
首先我们需要明白,参数嗅探本身不是问题,而是一个特性,避免SQL Server做出盲目的假设,从而产生次优查询计划。但是有些情况下,参数嗅探却会带来负面影响。通常有下面三种典型的情况:
- 查询使用的参数嗅探完全不合适。也就是说,查询计划对于这次执行是合适的,但是对于下一次执行就可能不合适。
- 应用程序中存在特定的调用模式,而且与其他大部分调用模式差异很大。通常这种调用是针对初次启动或者新一天的开始时调用。
- 一个或多个表上的索引结构不能很好地支持查询,但是又有某些次优的索引,导致优化过程中,优化器会无计划选择这些索引。
我们往往很难预先知道实际情况,所以才需要做仔细的分析。上一节已经讨论了需要获取一些什么信息,但是还有一个极其有帮助的内容没有提到:精通应用程序的运行模式。
由于参数嗅探的问题可能是多方面的,所以没有单一方法可以解决所谓情况。具体方案需要根据具体原因而定。下面演示几个参数嗅探的问题及解决方案,有些是真实环境的,有些是通用情况的。其中一些聚焦在分析层面,而其他聚焦在解决方案上面。
没有办法的办法:
在开始实际解决方案之前,先表明我(作者)的观点:在存储过程中添加SET ARITHABORT ON不能算是一个解决方案。虽然在使用的时候可能有效,但是这仅仅是因为你重建了一个新的存储过程并强制触发一个新的编译,然后下一次调用时嗅探当前设置的参数。SET ARITHABORT ON仅仅是一个安慰作用,甚至连好都说不上。因为问题可能又会重现。甚至不能帮助你避免在SSMS和应用程序中不同性能问题所带来的困惑,因为总体的计划缓存中缓存词目的ARITHABORT 还是为OFF.
所以,不要在存储过程中使用SET ARITHABORT ON,总的来说,我强烈建议不要在代码中使用任何在缓存键中存在的SET选项。
基于输入的最优索引:
先看看下面这个存储过程:
CREATE PROCEDURE List_orders_12 @custid nchar(5),
@fromdate datetime,
@todate datetime AS
SELECT *
FROM Orders
WHERE CustomerID = @custid
AND OrderDate BETWEEN @fromdate AND @todate
在Northwind库中,有两个索引,一个是基于CustomerID列,一个是基于OrderDate列。假设订单在客户之间变动很频繁。很多客户可能每年只有少数几个订单。但是某些客户却又很多。
在Northwind库中,最活跃的用户是SAVEA,有31个订单,而CENTC只有一个,那么运行下面语句:
use Northwind
go
EXEC List_orders_12 'SAVEA', '19970811', '19970811'
go
sp_recompile List_orders_12
go
EXEC List_orders_12 'CENTC', '19960101', '19961231'
注意,对于ASVEA,我们仅查询一天的订单,但是对于CENTC,我们查询一年的数据,你可能想到,这两个调用应该使用不同的索引,下面是实际执行计划:
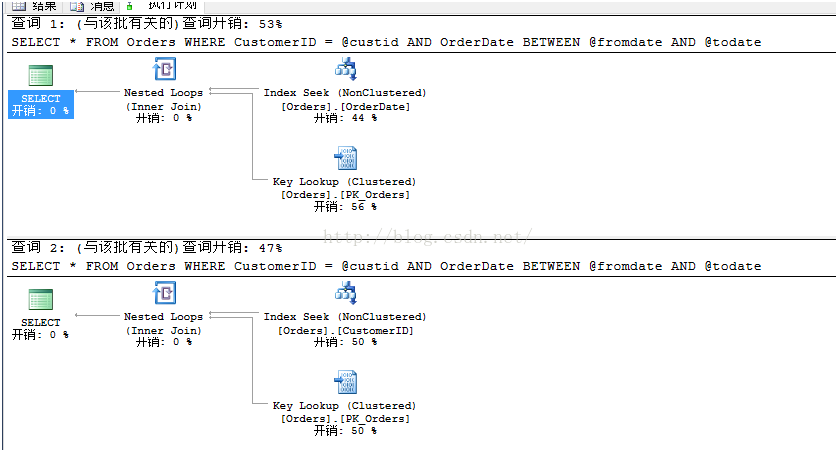
第一个查询中,SQL Server使用了OrderDate上的索引,因为它具有最高选择度。而第二个查询就不一样,因为这时候CustomerID具有最高选择度,所以SQL Server使用上面的索引。
其中一个解决这种问题的方案是使用RECOMPILE查询提示,每次调用时都触发重编译:
CREATE PROCEDURE List_orders_12 @custid nchar(5),
@fromdate datetime,
@todate datetime AS
SELECT *
FROM Orders
WHERE CustomerID = @custid
AND OrderDate BETWEEN @fromdate AND @todate
OPTION (RECOMPILE)
使用这种方式,SQL Server每次都会对这个“语句”进行重编译。除此之外,还可以让SQL Server重编译整个存储过程:
CREATE PROCEDURE List_orders_12 @custid nchar(5),
@fromdate datetime,
@todate datetime WITH RECOMPILE AS
对于这个存储过程,使用哪种方式都无所谓,因为它是单语句的。但是对于代码很长的存储过程,使用WITH RECOMPILE不是最好的方式,因为这样会引起整个存储过程重编译,增加重编译开销。另外关于WITH RECOMPILE的一个特性,就是计划不会存入缓存,但是使用OPTION
(RECOMPILE)就会存入计划缓存中。
在很多情况下,每次强制重编译一般不会出现问题,但是有些情况下就会有问题:
- 存储过程被调用的频率很高,重编译会明显影响系统性能。
- 查询非常复杂并且编译时间已经明显影响了响应时间。
更准确地说,当强制重编译的方式总能奏效时,那么意味着它并不是最佳解决方案。事实上,在这一节的例子里面,可能不是很典型的“在应用程序中慢,在SSMS中快”的情况。因为不同的使用模式会引起不同的性能问题。所以你应该继续看下去,说不定会发现案例中的情况正如你遇到的那样。
动态查询条件:
用户选择多个查询条件然后提交数据库是很常见的情况。比如可以选择查看特定日期、特定客户、特定产品等的订单,然后把条件组合成参数。这类情况通常在存储过程的WHERE子句中以下面方式实现:
WHERE (CustomerID = @custid OR @custid IS NULL)
AND (OrderDate = @orderdate OR @orderdate IS NULL)
...
正如你想象的,参数嗅探对这类存储过程没有好处。我(作者)不打算在这里浪费太多篇幅,因为:1)因为前面提到过,这种情况更多是应用程序的问题。2)我写了一系列独立的文章:T-SQL动态查询(1)——简介 、T-SQL动态查询(2)——关键字查询、T-SQL动态查询(3)——静态SQL、T-SQL动态查询(4)——动态SQL
评估索引:
在很久以前,我(作者)的一个客户联系我,说他们的一个系统中的函数出现了严重的性能问题。客户说同样的代码在其他站点运行良好,并且应用程序都没改动。(但是你知道,客户总是说这种理由)客户把问题代码隔离出来,然后其中一个语句类似下面的样子:
SELECT DISTINCT c.*
FROM Table_C c
JOIN Table_B b ON c.Col1 = b.Col2
JOIN Table_A a ON a.Col4 = b.Col1
WHERE a.Col1 = @p1
AND a.Col2 = @p2
AND a.Col3 = @p3
从应用程序中执行这段代码,大概花费了10~15分钟。但是在SSMS中执行,几乎瞬间完成。所以客户联系上我(作者)。
他们开了一个账号给我(作者)登录站点检查问题。发现这三个表都有点规模,每个表最少百万级数据。检查Table_A的索引之后,发现上面有7~8个索引,其中对这个查询有关的索引如下:
- 非聚集、不唯一索引Comb0_ix ,覆盖Col1,Col2,Col5,Col4 列。
- 非聚集、不唯一索引Col2_ix,覆盖Col2列。
- 非聚集、不唯一索引Col3_ix ,覆盖Col3列。
对比语句,可以发现没有任何一个索引可以覆盖WHERE条件中的所有列。
在SSMS以默认设置运行存储过程,优化器选择了Table_A上的第一个索引获取数据。然后把ARITHABORT设为OFF之后,发现使用了Col3_ix这个索引。然后我运行:
DBCC SHOW_STATISTICS (Table_A, Col3_ix)
输出结果类似下面:

只有17个唯一值,并且数据分布极其不平均。并且通过这个语句验证过:
SELECT Col3, COUNT(*) FROM Table_A GROUP BY Col3 ORDER BY Col3
然后重新研究慢查询的查询计划,检查优化器嗅探@p3的参数值是什么。然后发现是“APPLE”,一个不存在于表中的值。也就是说,第一次存储过程执行时,SQL Server预估的影响行数是1(注意不会出现0行),所以优化器认为对于查找单行数据,使用Col3列上的索引是最高效的。
为什么会出现这种情况呢?其实很难回答,因为不了解系统,不过显然这个并不是偶然事件。并且我有印象这个存储过程作为某些大操作的部分被执行很多次。可能是这个大操作总是以APPLE为启动值。记住,重建索引会出现重编译,而每晚因为碎片整理而带来的重建索引会触发重编译,所以在早上第一次调用时候的参数值对性能起了决定性的作用。
对于这个特定查询,有很多可能的措施去解决性能问题:
- OPTION(RECOMPILE)/ WITH RECOMPILE
- 添加一个可选的索引,覆盖Col1,Col2,Col3,并且包含Col4。
- 改写Col3的索引为筛选索引,或者直接删掉。
- 使用索引提示强制查询使用其他索引。
- 使用OPTIMIZE FOR查询提示。
- 把@p3的值复制到本地变量。
- 修改应用程序行为。
前面提到了强制重编译,并且也提到了,如果重编译有效,那么它基本上不是最佳方案,那么下面来看看那其他的方案:
添加新索引:
我对客户的建议就是这一条:添加合适查询的索引。也就是覆盖WHERE条件的索引,并且使用选择度最低的Col3作为索引键的最后一个值。然后加上包含Col4,以便查询能够只用一个索引就可以获取所需数据。
但是,添加新索引并不总是好的方案。如果一个表被多种查询以不同的方式访问,很难添加足够的索引来覆盖索引的WHERE和JOIN条件。特别是如果表的更新频率很高,如订单表,索引越多,增删改的开销就会明显增大。
更改/删除Col3上的索引:
Col3上的索引真正用处在哪里?因为不是熟悉的系统,所以也不能回答这个问题。但是通常来说,在选择度很低的列上的索引一般都不高效甚至无效。所谓其中一个方案就是删除Col3上的 索引,避免优化器对这些索引进行考虑。也许索引是因为某个原因在某个时候错误添加,或者是很多很多年前添加的。但是随着系统的使用,不能一成不变地对待。
不可否认,删除全部索引是需要勇气的。对此,你可以借助sys.dm_db_index_usage_stats 检查索引的使用情况。但是注意这个DMV的内容在SQL Server重启或者数据库离线时清空。
Col3上的数据分布很不均衡,但是也不是不存在有某些应用会去查找这些罕见值。这种情况下,把Col3_ix改为SQL 2008引入的过滤索引(filtered index)可能会有好处。比如使用下面的索引定义:
CREATE INDEX col3_ix ON Table_A(col3) WHERE col3 IN ('FIG', 'RASPBERRY', 'APPLE', 'APRICOT')
这样有两个好处:
- 索引的体积降低了将近99%。
- 这个索引不再成为问题查询的影响因素,因为SQL Server必须选择一个可以满足所有输入值的查询计划,所以即使嗅探到“APPLE”这个值,SQL Server也不会使用,这个索引,因为对于KIWI这个值而言,查询计划不能覆盖。
强制使用不同的索引:
如果你知道Col1,Col2上的索引总是最好的索引,但是不想增减其他索引,那么可以强制查询使用这个索引:
SELECT c.*
FROM Table_C c
JOIN Table_B b ON c.Col1 = b.Ccol2
JOIN Table_A a WITH (INDEX = Combo_ix)<strong> </strong>ON a.Col4 = b.Col1
WHERE a.Col1 = @p1
AND a.Col2 = @p2
AND a.Col3 = @p3
甚至可以改成:
WITH (INDEX (combo_ix, col2_ix))
让优化器在这两个“好”的索引之间选择。
索引提示很常用,甚至过于常用。在使用时你要三思,因为明天的数据分布可能会有很大改变,那么这个时候,另外一个索引可能更加好。另外一个问题就是当你后续要重构、修改这个索引时,可能会导致语句失败。
OPTIMIZE FOR:
这是一个查询提示,可以用来控制参数嗅探,比如上面语句,可以写成:
SELECT c.*
FROM Table_C c
JOIN Table_B b ON c.col1 = b.col2
JOIN Table_A a ON a.col4 = b.col1
WHERE a.col1 = @p1
AND a.col2 = @p2
AND a.col3 = @p3
OPTION (OPTIMIZE FOR (@p3 = 'KIWI'))
这个提示告诉SQL Server忽略输入值,而是按@p3的值为KIWI(也就是Col3中数据对多的值)的值来编译查询,这样也可以阻止SQL Server使用不合理的索引。作为另一个选择,从SQL 2008开始,可以用:
OPTION (OPTIMIZE FOR (@p3 UNKNOWN))
相对于在代码中硬编码某些值,你可以通过这种方式强制SQL Server通过盲目假设完全避免对@p3的参数嗅探。另外,还可以对本地变量使用这种OPTIMIZE FOR,这个提示不仅仅针对参数有效。
复制参数到本地变量:
相对于在查询中直接使用@p3参数,可以把值复制到本地变量然后在语句中使用本地变量。这个效果和OPTIMIZE FOR UNKNOWN一样。并且这种方式适合于SQL Server所有版本,而不像OPTIMIZE FOR UNKNOWN那样只可以用在SQL 2008及后续版本。
修改应用程序:
在这个例子中,可以修改应用程序,让它以别的值作为启动值,但是这个不是建议方案,因为这样就使得应用程序和数据库之间有了强连接。如果在多年之后修改程序,可能会带来更严重的风险和隐患。
小结:
从这个例子中可以看到,有很多方式可选。但是性能优化往往需要有一个工具集,因为不同的问题需要采取不同的解决方案。
应用程序缓存引起的案例:
在某些系统中,存在一种应用程序缓存用于保存主存数据库的数据,暂且称为MemDB。基于某些目的而存在,但是主要的目的是为了缓存常用数据到内存中。常见场景是每天早上刷新数据。当数据库的数据被更新,为了获取那些变动的数据,会有内部机制触发MemDB运行一个存储过程获取数据。MemDB依赖于timestamp列。(timestamp列为8字节的、库内唯一的、单调递增的、每次行被插入或修改时自动更新的列)存储过程类似:
CREATE PROCEDURE memdb_get_updated_customers @tstamp timestamp AS
SELECT CustomerID, CustomerName, Address, ..., tstamp
FROM Customers
WHERE tstamp > @tstamp
当MemDB调用这些存储过程时,会传入timestamp中最高的值,主存数据库会传回0x作为参数,获取所有数据。在某些情况下,发现MemDB的存储过程运行时间很长,引入MemDB的目的是分担负载,但是现在反而增加了。
为了加快存储过程的执行,需要在timestamp列上加索引,但是这个索引会被用到吗?前面提到过,每天早上会运行这个存储过程,MemDB会运行:
EXEC memdb_get_updated_customers 0x
然后隔一段时间会运行:
EXEC memdb_get_updated_customers 0x000000000003E806
但是在夜间因为某些批处理导致内存不足的情况下,存储过程实行失败并不是罕见的事情。所以常见的情况有,在早上运行时,缓存里面实际上没有任何查询计划,然后嗅探0x值。对于这个值,优化器会使用Timestamp上的索引吗?如果是聚集索引,会嗅探,但是由于Timestamp更新得如此频繁,以至这个列并不适合作为聚集索引的候选键。所以一般Timestamp上的索引都是非聚集索引,因此,当优化器看到参数意味着需要返回所有数据,会使用表扫描操作,这个查询计划会放入计划缓存,然后后续的执行都会使用表扫描,即使仅仅是查询最常用的行。这明显会影响性能。
当你遇到类似情况时,可以使用前面提到的方式去避免。但是这里有点特别,对于所有情况下都没有所谓的好的查询计划,我们希望使用索引来读取数据,但是在刷新时我们又希望使用扫描,所以,在产生不同的查询计划是,都需要不同的方案来应对。
OPTION(RECOMPILE):
前面提到过,当这个方式有效时,证明并不是好的解决方案。意味着每次我们获取数据,都要进行编译,虽然上面的存储过程看上去很简单,但是对于一些相当复杂的程序而言,编译的开销相当巨大。
EXECUTE WITH RECOMPILE:
相对于在存储过程里面调用重编译,更好的方式是:刷新。通常来说只需要每天刷新一次。另外,刷新本身也是很高开销的操作,所以这里重编译的边界要定好。也就是说,当MemDB需要刷新时,应该按下面方式调用:
EXECUTE memdb_get_updated_customers WITH RECOMPILE
前面提到,这等于在早上没有查询计划在缓存中,所以什么时候执行?应该在执行编译时,查询计划没有放进缓存,因此刷新可以运行扫描,但是第二次查找数据是产生计划缓存。简单来说,我们除了第一次执行时需要使用重编译选项,后面的执行不需要。
对于系统中的特定问题,这个方案有个优势就是在MemDB中仅有单个代码路径需要改变。
但是这个解决方案还有个小问题。通常来说,当你从客户端调用一个存储过程时,你只使用存储过程名。(如ADO.NET中的CommandType.StoredProcedure)客户端API发出一个RPC(远程程序调用,remote procedure call)到SQL Server,并不存在一个类似的EXECUTE命令。而且很少API会使用WITH RECOMPILE。所以应该使用下面方式调用:
cmd.CommandType = CommandType.Text;
cmd.Text = "EXECUTE memdb_get_updated_customers @tstamp WITH RECOMPILE";
使用一个封装好的存储过程:
如果你发现使用EXECUTE WITH RECOMPILE是目前最好的解决方案,但是修改客户端的方式不可行,可以引入一个封装好的存储过程。比如下面方式:
CREATE PROCEDURE memdb_get_updated_customers @tstamp timestamp AS
IF @tstamp = 0x
EXECUTE memdb_get_updated_customers_inner @tstamp WITH RECOMPILE
ELSE
EXECUTE memdb_get_updated_customers_inner @tstamp
不同的代码路径:
另外一种方式是在存储过程中使用不同的代码路径应对不同的情况,如:
CREATE PROCEDURE memdb_get_updated_customers @tstamp timestamp AS
IF @tstamp = 0x
BEGIN
SELECT CustomerID, CustomerName, Address, ..., tstamp
FROM Customers
END
ELSE
BEGIN
SELECT CustomerID, CustomerName, Address, ..., tstamp
FROM Customers WITH (INDEX = timestamp_ix)
WHERE tstamp > @tstamp
END
注意在ELSE部分强制使用索引,这种方式很重要,否则会因为参数嗅探导致ELSE分支依旧使用@tstmp=0x所生成的表扫描查询计划。但是对于很复杂的代码而言,这种方式会很困难,即使你强制指定索引,由于统计信息的原因,可能选择不合适的JOIN策略,导致查询计划的低效。
不同的存储过程:
如果在前面提到的情况下都不合适,那么可以考虑使用不同的存储过程处理不同的情况,然后再在外层封装存储过程,如下:
CREATE PROCEDURE memdb_get_transactions @transid int AS
IF coalesce(@transid, 0) = 0
EXECUTE memdb_get_transactions_refresh
ELSE
BEGIN
DECLARE @maxtransid int
SELECT @maxtransid = MAX(transid) FROM transactions
EXECUTE memdb_get_transactions_delta @transid, @maxtransid
END
这部分比较易懂,不做详细说明。
修复问题SQL:
很多情况下,问题是在语句编码层面,比如下面语句:
SELECT ...
FROM Orders
WHERE (CustomerID = @custid OR @custid IS NULL)
AND (EmployeeID = @empid OR @empid IS NULL)
AND convert(varchar, OrderDate, 101) = convert(varchar, @orderdate, 101)
允许用户查询很多不同的参数组合。开发人员考虑到OrderDate可能包含时间部分,所以使用了Convert()函数来补全程序端传入不带时间部分的参数。对于这个查询,OrderDate上的索引会被优化器选中,但是这种情况下,SQL Server不会使用索引查找,因为OrderDate已经变成了表达式,由于统计信息丢失原因,这种情况成为非SARG写法。
由于OrderDate上的索引被非SARG写法导致索引失效,优化器必须从其他索引中选择,这个选择依赖于第一个参数,会引起后续其他类型参数的低性能,补救方式可以考虑下面写法:
SELECT ...
FROM Orders
WHERE (CustomerID = @custid OR @custid IS NULL)
AND (EmployeeID = @empid OR @empid IS NULL)
AND OrderDate >= @orderdate
AND OrderDate < dateadd(DAY, 1, @orderdate)
低效写法通常是性能问题的常见原因,也就是说查询总是很慢。哪怕跟参数嗅探没有关系。但是当你遇到参数嗅探问题时,探讨是否可以避免输入不好的参数避免参数嗅探也同样依赖写法。低效写法有很多中,不可能在这里一一列出。隐式转换是常见的情况,同样会导致索引失效。
总结:
这一节演示了几个参数嗅探问题及其应对方法。下一篇将介绍
SQL Server如何编译动态SQL

 浙公网安备 33010602011771号
浙公网安备 33010602011771号