
理解性能的奥秘——应用程序中慢,SSMS中快(3)——不总是参数嗅探的错
在我们开始深入研究如何处理参数嗅探相关的性能问题之前,由于这个课题过于广泛,所以首先先介绍一些跟参数嗅探没有直接关系的内容,但是又会导致语句在SSMS和应用程序中存在性能差异的情况。
替换变量和参数:
前面已经接触过,但是在这里对其进行扩展。有时会看到论坛上有人说,某个存储过程很慢,但是把相同的语句提取出来单独执行就很快。真相就是:语句涉及了变量,可能是本地变量或者参数。为了单独检查语句问题,他们把变量替换成常量。但是前面提到过,单独的语句和在存储过程中很不一样,当用常量替换变量时,SQL Server可以更加准确地预估影响行数,从而生成更好的查询计划。并且SQL Server不用考虑下一次运行是,常量会被改变。
另外一个类似的错误就是把参数放入变量中,如:
CREATE PROCEDURE some_sp @par1 int
AS
...
-- 某些使用到变量 @par1的语句
你想检查某个语句问题,所以你改成:
DECLARE @par1 int
SELECT @par1 = 4711
-- 接下来的语句
上一节已经说过,这种方式和原来方式有很大不同,SQL Server因为不清楚本地变量的情况,所以会使用标准假设(一般就是表总数的30%)。但是如果你有一个千行代码的存储过程,然后其中某个语句很慢,要如何定位问题,同时又能保持与在存储过程中一样的环境呢?其中一个简单但也存在限制的方法就是添加“OPTION(RECOMPILE)”提示到语句的最后,这个提示仅在SQL 2005中有效,可以触发语句对所有参数、变量在运行时进行参数嗅探和重编译。
但是这个方法只对只有一个参数的查询或者存储过程中没有本地变量的情况有用。(因为本地变量的值通常不会被嗅探。)另外,这个方法对SQL 2008及后续版本无效,因为OPTION(RECOMPILE)的实现方式变得更加合理:如果所有变量值都是常数,SQL Server会编译查询。(由于一个致命bug的存在,微软不得不把这种行为恢复,所以并不能应用于所有的SQL 2008版本中)。
一个总能生效的方式就是把语句封装到sp_executesql中:
EXEC sp_executesql N'-- 牵涉到参数的语句 @par1', N'@par1 int', 4711
这里需要注意的是,对于字符文本,需要使用双引号包住。如果查询涉及本地变量,可以在动态SQL中赋值。
还有一种方式就是创建一个带有问题语句的虚拟存储过程,为了避免数据库中存在垃圾对象,你可以使用临时存储过程:
CREATE PROCEDURE #test @par1 int AS
-- 问题语句.
如果是动态SQL ,也同样确保在这类存储过程中进行局部定义本地变量。但是需要警告一下,目前还没发现SQL Server是否有对临时存储过程有特殊的调整或优化的限制。
阻塞:
不要忘记应用程序运行慢的其中一个可能原因就是与阻塞 有关。当你在3小时后在SSMS中测试查询时,阻塞源可能已经结束。如果你在SSMS中不管是否改动ARITHABORT,运行存储过程都没问题,一直都很快,那么阻塞就应该纳入考虑内容并进行深究。但是这个话题很大,也超出了本系列的主旨,所以可以看作者的另外一篇文章(以后有空也会一起翻译)beta lockinfo
索引视图和索引化的计算列:
在SQL 2000时代,这个问题比后续版本严重很多,从SQL Server 2005开始,所以视图和索引化后的计算列(包括SQL 2008加入的过滤索引filter index)在语句编译期间,下面的设置必须为ON:QUOTED_IDENTIFIER, ANSI_NULLS, ANSI_WARNINGS, ANSI_PADDING, CONCAT_NULL_YIELDS_NUL,而NUMERIC_ROUNDABORT必须为OFF。
而在SQL 2000中,应用程序使用默认SET选项对索引化的计算列和索引视图是没有什么好处的。但是即使存在参数嗅探,当你在SSMS或查询分析器中运行是,性能也往往可能好很多,因为ARITHABORT默认为ON。
但是由于SQL 2000时代过去太久了,估计已经很少人还在用,所以如果对这个内容有兴趣,读者可以去看原文,因为这部分主要是对SQL 2000描述的。点击打开链接
链接服务器的问题:
这里假定你用的远程服务器是SQL 2012 SP1之前的版本。假设下面的语句:
SELECT C.*
FROM SOME_SERVER.Northwind.dbo.Orders O
JOIN Customers C
ON O.CustomerID = C.CustomerID
WHERE O.OrderID > 20000
以两个不同的用户运行了语句两次。第一个用户是两台服务器的sysadmin,第二个用户仅有SELECT权限。为了确保得到不同缓存条目, 使用了不同的ARITHABORT设置。在以sysadmin运行时,查询计划如下:
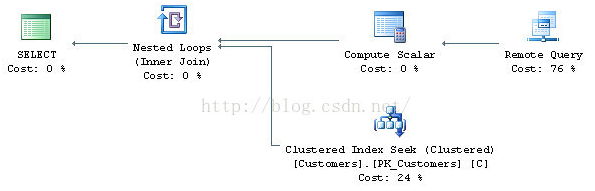
以普通用户运行是,得到的执行计划如下:
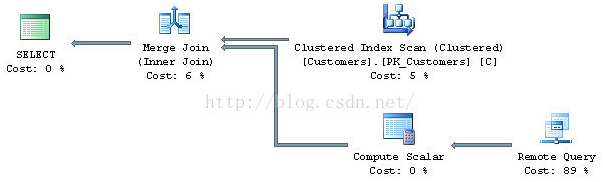
为什么查询计划不一样呢?可以肯定的是不是参数嗅探问题,因为语句没有参数。但是当发现查询计划不是与其形状或者预期操作符时,应该看看预估行数。这两个查询计划的“Remote Query”操作符的属性如下:左边的是第一个,右边的是第二个


可以发现预估行数不一样。当以sysadmin身份运行时,预估行数为1,这是正确的数量,因为Northwind库的Orders表中不存在Order ID超过20000的数据。但是当以普通用户运行时,预估行数为249行。也就是表总数的30%。因为此时统计信息丢失导致优化器对数据量的预估不准确。
当查询直接访问本地实例的表时,优化器可以得到语句相关的所有表的统计信息,不存在额外的权限检查。
当SQL Server访问一个链接服务器时,服务器之间的通讯并没有使用专用的的协议,而是使用标准的OLE DB接口访问链接服务器,其他诸如sql server实例、oracle、文本文件或任何自定义数据源也是如此。具体如何获取统计信息还要取决于数据源和请求的OLE DB Provider。 在这种情况下,SQL Server Native Client会通过两步获得统计信息(可以在远程服务器上使用Profiler检查):
- SQL Server Native Client驱动会先运行sp_table_statistics2_rowset返回统计信息包含的列的信息,也包括了基数信息和密度信息。
- 驱动运行DBCC SHOW_STATISTICS,返回完整的分布统计信息。
直到从SQL Server 2012 RTM位置,为了有足够权限运行DBCC SHWO_STATISTICS命令,必须使用属于sysadmin角色或者数据库层面的db_owner或db_ddladmin角色的权限。
所以使用不同权限的账号运行同一个语句的时候,会得到不同的结果,当以sysadmin运行的时候,可以获取完整的分布信息,意味着能发现没有数据复合orderid>20000的条件,所以预估行数为1(注意SQL Server永远不会用预估行数为0代表没有匹配数据)。但是以普通用户运行时,因为权限问题导致DBCC SHOW_STATISTICS失败,而且不抛出错误,以优化器接受“没有统计信息”为替代方案,然后进行默认假设。所以在基数预估的时候就不够准确了。
不管什么时候,当你遇到一个包含链接服务器查询,在应用程序中很慢,在SSMS中很快时,你都应该检查一下是否权限问题导致的。如果是权限问题,那么可以考虑下面方案:
- 可以把用户加到远程数据库的db_ddladmin角色中,但是这个意味着用户可以增加和删除表,一般不建议。
- 默认情况下,一个用户连接远程服务器的时候,都是使用远程服务器中相同的账号,但是可以使用sp_addlinkedsrvlogin映射 一个登录号,以便用户有权限执行属于db_ddladminde 角色的事情。但是这个账号必须是SQL 登录账号,所以要确保远程服务器是否启用了混合身份验证,但是这种方案从安全角度来说还是有问题。
- 某些情况下可以改写成OPENQUERY强制在远程服务器中进行预估。如果查询包含了多个远程表的情况下,这种方式特别有效。(但是也有风险,因为优化器可能只能从远程服务器中获取更少的统计信息。)
- 也可以使用完整的提示和计划向导来实现你期望的查询计划。
- 最后,要考虑一下是否真的有必要使用链接服务器而不能放在同一个 服务器上?能否修改?或者有其他解决方案?
再次提醒:重要的是查询在远程服务器上是否有权限,而不是在本地服务器上。另外,这个问题仅存在于远程服务器的SQL Server版本是SQL Server 2012 RTM及以前版本的SQL Server。从SQL 2012 SP1开始,执行DBCC SHOW_STATISTICS的权限要求已经被放宽,只要有SELECT权限即可执行。
小结:
本节没有介绍参数嗅探的情况,而是 介绍一些同样也会导致在应用程序中很慢,在SSMS中很快的情况。但是因为本主题主要是介绍参数嗅探,所以还是尽可能把篇幅放在这个点上,下一节将会介绍:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号