【Spring注解驱动开发】面试官再问你BeanPostProcessor的执行流程,就把这篇文章甩给他!
写在前面
在前面的文章中,我们讲述了BeanPostProcessor的postProcessBeforeInitialization()方法和postProcessAfterInitialization()方法在bean初始化的前后调用,我们可以自定义类来实现BeanPostProcessor接口,并在postProcessBeforeInitialization()方法和postProcessAfterInitialization()方法中指定我们自定义的逻辑。今天,我们来一起探讨下eanPostProcessor底层原理。
项目工程源码已经提交到GitHub:https://github.com/sunshinelyz/spring-annotation
bean的初始化和销毁
我们知道BeanPostProcessor的postProcessBeforeInitialization()方法在bean的初始化之前调用;而postProcessAfterInitialization()方法在bean初始化的之后调用。而bean的初始化和销毁方法我们可以通过如下方式进行指定。
1.通过@Bean指定init-method和destroy-method
@Bean(initMethod="init",destroyMethod="detory")
public Car car(){
return new Car();
}
2.通过让Bean实现InitializingBean(定义初始化逻辑)
@Component
public class Cat implements InitializingBean,DisposableBean {
public Cat(){
System.out.println("cat constructor...");
}
@Override
public void destroy() throws Exception {
System.out.println("cat...destroy...");
}
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("cat...afterPropertiesSet...");
}
}
3.可以使用JSR250
- @PostConstruct:在bean创建完成并且属性赋值完成;来执行初始化方法。
- @PreDestroy:在容器销毁bean之前通知我们进行清理工作。
@Component
public class Dog implements ApplicationContextAware {
//@Autowired
private ApplicationContext applicationContext;
public Dog(){
System.out.println("dog constructor...");
}
//对象创建并赋值之后调用
@PostConstruct
public void init(){
System.out.println("Dog....@PostConstruct...");
}
//容器移除对象之前
@PreDestroy
public void detory(){
System.out.println("Dog....@PreDestroy...");
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
}
4.可以使用BeanPostProcessor
/**
* 后置处理器:初始化前后进行处理工作
* 将后置处理器加入到容器中
* 在bean初始化前后进行一些处理工作;
* postProcessBeforeInitialization:在初始化之前工作
* postProcessAfterInitialization:在初始化之后工作
*/
@Component
public class MyBeanPostProcessor implements BeanPostProcessor,Ordered {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("postProcessBeforeInitialization..."+beanName+"=>"+bean);
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
// TODO Auto-generated method stub
System.out.println("postProcessAfterInitialization..."+beanName+"=>"+bean);
return bean;
}
@Override
public int getOrder() {
return 3;
}
}
通过这几种方式,我们就可以对bean的整个生命周期进行控制:
- 从bean的实例化:调用bean的构造方法,我们可以在bean的无参构造方法中执行相应的逻辑。
- bean的初始化:在初始化时,可以通过BeanPostProcessor的postProcessBeforeInitialization()方法和postProcessAfterInitialization()方法进行拦截,执行自定义的逻辑;通过@PostConstruct注解、InitializingBean和init-method来指定bean初始化前后执行的方法,执行自定义的逻辑。
- bean的销毁:可以通过@PreDestroy注解、DisposableBean和destroy-method来指定bean在销毁前执行的方法,指执行自定义的逻辑。
所以,通过上述方式,我们可以控制Spring中bean的整个生命周期。
BeanPostProcessor源码解析
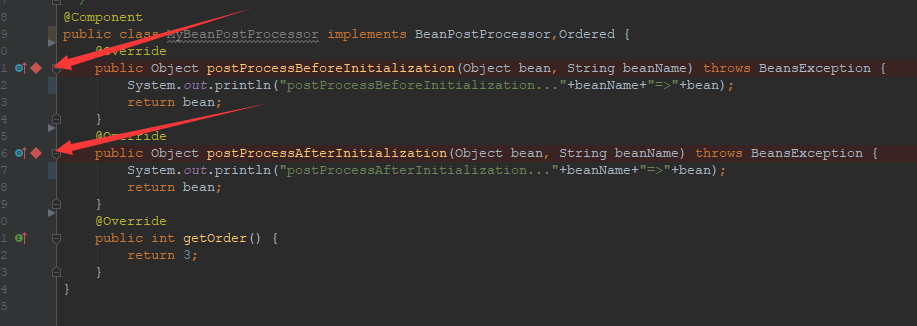
如果想深刻理解BeanPostProcessor的工作原理,那就不得不看下相关的源码,我们可以在MyBeanPostProcessor类的postProcessBeforeInitialization()方法和postProcessAfterInitialization()方法中打上断点来进行调试。如下所示。
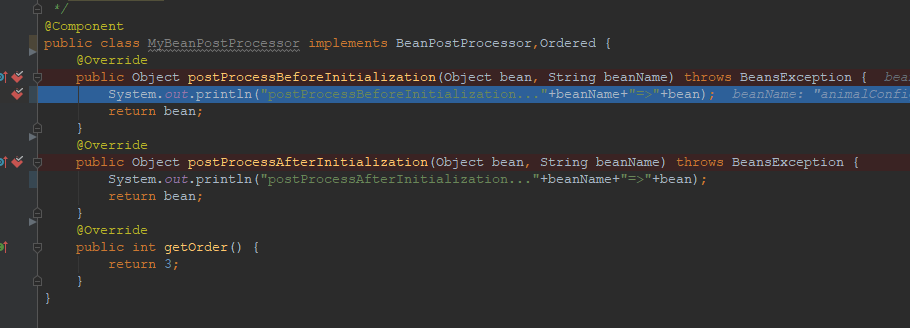
随后,我们以Debug的方式来运行BeanLifeCircleTest类的testBeanLifeCircle04()方法,运行后的效果如下所示。
可以看到,程序已经运行到MyBeanPostProcessor类的postProcessBeforeInitialization()方法中,在IDEA的左下角我们可以清晰的看到方法的调用栈,如下所示。
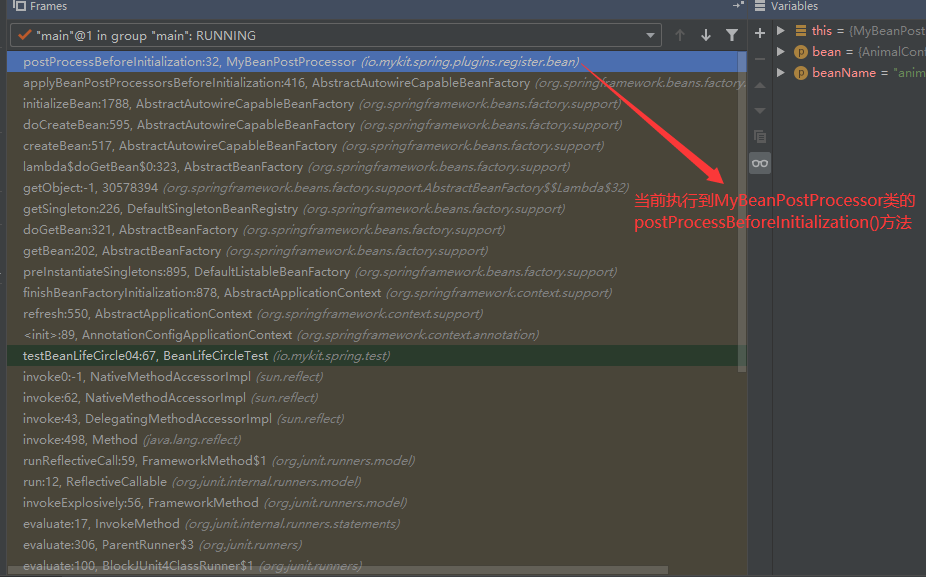
通过这个方法调用栈,我们可以详细的分析从运行BeanLifeCircleTest类的testBeanLifeCircle04()方法开始,到进入MyBeanPostProcessor类的postProcessBeforeInitialization()方法的执行流程。只要我们在IDEA的方法调用栈中找到BeanLifeCircleTest类的testBeanLifeCircle04()方法,依次分析方法调用栈中在BeanLifeCircleTest类的testBeanLifeCircle04()方法上面位置的方法,即可了解整个方法调用栈的过程。要想定位方法调用栈中的方法,只需要在IDEA的方法调用栈中单击相应的方法即可。
注意:方法调用栈是先进后出的,也就是说,最先调用的方法会最后退出,每调用一个方法,JVM会将当前调用的方法放入栈的栈顶,方法退出时,会将方法从栈顶的位置弹出。有关方法调用的具体细节内容,后续会在【JVM】专栏详细介绍,这里,小伙伴们就先了解到此即可。
接下来,我们在IDEA的方法调用栈中,找到BeanLifeCircleTest类的testBeanLifeCircle04()方法并单击,此时IDEA的主界面会定位到BeanLifeCircleTest类的testBeanLifeCircle04()方法,如下所示。
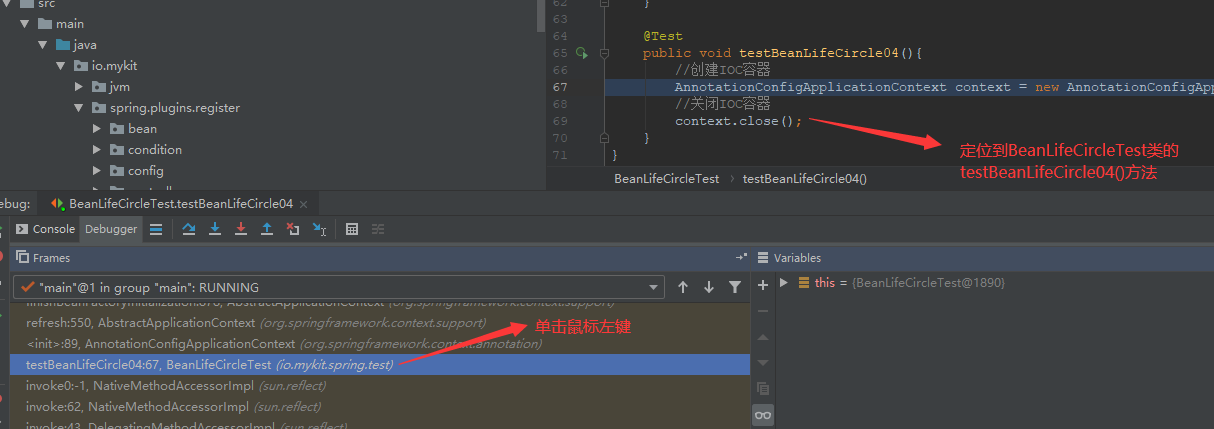
在BeanLifeCircleTest类的testBeanLifeCircle04()方法中,首先通过new实例对象的方式创建了一个IOC容器。接下来,通过IDEA的方法调用栈继续分析,接下来,进入的是AnnotationConfigApplicationContext类的构造方法。

在AnnotationConfigApplicationContext类的构造方法中会调用refresh()方法。我们跟进方法调用栈,如下所示。
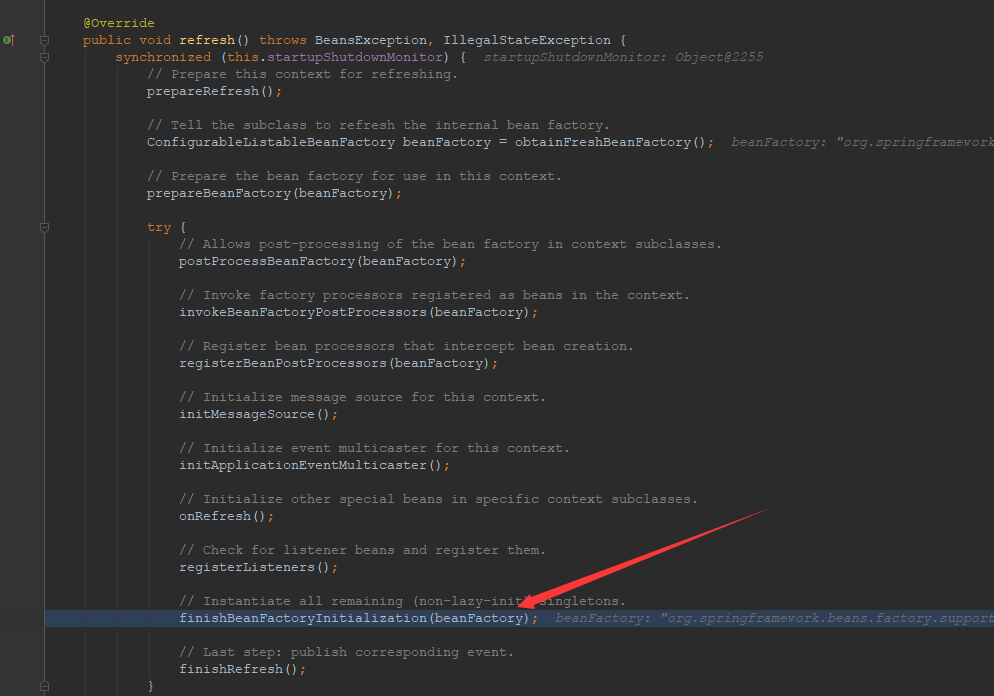
可以看到,方法的执行定位到AbstractApplicationContext类的refresh()方法中的如下代码行。
finishBeanFactoryInitialization(beanFactory);
这行代码的作用就是:初始化所有的(非懒加载的)单实例bean对象。
我们继续跟进方法调用栈,如下所示。
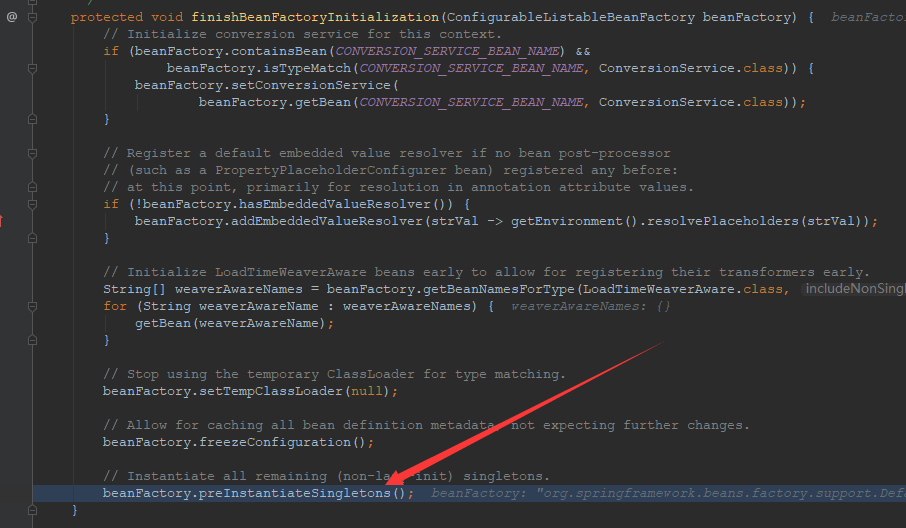
此时,方法的执行定位到AbstractApplicationContext类的finishBeanFactoryInitialization()方法的如下代码行。
beanFactory.preInstantiateSingletons();
这行代码的作用同样是:初始化所有的(非懒加载的)单实例bean。
我们继续跟进方法调用栈,如下所示。
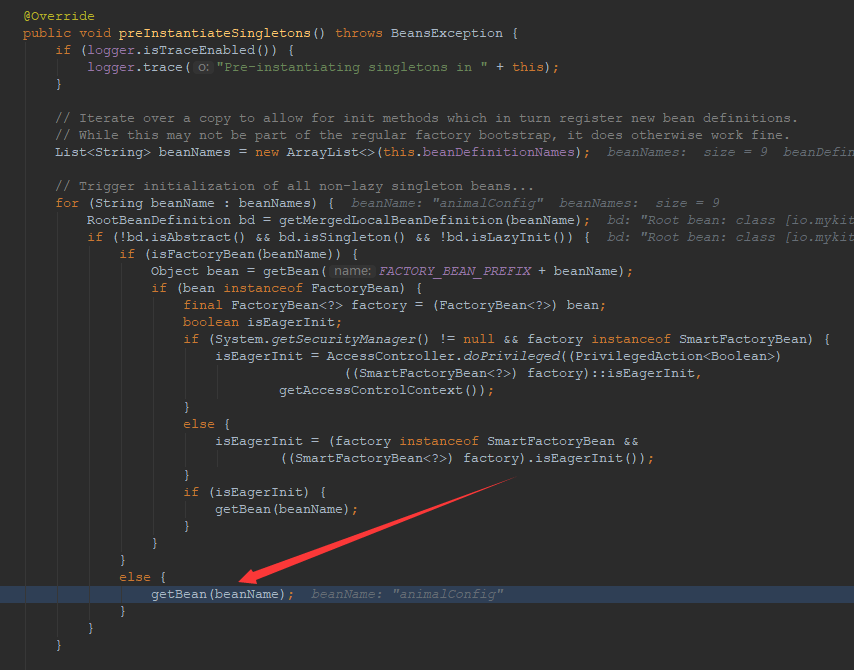
可以看到,方法的执行定位到DefaultListableBeanFactory的preInstantiateSingletons()方法的最后一个else分支调用的getBean()方法上。继续跟进方法调用栈,如下所示。

此时方法定位到AbstractBeanFactory类中的getBean()方法中,在getBean()方法中,又调用了doGetBean()方法,通过方法调用栈我们可以得知方法的执行定位到AbstractBeanFactory类中的doGetBean()方法的如下代码段。
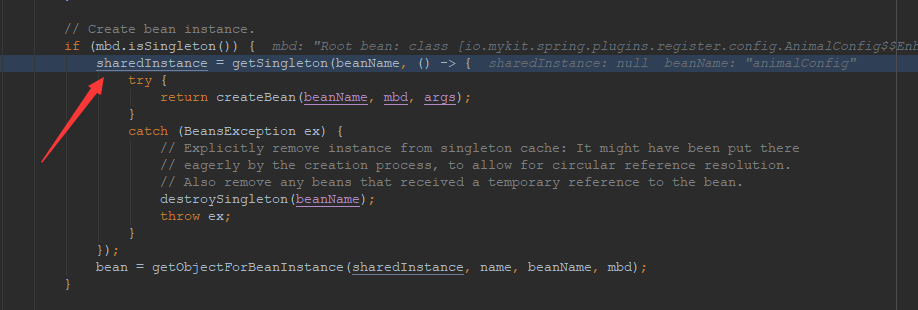
可以看到,在Spring内部是通过getSingleton()来获取单实例bean的,我们继续跟进方法调用栈,如下所示。
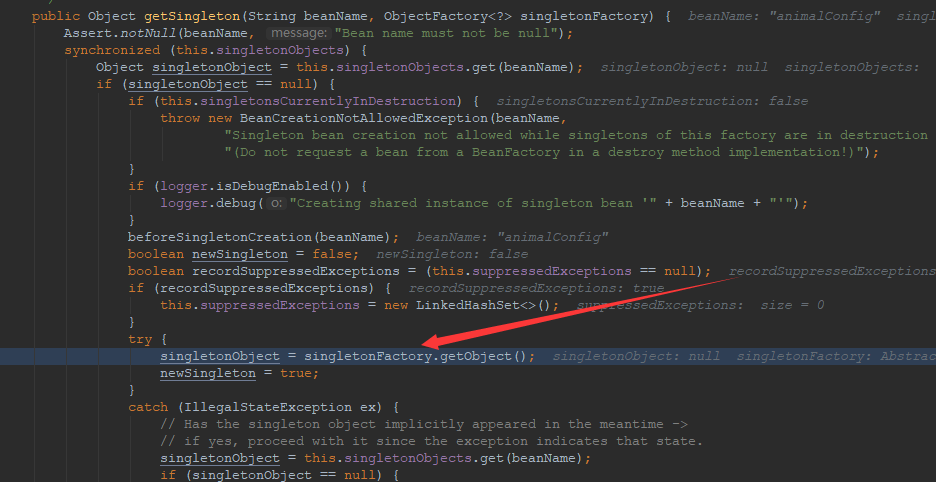
此时,方法定位到了DefaultSingletonBeanRegistry了类的getSingleton()方法的如下代码行。
singletonObject = singletonFactory.getObject();
继续跟进方法调用栈,如下所示。
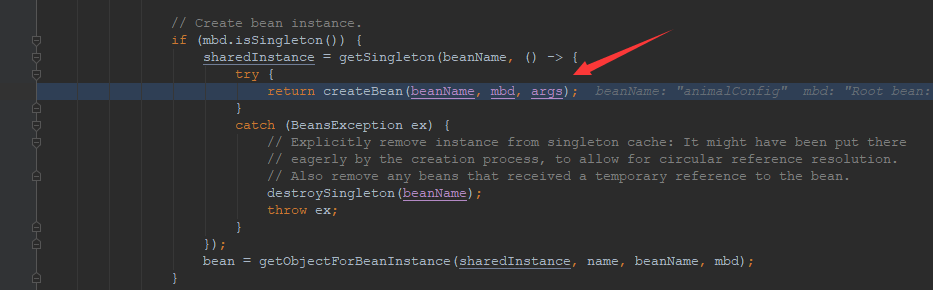
此时,方法会定位到AbstractBeanFactory类的doGetBean()方法中的如下代码行。
return createBean(beanName, mbd, args);
也就是说,当第一次获取单实例bean时,由于单实例bean还未创建,Spring会调用createBean()方法来创建单实例bean。继续跟进方法调用栈,如下所示。
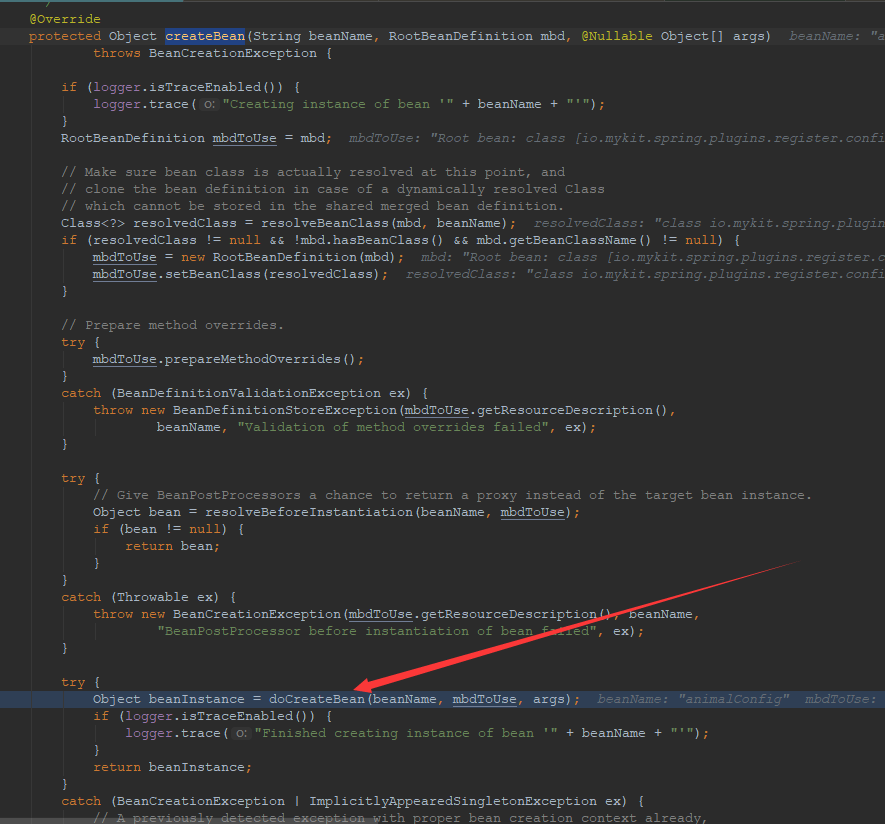
可以看到,方法的执行定位到AbstractAutowireCapableBeanFactory类的createBean()方法的如下代码行。
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
可以看到,Spring中创建单实例bean调用的是doCreateBean()方法。没错,继续跟进方法调用栈,如下所示。
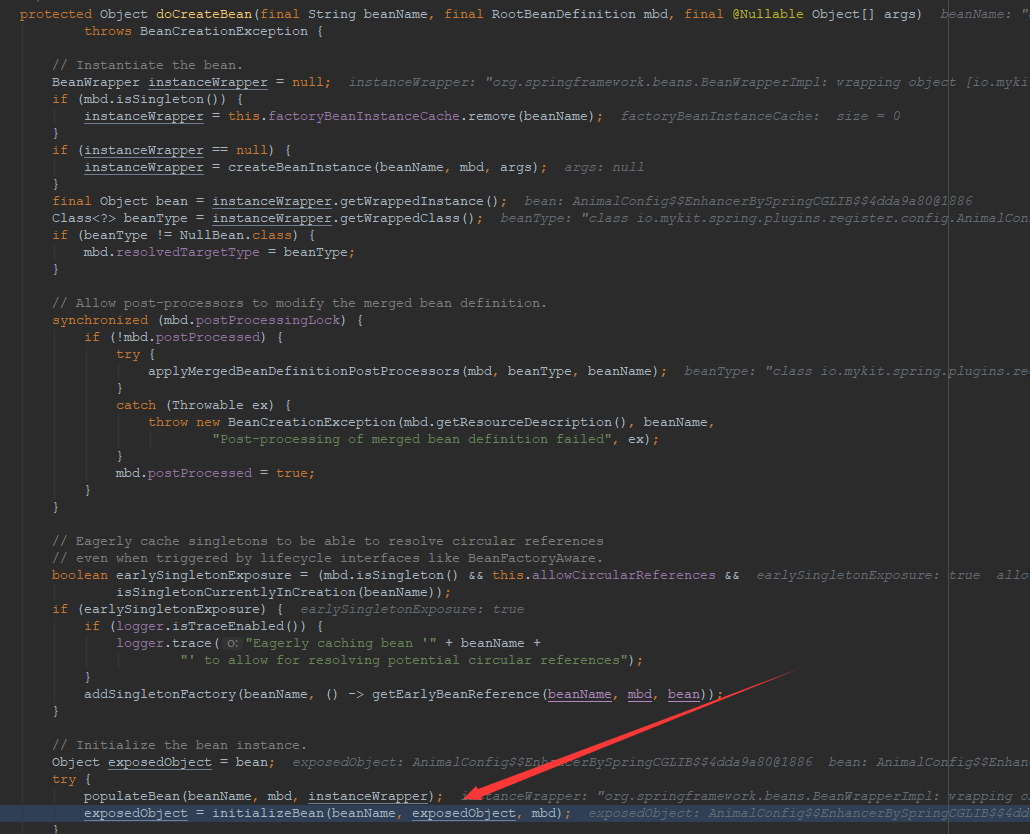
方法的执行已经定位到AbstractAutowireCapableBeanFactory类的doCreateBean()方法的如下代码行。
exposedObject = initializeBean(beanName, exposedObject, mbd);
继续跟进方法调用栈,如下所示。
方法的执行定位到AbstractAutowireCapableBeanFactory类的initializeBean()方法的如下代码行。
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
小伙伴们需要重点留意一下这个applyBeanPostProcessorsBeforeInitialization()方法。回过头来我们再来看AbstractAutowireCapableBeanFactory类的doCreateBean()方法中的如下代码行。
exposedObject = initializeBean(beanName, exposedObject, mbd);
没错,在AbstractAutowireCapableBeanFactory类的doCreateBean()方法中调用的initializeBean()方法中调用了后置处理器的逻辑。小伙伴们需要注意一下,在AbstractAutowireCapableBeanFactory类的doCreateBean()方法中调用的initializeBean()方法之前,调用了一个populateBean()方法,代码行如下所示。
populateBean(beanName, mbd, instanceWrapper);
我们点到这个populateBean()方法中,看下这个方法执行了哪些逻辑,如下所示。
populateBean()方法同样是AbstractAutowireCapableBeanFactory类中的方法,populateBean()方法的代码比较多,其实逻辑非常简单,populateBean()方法做的工作就是为bean的属性赋值。也就是说,在Spring中会先调用populateBean()方法为属性赋好值,然后再调用initializeBean()方法。接下来,我们好好分析下initializeBean()方法,为了方便,我将Spring中AbstractAutowireCapableBeanFactory类的initializeBean()方法的代码拿出来,如下所示。
protected Object initializeBean(final String beanName, final Object bean, @Nullable RootBeanDefinition mbd) {
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
invokeAwareMethods(beanName, bean);
return null;
}, getAccessControlContext());
}
else {
invokeAwareMethods(beanName, bean);
}
Object wrappedBean = bean;
if (mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
try {
invokeInitMethods(beanName, wrappedBean, mbd);
}
catch (Throwable ex) {
throw new BeanCreationException(
(mbd != null ? mbd.getResourceDescription() : null),
beanName, "Invocation of init method failed", ex);
}
if (mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
return wrappedBean;
}
在initializeBean()方法中,调用了invokeInitMethods()方法,代码行如下所示。
invokeInitMethods(beanName, wrappedBean, mbd);
invokeInitMethods()方法的作用就是:执行初始化方法,这些初始化方法包括我们之前讲的: 在xml文件中的
在调用invokeInitMethods()方法之前,Spring调用了applyBeanPostProcessorsBeforeInitialization()方法,代码行如下所示。
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
在调用invokeInitMethods()方法之后,Spring调用了applyBeanPostProcessorsAfterInitialization()方法,如下所示。
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
这里,我们先来看看applyBeanPostProcessorsBeforeInitialization()方法中具体执行了哪些逻辑,applyBeanPostProcessorsBeforeInitialization()方法位于AbstractAutowireCapableBeanFactory类中,源码如下所示。
@Override
public Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor processor : getBeanPostProcessors()) {
Object current = processor.postProcessBeforeInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}
可以看到,在applyBeanPostProcessorsBeforeInitialization()方法中,会遍历所有BeanPostProcessor对象,执行所有BeanPostProcessor对象的postProcessBeforeInitialization()方法,一旦BeanPostProcessor对象的postProcessBeforeInitialization()方法返回null,则后面的BeanPostProcessor对象不再执行,直接退出for循环。
看Spring源码,我们看到一个细节, 在Spring中调用initializeBean()方法之前,调用了populateBean()方法来为bean的属性赋值。
我们将关键代码的调用过程使用如下伪代码表述出来。
populateBean(beanName, mbd, instanceWrapper);
initializeBean(beanName, exposedObject, mbd){
applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
invokeInitMethods(beanName, wrappedBean, mbd);
applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
也就是说,在Spring中,调用initializeBean()方法之前,调用了populateBean()方法为bean的属性赋值,为bean的属性赋好值之后,再调用initializeBean()方法进行初始化。
在initializeBean()中,调用自定义的初始化方法invokeInitMethods()之前,调用了applyBeanPostProcessorsBeforeInitialization()方法,而在调用自定义的初始化方法invokeInitMethods()之后,调用了applyBeanPostProcessorsAfterInitialization()方法。整个bean的初始化过程就结束了。
好了,咱们今天就聊到这儿吧!别忘了给个在看和转发,让更多的人看到,一起学习一起进步!!
项目工程源码已经提交到GitHub:https://github.com/sunshinelyz/spring-annotation
写在最后
如果觉得文章对你有点帮助,请微信搜索并关注「 冰河技术 」微信公众号,跟冰河学习Spring注解驱动开发。公众号回复“spring注解”关键字,领取Spring注解驱动开发核心知识图,让Spring注解驱动开发不再迷茫。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号