
【高并发】为何高并发系统中都要使用消息队列?这次彻底懂了!
写在前面
很多高并发系统中都会使用到消息队列中间件,那么,问题来了,为什么在高并发系统中都会使用到消息队列中间件呢?立志成为资深架构师的你思考过这个问题吗?
本文集结了众多技术大牛的编程思想,由冰河汇聚并整理而成,在此,感谢那些在技术发展道理上默默付出的前辈们!
场景分析
现在假设这样一个场景,用户下单成功需要给用户发短信,如果没有消息队列,我们会选择同步调用发短信的接口并等待短信发送成功。现在假设短信接口实现出现了问题或者短信发送短时间内达到了上限,这个时候是选择重试几次还是放弃发送呢?这里的设计会很复杂。如果使用了消息队列,我们选择将发短信的操作封装成一条消息发送到消息队列,消息队列通知一个服务去发送一条短信,即使出现了上述的问题,可以选择把消息重新放到消息队列里等待处理。
消息队列的好处
通过上述了例子,我们看到消息队列完成了一个异步解耦的过程,短信发送时我们只要保证短信发到消息队列成功就可以了,接下来就可以去做别的事情;其次,设计变得更简单,在下单的场景下,我们不用过多考虑发送短信的问题,交给消息队列管理就行了,可能短信发送会有延迟,但是保证了最终的一致性。
消息队列特性
- 业务无关,只做消息分发。
- FIFO,先投递先到达。
- 容灾:节点动态增删和消息持久化。
- 性能:吞吐量提升,系统内部通信效率提高。
高并发系统为何使用消息队列?
(1)业务解耦
成功完成了一个异步解耦的过程。短信发送时只要保证放到消息队列中就可以了,接着做后面的事情就行。一个事务只关心本质的流程,需要依赖其他事情但是不那么重要的时候,有通知即可,无需等待结果。每个成员不必受其他成员影响,可以更独立自主,只通过一个简单的容器来联系。
对于我们的订单系统,订单最终支付成功之后可能需要给用户发送短信积分什么的,但其实这已经不是我们系统的核心流程了。如果外部系统速度偏慢(比如短信网关速度不好),那么主流程的时间会加长很多,用户肯定不希望点击支付过好几分钟才看到结果。那么我们只需要通知短信系统“我们支付成功了”,不一定非要等待它处理完成。
(2)最终一致性
主要是用记录和补偿的方式来处理;在做所有的不确定事情之前,先把事情记录下来,然后去做不确定的事,它的结果通常分为三种:成功,失败或者不确定;如果成功,我们就可以把记录的东西清理掉,对于失败和不确定,我们可以采用定时任务的方式把所有失败的事情重新做一遍直到成功为止。
保证了最终一致性,通过在队列中存放任务保证它最终一定会执行。
最终一致性指的是两个系统的状态保持一致,要么都成功,要么都失败。当然有个时间限制,理论上越快越好,但实际上在各种异常的情况下,可能会有一定延迟达到最终一致状态,但最后两个系统的状态是一样的。
业界有一些为“最终一致性”而生的消息队列,如Notify(阿里)、QMQ(去哪儿)等,其设计初衷,就是为了交易系统中的高可靠通知。
以一个银行的转账过程来理解最终一致性,转账的需求很简单,如果A系统扣钱成功,则B系统加钱一定成功。反之则一起回滚,像什么都没发生一样。
然而,这个过程中存在很多可能的意外:
- A扣钱成功,调用B加钱接口失败。
- A扣钱成功,调用B加钱接口虽然成功,但获取最终结果时网络异常引起超时。
- A扣钱成功,B加钱失败,A想回滚扣的钱,但A机器down机。
可见,想把这件看似简单的事真正做成,真的不那么容易。所有跨JVM的一致性问题,从技术的角度讲通用的解决方案是:
- 强一致性,分布式事务,但落地太难且成本太高。
- 最终一致性,主要是用“记录”和“补偿”的方式。在做所有的不确定的事情之前,先把事情记录下来,然后去做不确定的事情,结果可能是:成功、失败或是不确定,“不确定”(例如超时等)可以等价为失败。成功就可以把记录的东西清理掉了,对于失败和不确定,可以依靠定时任务等方式把所有失败的事情重新搞一遍,直到成功为止。
回到刚才的例子,系统在A扣钱成功的情况下,把要给B“通知”这件事记录在库里(为了保证最高的可靠性可以把通知B系统加钱和扣钱成功这两件事维护在一个本地事务里),通知成功则删除这条记录,通知失败或不确定则依靠定时任务补偿性地通知我们,直到我们把状态更新成正确的为止。
消息可能重复,注意消息的重复和幂等。
(3)广播
如果没有消息队列,每当一个新的业务接入时,我们都需要连接一个新接口;有了消息队列,我们只需要关系消息是否送到到消息队列,新接入的接口订阅相关的消息,自己去做处理就行了。
(4)错峰与流控
利用消息队列,转储两个系统的通信内容,并在下游系统有能力处理这些消息的时候再处理这些消息。试想上下游对于事情的处理能力是不同的。比如,Web前端每秒承受上千万的请求,并不是什么神奇的事情,只需要加多一点机器,再搭建一些LVS负载均衡设备和Nginx等即可。但数据库的处理能力却十分有限,即使使用SSD加分库分表,单机的处理能力仍然在万级。由于成本的考虑,我们不能奢求数据库的机器数量追上前端。
这种问题同样存在于系统和系统之间,如短信系统可能由于短板效应,速度卡在网关上(每秒几百次请求),跟前端的并发量不是一个数量级。但用户晚上个半分钟左右收到短信,一般是不会有太大问题的。如果没有消息队列,两个系统之间通过协商、滑动窗口等复杂的方案也不是说不能实现。但系统复杂性指数级增长,势必在上游或者下游做存储,并且要处理定时、拥塞等一系列问题。而且每当有处理能力有差距的时候,都需要单独开发一套逻辑来维护这套逻辑。所以,利用中间系统转储两个系统的通信内容,并在下游系统有能力处理这些消息的时候,再处理这些消息,是一套相对较通用的方式。
总结
总而言之,消息队列不是万能的。对于需要强事务保证而且延迟敏感的,RPC是优于消息队列的。
对于一些无关痛痒,或者对于别人非常重要但是对于自己不是那么关心的事情,可以利用消息队列去做。
支持最终一致性的消息队列,能够用来处理延迟不那么敏感的“分布式事务”场景,而且相对于笨重的分布式事务,可能是更优的处理方式。
当上下游系统处理能力存在差距的时候,利用消息队列做一个通用的“漏斗”。在下游有能力处理的时候,再进行分发。
如果下游有很多系统关心你的系统发出的通知的时候,果断地使用消息队列吧。
写在最后
如果觉得文章对你有点帮助,请微信搜索并关注「 冰河技术 」微信公众号,跟冰河学习高并发编程技术。
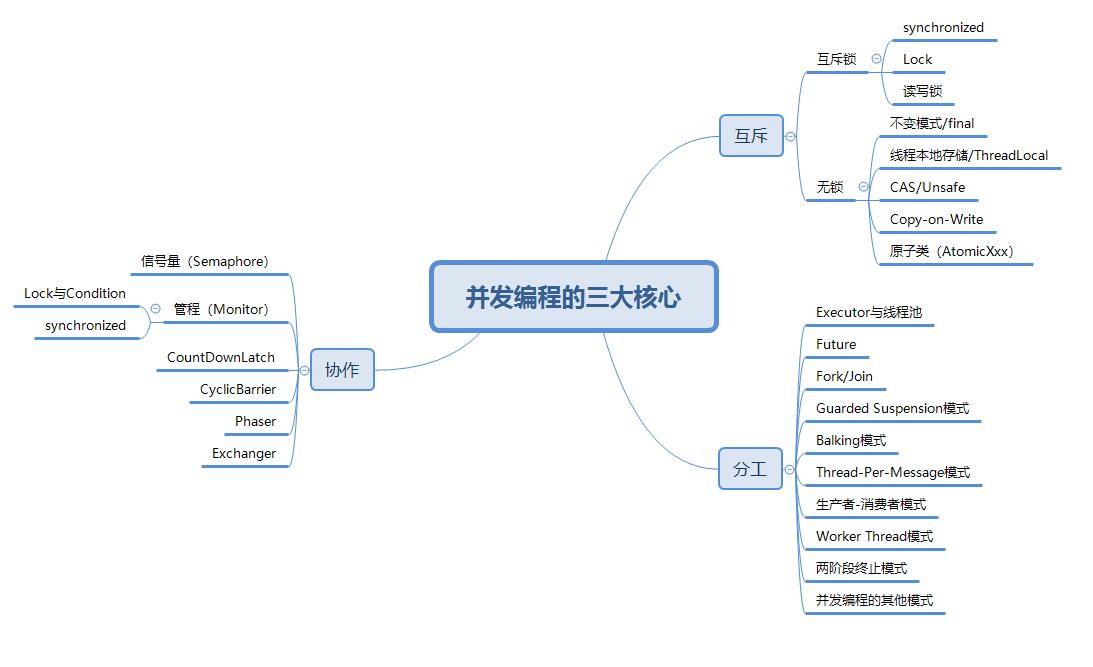
最后,附上并发编程需要掌握的核心技能知识图,祝大家在学习并发编程时,少走弯路。










【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
· 使用C#创建一个MCP客户端