的缓存条目。如果Schema2.Orders添加之后,缓存条目是独立的,不影响其他用户。可以使用类似之前用到的脚本来查看:
SELECT qs.plan_handle, a.attrlist
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) est
CROSS APPLY (SELECT epa.attribute + '=' + convert(nvarchar(127), epa.value) + ' '
FROM sys.dm_exec_plan_attributes(qs.plan_handle) epa
WHERE epa.is_cache_key = 1
ORDER BY epa.attribute
FOR XML PATH('')) AS a(attrlist)
WHERE est.text LIKE '%WHERE OrderDate > @orderdate%'
AND est.text NOT LIKE '%sys.dm_exec_plan_attributes%'
这里有三个不同点:
- 没有db_id()的限定,因为这一列仅对存储过程通用。
- 由于没有存储过程名可以匹配,所以必须使用语句文本来搜索。
- 需要额外的条件去筛选sys.dm_exec_plan_attributes。
执行这个语句之后,可以看到attributes的内容大概如下:
[plain] view plain copy
1. date_first=7 date_format=1 dbid=6 objectid=158662399 set_options=251 user_id=5
2. date_first=7 date_format=1 dbid=6 objectid=158662399 set_options=251 user_id=1
首先看看objectid,这是用于标识两个独立的缓存条目。然后看下user_id,其实这里应该计划缓存对应的默认架构名会更加合适。dbo架构总是为1。而在Northwind库中,Schema2是5(具体值不是非常重要)。
然后在运行一下这个语句:
EXEC sp_executesql N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', '20000101'
然后再查询可以发现多了第三行数据:
[plain] view plain copy
1. date_first=7 date_format=1 dbid=6 objectid=549443125 set_options=251 user_id=-2
objectID已经变了,因为查询文本不一样。user_id现在为-2,意味着什么?仔细检查语句,可以发现显式增加了架构名,意味着这个语句现在是精确的,所有用户都可以使用这个缓存条目。而-2的含义是:没有混淆的对象引用这个查询。这也是为什么编程规范里面都建议明确定义架构名的其中一个意思。不管在程序端还是在存储过程中都应该作为最佳实践。
对于存储过程,命名解释总是从存储过程的所属方执行,而不是当前用户。所以由dbo拥有的存储过程,Orders只能使用dbo.Orders而不会使用其他架构。(存储过程内部调用动态SQL除外,这个只适合存储过程中直接执行SQL语句。)
在SSMS中运行应用程序查询:
当你理解了前面内容之后,在应对SSMS快,应用慢的情景下,还是有一些陷阱需要注意。对于存储过程,需要记住ARITHABORT和其他SET选项的问题。但是同样需要确保查询文本的相同,程序端运行语句的账号的默认架构问题。
大部分情况下,可以使用下面方式来处理:
EXECUTE AS USER = 'appuser'
go
-- 需要执行的SQL语句
go
REVERT
但是,如果这个账号访问的资源不在当前库中,就会报错。这个时候,可以使用EXECUTE AS LOGIN来替代,但是这个方案需要有服务器级别的权限。
由于获取SQL文本通常不容易,最好的方式就是使用跟踪来获取SQL语句,可以使用Profiler或者服务器端跟踪。如果SQL语句是非参数化的,就需要小心你复制的完整文本,然后在SSMS中执行。也就是说,不要清除或者添加一些前缀或者空格等。也不要乱换行,删除注释等。确保和应用程序执行的语句一模一样。可以通过sys.dm_exec_plan_attributes来检查。
另外一个方案是从sys.dm_exec_query_stats和sys.dm_exec_sql_text中获取,执行下面语句:
SELECT '<' + est.text + '>'
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) est
WHERE est.text LIKE '%能标识出语句特征的SQL代码%'
注意这个要运行在文本模式,默认是网格模式,SSMS会使用空格来替换换行符。其中尖括号只是为了作为分隔作用。
对于参数化SQL就容易的多。因为SQL语句被单括号包住。也就是说你可能在Profiler中看到:
EXEC sp_executesql N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', '20000101'
即使你按这种格式来执行也无所谓:
EXEC sp_executesql
N'SELECT * FROM Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime', '20000101'
但是注意,不要改动单括号内部的代码,这样会影响哈希值的计算。
处理动态SQL中的参数嗅探问题:
前面对存储过程中参数嗅探的方案,在动态SQL中也适用,但是也有一些注意事项:
自动参数化的影响:
检查操作符属性中的谓词可以发现这部分的现象,如执行这个语句:
SELECT * FROM Orders WHERE OrderID = 11000
Seek谓词如下:
[plain] view plain copy
1. Seek Keys[1]: Prefix: [Northwind].[dbo].[Orders].OrderID =
2. Scalar Operator(CONVERT_IMPLICIT(int,[@1],0))
[@1]揭示了语句被自动参数化(auto-parameterised)
有时候这种情况是由用户发起,如:
SELECT ... FROM dbo.Orders WHERE Status = 'Delayed'
在Northwind中的这个表不存在stauts列,更不存在Delayed这个值,只是演示需要,当SQL Server参数化这个查询时,由于产生查询计划的要求必须可以覆盖所有参数,所以优化器并不会使用status上的列。
没有任何绝对的方式关闭任何的模式的参数化功能,但是有一些技巧可以使用。如果数据库是简单参数化模式,参数化仅发生在非常简单的查询中,比如仅仅是单表查询。其中一个技巧是在语句中使用AND 1=1来停用简单参数化的发生。
如果数据库是强制参数化,那么有两个替代方案。可以在联机丛书中看到:强制参数化 哪些情景是不适用于参数化的。其中一个是使用OPTION(RECOMPILE),另外一个是添加一个变量:
DECLARE @x int
SELECT ... FROM dbo.Orders WHERE Status = 'Delayed' AND @x IS NULL
计划向导和计划冻结:
有时候你想通过增加某种提示来修改语句从而解决问题。对于存储过程,你可以修改并部署新存储过程来马上解决问题,但是对于应用程序内部产生的语句,这种可能性就低很多。因为会导致整个代码重新编译生成人后可能还要部署到所有用户机器上。还可能要涉及到整个软件生命周期(如测试等),如果应用程序是第三方软件,那么几乎不可能实现。
但是,SQL Server提供了针对这些方式的解决方案,即计划向导(plan guides)。有两种方式建立计划向导,常规方式和快捷方式(计划冻结)。常规方式从SQL 2005开始引入,计划冻结从SQL 2008引入。
下面是一个计划向导建立的例子,但是这个例子仅适合SQL 2008及后续版本:
USE Northwind
GO
DBCC FREEPROCCACHE
GO
EXEC sp_executesql N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime',
@orderdate = '19960101'
GO
EXEC sp_create_plan_guide @name = N'MyGuide',
@stmt = N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
@type = N'SQL',
@module_or_batch = NULL,
@params = N'@orderdate datetime',
@hints = N'OPTION (TABLE HINT (dbo.Orders , INDEX (OrderDate)))'
GO
EXEC sp_executesql N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime',
@orderdate = '19980101'
GO
EXEC sp_control_plan_guide N'DROP',
N'MyGuide'
在这个例子中,创建了一个计划,确保查询一定会用到OrderDate上的索引并且是索引查找。然后指定了向导的名称。然后指定了使用这个向导的语句。当你在SSMS中执行时,确保没有添加或丢失任何空格或者其他改变。其中@type参数定义了这个向导是针对动态SQL而不是存储过程。如果SELECT语句是一个大批处理中的一部分,需要在@module_or_batch中指定应用程序提交的那部分代码。如果@module_or_batch为NULL,那么@stmt被假设为整个批。@params是批的参数列表,必须与应用程序提交的字符精确匹配。
最后,@hints就是重点所在。在这个例子中,指定了查询要总使用OrderDate上的索引,不管@orderdate的嗅探值是什么。还有一个在SQL 2005中不可用的查询提示OPTION(TABLE HINT),这就是为什么这个脚本只能在SQL 2008+使用。
在这个脚本中,使用DBCC FREEPROCCACHE仅仅是为了清空缓存。另外,为了演示,我使用了一个引出不好的查询计划的参数,使其进行聚集索引扫描。一旦语句使用了这个向导,就可以直接起效。也就是说,语句的当前所有条目都被清出缓存。
在SQL 2008中,只要知道名字,可以使用sp_create_plan_guide指定参数的任意顺序,并且忽略字符串之前的N。但是在SQL
2005中就有限制,参数的顺序是有要求的,并且不能忽略N。
在这个例子中,我使用了计划向导强制使用索引,但是你也可以使用其他提示,包含USE PLAN提示指定使用特定的完整的查询计划。不过这个风险有点大。
也就是说当有两个查询计划,一个好,一个坏,由于参数嗅探的原因,并且没有合适的方式去掉不好的查询计划时,使用计划冻结更加好。相对于使用sp_create_plan_guide处理复杂的参数,还不如从缓存中提取提取plan handle然后直接填充到sp_create_plan_guide_from_handle。如下面例子:
USE Northwind
GO
DBCC FREEPROCCACHE
SET ARITHABORT ON
GO
EXEC sp_executesql N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime',
@orderdate = '19990101'
GO
DECLARE @plan_handle VARBINARY(64),
@rowc INT
SELECT @plan_handle = plan_handle
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) est
WHERE est.TEXT LIKE '%Orders WHERE OrderDate%'
AND est.TEXT NOT LIKE '%dm_exec_query_stats%'
SELECT @rowc = @@rowcount
IF @rowc = 1
EXEC sp_create_plan_guide_from_handle 'MyFrozenPlan',
@plan_handle
ELSE
RAISERROR (
'%d plans found in plan cache. Canno create plan guide',
16,
1,
@rowc
)
GO
-- Test it out!
SET ARITHABORT OFF
GO
EXEC sp_executesql N'SELECT * FROM dbo.Orders WHERE OrderDate > @orderdate',
N'@orderdate datetime',
@orderdate = '19960101'
GO
SET ARITHABORT ON
EXEC sp_control_plan_guide 'DROP',
'MyFrozenPlan'
示例中,首先清空缓存,然后把ARITHABORT开启。然后执行一个能使查询使用合适查询计划的参数。然后第二个批演示了如何使用sp_create_plan_guide_from_handle。首先查询sys.dm_exec_query_stats和sys.dm_exec_sql_text去查找批的条目。然后把@@rowcount值存入本地变量。这样做可以防止从缓存中获得多个匹配或不匹配项。如果得到了准确的匹配项,就可以调用sp_create_plan_guide_from_handle,并传入两个参数:计划向导的名字和plan handle。
下一部分就是检查这个向导,为了确保没有使用相同的缓存条目,改变了ARITHABORT的设置。如果开启执行计划运行这个脚本,可以看到下图的样子,第二个执行和第一个的执行计划一样,虽然指定参数会导致聚集索引扫描,所以我们可以知道,计划向导现在是不依赖于SET选项。
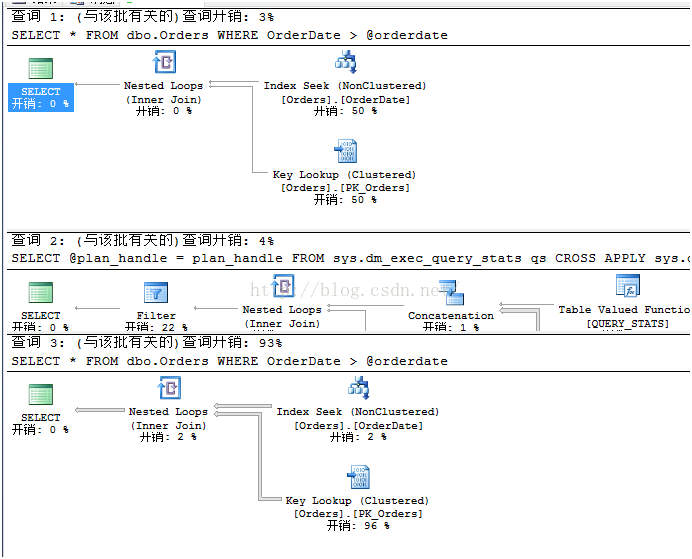
当你真正使用这种方式时,也许希望只有期待计划不存在于缓存中时才使用。对此需要对查询使用一些技巧,以便准确命中。
计划向导存储在sys.plan_guides中。所以一旦有了合适的向导,可以使用sp_create_plan_guide创建合适的内容到生产环境。
如果你有一个多语句批处理或者存储过程而你又只想对某个语句应用向导而不是整个批,可以使用sp_create_plan_guide_from_handle的第三个参数@statement_start_offset,这个参数值可以从sys.dm_exec_query_stats中获取。关于计划向导和计划冻结不是本系列的重点,读者可以从联机丛书中查阅更详细的信息:点击打开链接
总结:
本系列到此为止已经全部结束,文中介绍了为什么一个查询语句在SSMS和应用程序中会存在明显的性能差异,并且也知道了一些解决参数嗅探带来的行问题的方法。但是其实本系列并没有完全覆盖所有情景(当然也不可能),比如一些访问远程服务器的语句,和直接在服务器本地SSMS中执行查询,也都可能由于网络原因带来的性能差异。但是我(作者)认为,本系列应该已经覆盖了常见的问题。
扩展阅读及参考资料:
下面是一些关于统计信息、语句编译的资料,文中的内容很多来源于下面的资料:
- Statistics Used by the Query Optimizer in Microsoft SQL Server 2008
- Plan Caching in SQL Server 2008
- Troubleshooting Performance Problems in SQL Server 2008
- Forcing Query Plans

 浙公网安备 33010602011771号
浙公网安备 33010602011771号