NOIP2016 DAY1 T2天天爱跑步
题目描述
小c同学认为跑步非常有趣,于是决定制作一款叫做《天天爱跑步》的游戏。«天天爱跑步»是一个养成类游戏,需要玩家每天按时上线,完成打卡任务。
这个游戏的地图可以看作一一棵包含 nn个结点和 n-1n−1条边的树, 每条边连接两个结点,且任意两个结点存在一条路径互相可达。树上结点编号为从11到nn的连续正整数。
现在有mm个玩家,第ii个玩家的起点为 S_iSi,终点为 T_iTi 。每天打卡任务开始时,所有玩家在第00秒同时从自己的起点出发, 以每秒跑一条边的速度, 不间断地沿着最短路径向着自己的终点跑去, 跑到终点后该玩家就算完成了打卡任务。 (由于地图是一棵树, 所以每个人的路径是唯一的)
小C想知道游戏的活跃度, 所以在每个结点上都放置了一个观察员。 在结点jj的观察员会选择在第W_jWj秒观察玩家, 一个玩家能被这个观察员观察到当且仅当该玩家在第W_jWj秒也理到达了结点 jj 。 小C想知道每个观察员会观察到多少人?
注意: 我们认为一个玩家到达自己的终点后该玩家就会结束游戏, 他不能等待一 段时间后再被观察员观察到。 即对于把结点jj作为终点的玩家: 若他在第W_jWj秒前到达终点,则在结点jj的观察员不能观察到该玩家;若他正好在第W_jWj秒到达终点,则在结点jj的观察员可以观察到这个玩家。
输入输出格式
输入格式:
第一行有两个整数nn和mm 。其中nn代表树的结点数量, 同时也是观察员的数量, mm代表玩家的数量。
接下来 n- 1n−1行每行两个整数uu和 vv,表示结点 uu到结点 vv有一条边。
接下来一行 nn个整数,其中第jj个整数为W_jWj , 表示结点jj出现观察员的时间。
接下来 mm行,每行两个整数S_iSi,和T_iTi,表示一个玩家的起点和终点。
对于所有的数据,保证1\leq S_i,T_i\leq n, 0\leq W_j\leq n1≤Si,Ti≤n,0≤Wj≤n 。
输出格式:
输出1行 nn个整数,第jj个整数表示结点jj的观察员可以观察到多少人。
输入输出样例
说明
【样例1说明】
对于1号点,W_i=0Wi=0,故只有起点为1号点的玩家才会被观察到,所以玩家1和玩家2被观察到,共有2人被观察到。
对于2号点,没有玩家在第2秒时在此结点,共0人被观察到。
对于3号点,没有玩家在第5秒时在此结点,共0人被观察到。
对于4号点,玩家1被观察到,共1人被观察到。
对于5号点,玩家1被观察到,共1人被观察到。
对于6号点,玩家3被观察到,共1人被观察到。
【子任务】
每个测试点的数据规模及特点如下表所示。 提示: 数据范围的个位上的数字可以帮助判断是哪一种数据类型。
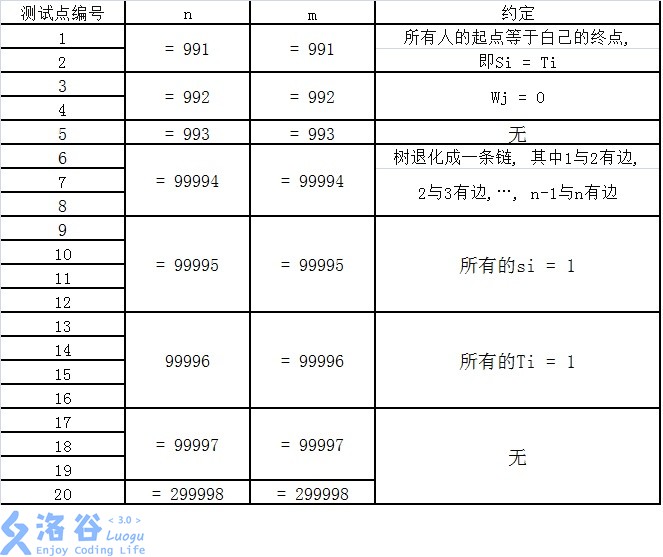
【提示】
如果你的程序需要用到较大的栈空问 (这通常意味着需要较深层数的递归), 请务必仔细阅读选手日录下的文本当rumung:/stact.p″, 以了解在最终评测时栈空问的限制与在当前工作环境下调整栈空问限制的方法。
在最终评测时,调用栈占用的空间大小不会有单独的限制,但在我们的工作
环境中默认会有 8 MB 的限制。 这可能会引起函数调用层数较多时, 程序发生
栈溢出崩溃。
我们可以使用一些方法修改调用栈的大小限制。 例如, 在终端中输入下列命
令 ulimit -s 1048576
此命令的意义是,将调用栈的大小限制修改为 1 GB。
例如,在选手目录建立如下 sample.cpp 或 sample.pas
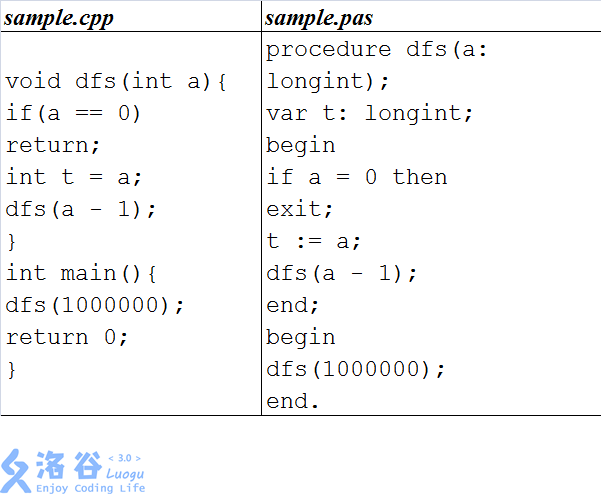
将上述源代码编译为可执行文件 sample 后,可以在终端中运行如下命令运
行该程序
./sample
如果在没有使用命令“ ulimit -s 1048576”的情况下运行该程序, sample
会因为栈溢出而崩溃; 如果使用了上述命令后运行该程序,该程序则不会崩溃。
特别地, 当你打开多个终端时, 它们并不会共享该命令, 你需要分别对它们
运行该命令。
请注意, 调用栈占用的空间会计入总空间占用中, 和程序其他部分占用的内
存共同受到内存限制。
----------------------------------------------------------------------------------------------------分割线
正解:
LCA+桶+差分(也不能说是差分但又和差分类似)
在说正解之前,先声明一些变量
V1[x] : 以x为LCA的路径的起点的集合。
Spn[x]: 以x为路径起点的路径条数。
V2[x]: 以x为终点的路径的起点集合。
V3[x]: 以x为LCA的路径的终点的集合。
另外,首先还要让读者摒弃一个观念。
正解并不是对一个个玩家进行操作。
而是先对全部玩家进行一些预处理,然后用两个类似的dfs函数对整棵树处理。
最后再做一些微调,就输出答案。
由于作者不知以什么样的方式引进接下来我们要用到的“桶”的概念,我们暂时先来考虑下面一个问题。
给定一条链,链上每个节点有k个贡献值,该贡献值只能向链首方向传播。
对于一个节点i,当且仅当某节点j与i节点的距离等于i节点的贡献值时,i节点对j节点将产生1的贡献。
给出链上节点的k个贡献值,最后输出每个节点能得到多少贡献。
如果无贡献应输出0。
对于这个问题,我们可以从链尾节点开始对链进行Dfs,每当访问一个点时,我们可以知道,当前点对哪些点是有贡献的。
我们设deep[i]为当前节点的深度,G[i]为i点的贡献值集合。
则对于i点来说,它能对深度为deep[i]+G[i][k]的点产生贡献。
那么我们用一个数组bucket[i]来维护这个贡献。
于题意我们能写出下面伪代码
Dfs(i)
For p in G[i] ---- ++bucket[deep[i] + p]
Dfs (i.children)
最后只要逆序输出bucket[i]就行了。
如果对上面的问题理解,那么对于桶这个概念,就能大概理解。
那么,接下来我们进入正题。
对于玩家在树上的路径(u,v)
我们可以对其进行拆分。
拆分成: u ---> LCA(u,v) 与 LCA(u,v) ---> v 两条路径。
对于这一步,因为我们在一开始已经说明是先对每个玩家进行预处理。
所以在这一步我们选择Tarjan版本的LCA会更好一些。因为时间复杂度会更少。
不过,用倍增求LCA对于本题来说也是不会卡的(作者亲测,时间最长的一个点是0.5s左右)。
我们先考虑 u ---> LCA(u,v) 这条路径,这是一条向“上”跑的路径。
对与这条路径上的点i来说,当且仅当deep[i]+w[i] = deep[u]时,u节点对i节点是有贡献的。
那么也就是说,只要符合deep[i]+w[i]的全部是玩家起点的点,就能对i点产生贡献。
所以有下列伪代码:
Dfs1(i)
·prev = bucket[deep[i]+w[i]]
·Dfs1(i.children)
·bucket[deep[i]] += spn[i]
·ans[i] += bucket[deep[i]+w[i]] - prev
·for k in V1[i] ---do --bucket[deep[k]]
其中
ans[i] 为i节点的最后答案。
Spn与V1数组在文章开头已经声明
Prev为刚访问i节点时bucket[deep[i]+w[i]]里的值。
在这解释一下伪代码中不好理解的最后两条语句。
对于倒数第二条语句,ans[i]加上的其实就是i的子树对i的贡献,为什么?
因为我们在处理好子树之后的,我们已经处理好了对i有影响的节点。
所以我们只要加上先后之间的桶差值就相当于统计了答案。
另外对于最后一条语句,其作用是删去桶中以i为LCA的路径的起点深度桶的值。
因为当我们遍历完i节点的孩子时,对于以i节点为LCA的路径来说。
这条路径上的信息对i的祖先节点是不会有影响的。
所以要将其删去。
在这不打算解释其他的伪代码,因为作者认为,在数组和变量给出的情况下。
读者如果自己能去进行推导与模拟,可能会对这个过程会有更深的了解。
另外,请再次记住文章开头需要读者摒弃的概念,这很重要。
在叙述完向上的路径后,我们再来考虑向下的路径,即LCA(u,v) --->v。
对于向下走的路径,我们也思考,在什么条件下,这条路径上的点会获得贡献呢?
很明显的,当 dis(u,v)-deep[v] = w[i]-deep[i] 等式成立的时候,这条路径将会对i点有贡献。
所以,类似的,我们就可以写出第二个Dfs伪代码。
Dfs2(i)
·prev = bucket[w[i]-deep[i]]
·Dfs2(i.children)
·for k in V2[i] --do ++bucket[dis(k,i)-deep[i]]
·ans[i] += bucket[w[i]-deep[i]] - prev
·for k in V3[i] --do --bucket[dis(i,k)-deep[k]]
其中
·dis(u,v)表示从u节点到v节点的距离
· V3与V2如文章开头所定义。
·关于两条for 语句:第一条是加上以i为终点的路径的贡献。
第二条与第一个Dfs中最后一条语句类似。
对于这道题来说,现在我们主要的思路已经完全讲完了。
但是,对于实现来说,需要注意以下几点。
·对于桶bucket来说,我们在计算的过程中其下标可能是负值,所以我们在操作桶时要将其下标右移 MAXN 即点数。
·如果一条路径的LCA能观察到这条路上的人,我们还需将该LCA去重。
条件是: if(deep[u] == deep[lca]+w[i])ans[lca]--;
下面贴代码,LCA用的是倍增,有问题留言。
#include<cstdio> #include<cstring> #include<cmath> #include<vector> #include<algorithm> #define N 300009 #define M 600009 using namespace std; int en,n,m; int w[N],spn[M],bucket[N+M],ans[N]; vector<int> v1[M],v2[M],v3[M]; struct nod{ int u,v,dis,lca; }p[N]; struct edge{ int e; edge *next; }*v[N],ed[M]; inline void add_edge(int s,int e){ en++; ed[en].next = v[s],v[s] = ed+en,v[s]->e =e; } int read(){ int x = 0; char ch = getchar(); while(ch < '0' || ch > '9')ch = getchar(); while(ch >= '0' && ch <= '9'){ x = x * 10 + ch - '0'; ch = getchar(); } return x; } int deep[N],f[N][25],dist[N]; bool use[N]; void dfs(int now,int dep){ use[now] = true; deep[now] = dep; for(int k = 1;k <= 22; k++){ int j = f[now][k-1]; f[now][k] = f[j][k-1]; } for(edge *e = v[now];e;e=e->next) if(!use[e->e]){ f[e->e][0] = now; dist[e->e] = dist[now]+1; dfs(e->e,dep+1); } use[now] = false; } inline int jump(int u,int step){ for(int k = 0; k <= 22; k++) if((step & (1<<k)))u = f[u][k]; return u; } inline int qlca(int u,int v){ if(deep[u] < deep[v])swap(u,v); u = jump(u,deep[u]-deep[v]); for(int k = 22; k >= 0; k--) if(f[u][k] != f[v][k])u = f[u][k],v = f[v][k]; return u == v ? u : f[u][0]; } void LCA(){ //关于LCA的组件 f[1][0] = 1; dfs(1,0); } inline void dfs1(int now){ use[now] = true; int prev = bucket[deep[now]+w[now]+N]; for(edge *e = v[now];e;e=e->next) if(!use[e->e])dfs1(e->e); bucket[deep[now]+N] += spn[now]; ans[now] += bucket[deep[now]+w[now]+N]-prev; int len = v1[now].size(); for(int k = 0; k < len;k++) --bucket[deep[v1[now][k]]+N]; use[now] = false; } inline void dfs2(int now){ use[now] = true; int prev = bucket[w[now]-deep[now]+N]; for(edge *e = v[now];e;e=e->next) if(!use[e->e])dfs2(e->e); int len = v2[now].size(); for(int k = 0; k < len; k++) ++bucket[v2[now][k]+N]; ans[now] += bucket[w[now]-deep[now]+N] - prev; len = v3[now].size(); for(int k = 0; k < len; k++) --bucket[v3[now][k]+N]; use[now] = false; } int main(){ n = read(),m = read(); for(int i = 1; i <= n-1; i++){ int u = read(), v = read(); add_edge(u,v); add_edge(v,u); } for(int i = 1; i <= n; i++)w[i] = read(); LCA(); for(int i = 1; i <= m; i++){ //预处理 int u = read(),v = read(); p[i].u = u; p[i].v = v; p[i].lca = qlca(u,v); p[i].dis = dist[u]+dist[v]-dist[p[i].lca]*2; spn[u]++; v1[p[i].lca].push_back(u); v2[v].push_back(p[i].dis-deep[p[i].v]); v3[p[i].lca].push_back(p[i].dis-deep[p[i].v]); } dfs1(1); //从下至上 dfs2(1); //从上至下 for(int i = 1; i <= m; i++) if(deep[p[i].u] == deep[p[i].lca]+w[p[i].lca]) ans[p[i].lca]--; for(int i = 1; i <= n; i++) printf("%d ",ans[i]); printf("\n"); return 0; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号