
python基础之模块二
六 logging模块
6.1 函数式简单配置
import logging #导入模块 logging.debug('debug message') #调试消息 logging.debug('info message') #导入消息 logging.debug('warning message') #警告消息 logging.error('error message') #错误消息 logging.critical('critical message') #严重信息
默认情况下python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级为CRITICAL > ERROR > WARNING > INFO > DEBUG),默认的日志格式为日志级别:Logger名称:用户输出消息


import logging #导入logging模块 logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s', # datefmt='%a, %d %b %Y %H:%M:%S', #%a代表周几,%d代表几号,%b代表月份,%Y代表年份,%H%代表小时,%M代表分钟,%S代表秒钟 filename='test.log', #在当前目录新建test.log filemode='w') #写模式 #time.asctime() 代表'Thu Apr 27 19:31:07 2017' #filename 文件名 logging.debug('debug message') logging.info('info message') logging.warning('warning message') logging.error('error message') logging.critical('critical message') # -------输出--------- # Thu, 27 Apr 2017 19:23:58 logging配置.py[line:30] DEBUG debug message # Thu, 27 Apr 2017 19:23:58 logging配置.py[line:31] INFO info message # Thu, 27 Apr 2017 19:23:58 logging配置.py[line:32] WARNING warning message # Thu, 27 Apr 2017 19:23:58 logging配置.py[line:33] ERROR error message # Thu, 27 Apr 2017 19:23:58 logging配置.py[line:34] CRITICAL critical message
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有: filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。 datefmt:指定日期时间格式。 level:设置rootlogger(后边会讲解具体概念)的日志级别 stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 format参数中可能用到的格式化串: %(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s用户输出的消息
6.2 logger对象配置
import logging logger = logging.getLogger() #创建一个logger对象 # 创建一个handler,用于写入日志文件 fh = logging.FileHandler('test.log') # 再创建一个handler,用于输出到控制台 ch = logging.StreamHandler() formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') #实例化formatter fh.setFormatter(formatter) ch.setFormatter(formatter) logger.addHandler(fh) #logger对象可以添加多个fh和ch对象 logger.addHandler(ch) logger.debug('logger debug message') logger.info('logger info message') logger.warning('logger warning message') logger.error('logger error message') logger.critical('logger critical message') # ----输出信息---- # 2017-04-27 19:52:08,784 - root - WARNING - logger warning message # 2017-04-27 19:52:08,785 - root - ERROR - logger error message # 2017-04-27 19:52:08,785 - root - CRITICAL - logger critical message
import logging def get_logger(): logger=logging.getLogger() fh=logging.FileHandler("logger2") sh=logging.StreamHandler() logger.setLevel(logging.DEBUG) #设置输出等级 fm = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s") logger.addHandler(fh) logger.addHandler(sh) fh.setFormatter(fm) sh.setFormatter(fm) return logger logger=get_logger() logger.debug('logger debug message') logger.info('logger info message') logger.warning('logger warning message') logger.error('logger error message') logger.critical('logger critical message') #文件里不能保存字典,只能是字符串
import sys,time for i in range(100): sys.stdout.write('#') time.sleep(0.3) sys.stdout.flush() ----输出100个- ####################################
logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供
了过滤日志信息的方法,Formatter指定日志显示格式。另外,可以通过:logger.setLevel(logging.Debug)设置级别
七 序列化模块
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
#---转换类型 d={"name":"yuan"} s=str(d) print(type(s)) d2=eval(s) print(d2[1]) with open("test") as f: for i in f : if type(eval(i.strip()))==dict: print(eval(i.strip())[1]) # 计算 print(eval("12*7+5-3")) 该程序会报错--- Traceback (most recent call last): <class 'str'> File "D:/Python/day34/序列化模块.py", line 25, in <module> print(d2[1]) KeyError: 1
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称为序列化,在python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。反过来,把变量内容从序列化的对象重新读到内存里称之为反序化,即unpicking。
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在WEB页面读取,非常方便。
JSON表示的对象就是标准的JavaScipt语言的一个子集,JSON和python内置的数据类型对应如下:
# json.dumps : dict转成str # json.loads:str转成dict #网络编程和框架都会用到json #pickl支持的数据类型更多 import json dict = {1:2,3:4,"55":"66"} #test json.dumps print(type(dict),dict) json_str=json.dumps(dict) print("json.dumps(dict) return:") print(type(json_str),json_str) #<class 'str'> {"1": 2, "3": 4, "55": "66"} #test json.loads print("\njson.loads(str) return") dict_2=json.loads(json_str) print(type(dict_2),dict_2) #<class 'dict'> {'1': 2, '3': 4, '55': '66'}
import json i=10 s='hello' t=(1,4,6) l=[3,5,7] d={'name':"yuan"} json_str1=json.dumps(i) json_str2=json.dumps(s) json_str3=json.dumps(t) json_str4=json.dumps(l) json_str5=json.dumps(d) print(json_str1) #10 print(json_str2) #'"hello"' #json格式输出双引号,不能输出单引号 print(json_str3) #[1, 4, 6] print(json_str4) #[3, 5, 7] print(json_str5) #{"name": "yuan"}
# import json # # d={"name":"egon"} # # s = json.dumps(d) #将字典转为json字符串 # print(type(s)) # print(s) #----------------------------序列化 import json dic={'name':'alvin','age':23,'sex':'male'} print(type(dic))#<class 'dict'> data=json.dumps(dic) print("type",type(data))#<class 'str'> print("data",data) f=open('序列化对象','w') f.write(data) #-------------------等价于json.dump(dic,f) f.close() #-----------------------------反序列化<br> import json f=open('序列化对象') new_data=json.loads(f.read())# 等价于data=json.load(f) print(type(new_data)) #json.dump(d,f)
re模块(* * * * *)
元字符 . 通配符\n ^ 以什么开始的匹配 $ 以什么结尾的匹配 * 重复前一个条件,最少0个,[0,+∞] + 重复前一个条件,最少1个,[1,+∞] ? 重复前面的条件,最少0个,最多1个[0,1] {x} 重复前面的x次,{x,y}最少x次,最多y-1次,{x,}最少x次,最多不限 | 或的意思 \ 反斜杠后跟元字符去除特殊功能 \.就是匹配. \+ 匹配+ \\\\ 匹配\ 等于r"\\" r就是代表原生字符,不需要python转义就传入re 反斜杠后跟普通字符实现特殊功能 \d 代表数字0-9 [0-9] \D 代表非数字0-9 [^0-9] \s代表匹配空白字符[\t\n\r\f\v] \S代表非空白字符[^\t\n\r\f\v] \w代表匹配非空白字符[a-zA-Z0-9] \W代表非字母和非数字[^a-zA-Z0-9] \d代表匹配一个特殊边界,如匹配单词 字符集 []代表字符集 [a,b,c]匹配a或者b或c中任意一个 [a-z]匹配a到z中的任意小型字母[A-Za-z0-9] -代表什么到什么之间 ^取反的意思,非 \将特殊符号转换成普通字符 注:字符集内取消元字符的特殊功能(\ ^ -除外) [a-z,*]匹配a-z的字母或*号,还有,号 [^a-z]匹配非a-z的字母的所有 分组 ()代表分组 (1|2)代表1或2的字符 (?P<id>\w)匹配一个字母或数字 这个组的名称是ID (:?\d+取消分组的权限) 正则表达式方法 findall(规则,字符串) 寻找所有满足规则的元素 search(规则,字符串) 寻找第一个满足规则的元素并返回一个对象,配合group()显示内容 match(规则,字符串) 只在开始匹配规则,满足返回对象,不满足返回None split(规则,字符串) 通过规则分割字符串 注:先匹配第一个,并分割,再从第一个分割后匹配第二个,并分割 sub(规则,新内容,字符串) 通过规则匹配字符串内容,并把匹配结果替换成新内容 compile(规则) 将规则封装一个对象中,下次可以直接用对象查询,不需要输规则 finditer(规则,字符串) 将查找的结果生成一个迭代器,使用next方法取,每个内容用group再取数
# Auther:bing #元字符符号包括:" . ^ $ * + ? {} [] () \ |" #1、元字符之 . ^ $ * + ? {} import re # . ret = re.findall("a...n","hello administrator") #"."表示所有除换行符(\n)之外的任何单个字符 print(ret) #['admin'] # ^ ret = re.findall('^h...o','hello administrator') #匹配输入字符串的开始位置,就是以h开头 print(ret) #['hello'] # $ ret = re.findall('r...r$','hello administrator') #匹配输入字符串的结束位置,也就是以r结尾的 print(ret) #['rator'] # * ret = re.findall('abc*','abcccccc') #匹配*前面的字母0次或者多次, *代表[0,+oo] print(ret) # + ret = re.findall('abc+','abcccccc') # + 代表[1,+oo] print(ret) # ? ret = re.findall('abc?','abcccccc') #?代表[0,1] print(ret) #{} ret = re.findall('abc{2}','abcccccc') #代表{}大括号之外c的个数 print(ret) ret = re.findall('abc{1,6}','abcccccc')#代表1-6之间的范围 print(ret) #注意:前面的 * , + , ?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成非贪婪匹配(惰性匹配)。 ret = re.findall('abc+?','abcccccc') #非贪婪匹配 print(ret) #['abc'] ret = re.findall('abc*?','abcccccc') #非贪婪匹配 print(ret) #['ab'] *代表匹配大于等于0个 ,加上?匹配0个 ret = re.findall('abc+?','abcccccc') #非贪婪匹配 print(ret) #['abc'] +代表匹配大于等于1个,加上? 匹配1个 #2、元字符之字符集[]:(起一个或者的意思),注意: . , * , + 等元字符都是普通符号, _ ^ \这几个有特殊意义 ret = re.findall('a[bc]d','acd') #带[]只能匹配1个 print(ret) #['acd'] ret = re.findall('a[bc]d','abd') #带[]只能匹配1个 print(ret) #['abd'] ret = re.findall('a[bc]d','abcd') #带[]只能匹配1个 print(ret) #[] 返回空列表 ret = re.findall('[a-z]','hello') #匹配a-z的所有字母 print(ret) #['h', 'e', 'l', 'l', 'o'] ret = re.findall('[.*+?]','a.b*c+d?e') #在[] ' . * + ? ' 里没有特殊意义了,就是普通的字符 print(ret) #['.', '*', '+', '?'] #在字符集里有功能的符号: -(定义一个范围) ^(在[]列表里取反) \(转义) ret = re.findall('[^ab]','199ashhsbm998') #取出除ab之外的所有字符 print(ret) #['1', '9', '9', 's', 'h', 'h', 's', 'm', '9', '9', '8'] ret = re.findall('[\d]','199ashhsbm998') #取出[0-9]之间的数字 print(ret) #['1', '9', '9', '9', '9', '8'] # 3、元字符之转义符 \: # 反斜杠后边跟元字符去除特殊功能,比如\. 此时.就没有特殊意义了,就是一普通字符。 # 反斜杠后边跟普通字符实现特殊功能,详见下文: # \d 匹配任何十进制数;它相当于类[0-9] # \D匹配任何非数字字符;它相当于类[^0-9] # \s 匹配任何空白字符,它相当于类[\t\n\r\f\v] # \S匹配任何非空白字符,它相当于类[^\t\n\r\f\v] # \w 匹配任何字母数字字符,它相当于类[a-zA-Z0-9] # \W 匹配任何非字母数字字符,它相当于类[^a-zA-Z0-9] # \b 匹配一个特殊字符边界,比如空格, & , # 等 ret = re.findall('I\b','I am LIST') #此时结果为空,因为\b对应ASCII有特殊含义 print(ret) #[] ret = re.findall(r'I\b','I am LIST') # r表示原生字符,使字符串里的\b没有特殊意义了 print(ret) #['I'] ret = re.findall('I\\b','I am LIST') #在\b前加一个\转义,此时\b就没有特殊意义了 print(ret) #['I'] # ret = re.findall('a\l','a\lmn') #会报错 # ret = re.findall('a\\l','a\lmn') #会报错 ret = re.findall('a\\\l','a\lmn') print(ret) #['a\\l'] ret = re.findall('a\\\\l','a\lmn') #此时为什么3个反斜杠(\\\)或者4个反斜杠(\\\\)就不会报错么,请看下文详解 print(ret) #['a\\l'] #因为我们前文也介绍过,正则表达式是内嵌在python里的一种专业的编程语言, #因为(\)是由特殊含义的元字符,so,我们就应该给它转义一下,变成(\\) # 我们要知道,python解释器要先识别,然后把识别结果再交给正则表达式来处理 # 所以就应该有(\\\\)来进行转义,在这里其实三个转义符也是可以的,怎么理解呢 # 两个转义符(\\)经过python识别后变成(\),这个(\)加上后面的(\),就成了两个(\\), # 这时,正则表达式就能识别经过转义后的普通\字符了。 ret = re.findall(r"a\\l",r"a\llmn") #在pattern(匹配选项)和string要匹配的字符串前面加上r使python识别为原生字符 print(ret) #['a\\l'] 然后两个\\交给正则表达式处理,不加r都会报错 # 一些有着特殊意义的字符,见图中的一些转义字符 ret = re.findall('\\blike','What did she look like? SHelikes baseball') #加上\b之后就能匹配第一个like了 print(ret) #['like'] ret = re.findall(r'\\book',r'bing\book') #因为\b有特殊的意义,跟上文一样 print(ret) #['\\book'],#这里里面的两个(\\),是因为正则表达式要传给Python,#自动加上了(\)了,我们可只看成['\book'] #元字符之分组() #普通分组 ret = re.findall(r'(ad)+','add') #在一个连续的字符串里匹配到括号里的内容后,就停止匹配了,也就是只匹配分组()里面的 print(ret)#['ad'] ret = re.findall('(ad)+min','administrator') #会优先显示分组,即括号里的内容 print(ret) #['ad'] ret = re.findall('(ad)+min','adm admin administrator') #非连续的字符串里匹配到内容后,优先显示分组 print(ret) #['ad', 'ad'] ret = re.findall('(?:ad)+min','adm admin administrator adadmin') #括号里前面加上?:,代表取消分组的优先级,就没有分组的特殊意义了 print(ret) #['admin', 'admin', 'adadmin'] #4.2、命名分组: ret = re.search(r"(?P<name>\w+):(?P<age>\d+)","bing:18") #对自己想取的部分进行命名操作 print(ret.group("name")) #输出bing 通过自己设置的组名,得到对象的值 print(ret.group("age")) #输出18 通过自己设置的组名,得到对应的值 #5、元字符之 | :或的意思 ret = re.findall("a|b","a") #a或者b符合条件,这里是a print(ret) ret = re.findall("a|b","b") #a或者b符合条件,这里是b print(ret) ret = re.findall("a|b","ab") #a或者b都符合条件,这里是'a'和'b'组成的列表 print(ret) ret = re.search("\D+|\d+","123456") #数字字符与非数字字符,这里是数字,+号代表大于1个 print(ret.group()) #123456 ret = re.findall("\D+|\d+","123456") print(ret) #['123456'] ret = re.search("\D+|\d+","admin") #数字与非数字字符,这里是非数字 print(ret.group()) #admin ret = re.search("\D+|\d+","admin123") #数字与非数字字符,这里是非数字 print(ret.group()) #admin, | 是或者的意思,即在前面的条件里,选一个。 # 三、re模块下的常用方法 #我们一起来总结一下都有哪些方法: #1、findall:匹配所有满足条件的结果 ret = re.findall("adm","admin") #返回所有满足匹配条件的结果,放在一个列表里 print(ret) #['adm'] #2、 search:只匹配第一个结果 ret= re.search("adm","admin")#函数会在字符串内查找模式匹配,直到找到第一个匹配然后返回一个包含匹配信息的对象 print(ret.group()) #adm 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则报错 #3、match:只匹配最开始位置 ret = re.match("admin","administrator")#同search,不过只在字符串开始处进行匹配 print(ret.group()) #admin #若开始处,不是匹配的内容,则报错 #4、split:分割 ret = re.split("a","bingaalexaegon") #按"a"分割,得到一个列表 print(ret) #['bing', '', 'lex', 'egon'] ret = re.split("[ab]","a34b56") #先按"a"分割,得到['', '34b56'],再对'', '34b56'进行分割 print(ret)#['', '34', '56'] #分别按"b"分割,""空字符串没有b,不能分割,再对34b56分割成"34"和"56" #5、sub、subn:替换 sub(pattern, repl, string, count=0, flags=0) subn(pattern, repl, string, count=0, flags=0) ret = re.sub("B","A","bing:B egon:B") #替换,第一个是定位信息,第二个是修改内容 print(ret) #bing:A egon:A ret = re.sub("B","A","bing:B egon:B",1) #这里的1是传给count的值,表示替换的次数 print(ret) #bing:A egon:B ret = re.subn("B","A","bing:B egon:B alex:B") #跟sub比,它返回的是一个替换后的值变成元组的形式 print(ret) #('bing:A egon:A alex:A', 3) #元组后面会显示统计替换的次数 #6、complile:编译方法 obj = re.compile("\d+") ret = obj.findall("123admin456789") #相当于re.findall("\d+","123admin456789") print(ret) #['123', '456789'] #7、iterator ret = re.finditer("\d","jsadh999msn88qq") #把所有的数字提取出来组成一个迭代器 print(ret) #<callable_iterator object at 0x000000DA1B8E0F98> 可调用的迭代器 print(next(ret).group()) #9 print(next(ret).group()) #9 print(next(ret).group()) #9 print(next(ret).group()) #8 print(next(ret).group()) #8 # 我们需要注意一下 ret = re.findall("www.(baidu|oldboy).com","www.oldboy.com") print(ret)#['oldboy'] 因为findall会优先把匹配结果放在组里将内容返回,如果想要匹配完整结果,取消权限即可 ret = re.findall("www.(?:baidu|oldboy).com","www.oldboy.com") #加上了?:取消了分组的权限 print(ret)#['www.oldboy.com']
一些有着特殊意义的字符,见图中的一些转义字符
![]()
 python解释器与正则中反斜杠理解
python解释器与正则中反斜杠理解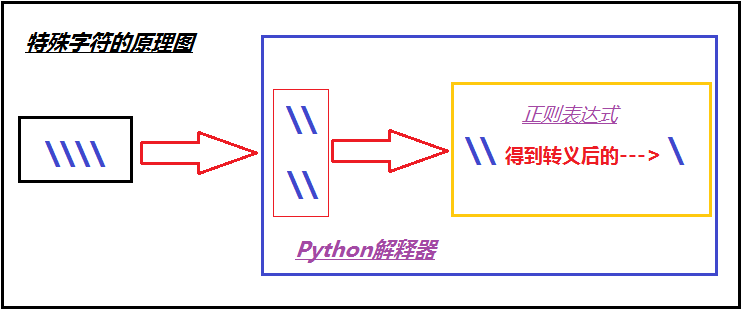
就其本质而言,正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
字符匹配(普通字符,元字符):
1 普通字符:大多数字符和字母都会和自身匹配
>>> re.findall('alvin','yuanaleSxalexwupeiqi')
['alvin']
2 元字符:. ^ $ * + ? { } [ ] | ( ) \
元字符之. ^ $ * + ? { }
import re ret = re.findall('a..in','helloalvin') print(ret) #['alvin'] ret = re.findall('^a...n','alvinhelloawwwn') #字符串内'^'代表以什么开头 print(ret) #['alvin'] ret = re.findall('a...n$','alvinhelloawwwn') #'$代表以什么结尾' print(ret) #['awwwn'] ret = re.findall('abc*','abcccc') #贪婪匹配[0,+oo] print(ret) #['abcccc'] ret = re.findall('abc+','abccccc') #贪婪匹配[0,+oo] print(ret) #['abccccc'] ret = re.findall('abc?','abccccccc') #[0,1] print(ret) #['abc'] ret = re.findall('abc{1,4}','abccc') #1<= x <=4 print(ret) #['abccc'] 贪婪匹配 # 注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配 ret = re.findall('abc*?','abccccccc') print(ret) #['ab']
元字符之字符集[]:
import re ret = re.findall('a[bc]d','acd') print(ret) #['acd'] ret = re.findall('[a-z]','acd') print(ret) #['a', 'c', 'd'] ret = re.findall('[.*+]','a.cd+') print(ret) #['.', '+'] #在字符集里有功能的符号: - ^ \ ret = re.findall('[1-9]','45dha3') print(ret) #['4', '5', '3'] ret = re.findall('[^ab]','45bdha3') #在[^]的意思是取反 print(ret) #['4', '5', 'd', 'h', '3'] ret = re.findall('[\d]','45bdha3') print(ret) #['4', '5', '3']
元字符之转义符\
反斜杠后边跟元字符去除特殊功能,比如\.
反斜杠后边跟普通字符实现特殊功能,比如\d
\d 匹配任何十进制数;它相当于类 [0-9]。
\D 匹配任何非数字字符;它相当于类 [^0-9]。
\s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。
\S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。
\w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。
\W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]
\b 匹配一个特殊字符边界,比如空格 ,&,#等
现在我们聊一聊\,先看下面两个匹配:
import re #-----------------------------eg1: ret=re.findall(r'c\\l','abc\le') print(ret)#[] ret = re.findall('c\\\\l','abc\le') print(ret) #['c\\l'] ret = re.findall(r'c\\l','abc\le') print(ret) #['c\\l'] #-----------------------------eg2: #之所以选择\b是因为\b在ASCII表中是有意义的 m = re.findall('\bblow','blow') print(m) #[] m = re.findall(r'\bblow','blow') print(m) #['blow']

元字符之分组()
import re m = re.findall(r'(ad)+','add') print(m) #['ad'] ret = re.search('(?P<id>\d{2})/(?P<name>\w{3})','23/com') print(ret.group()) #23/com print(ret.group('id')) #23
元字符之|
ret = re.search('(ab)|\d','rabhdg8sd') print(ret.group()) #ab
re模块下的常用方法
#我们一起来总结一下都有哪些方法: #1、findall:匹配所有满足条件的结果 ret = re.findall("adm","admin") #返回所有满足匹配条件的结果,放在一个列表里 print(ret) #['adm'] #2、 search:只匹配第一个结果 ret= re.search("adm","admin")#函数会在字符串内查找模式匹配,直到找到第一个匹配然后返回一个包含匹配信息的对象 print(ret.group()) #adm 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则报错 #3、match:只匹配最开始位置 ret = re.match("admin","administrator")#同search,不过只在字符串开始处进行匹配 print(ret.group()) #admin #若开始处,不是匹配的内容,则报错 #4、split:分割 ret = re.split("a","bingaalexaegon") #按"a"分割,得到一个列表 print(ret) #['bing', '', 'lex', 'egon'] ret = re.split("[ab]","a34b56") #先按"a"分割,得到['', '34b56'],再对'', '34b56'进行分割 print(ret)#['', '34', '56'] #分别按"b"分割,""空字符串没有b,不能分割,再对34b56分割成"34"和"56" #5、sub、subn:替换 sub(pattern, repl, string, count=0, flags=0) subn(pattern, repl, string, count=0, flags=0) ret = re.sub("B","A","bing:B egon:B") #替换,第一个是定位信息,第二个是修改内容 print(ret) #bing:A egon:A ret = re.sub("B","A","bing:B egon:B",1) #这里的1是传给count的值,表示替换的次数 print(ret) #bing:A egon:B ret = re.subn("B","A","bing:B egon:B alex:B") #跟sub比,它返回的是一个替换后的值变成元组的形式 print(ret) #('bing:A egon:A alex:A', 3) #元组后面会显示统计替换的次数 #6、complile:编译方法 obj = re.compile("\d+") ret = obj.findall("123admin456789") #相当于re.findall("\d+","123admin456789") print(ret) #['123', '456789'] #7、iterator ret = re.finditer("\d","jsadh999msn88qq") #把所有的数字提取出来组成一个迭代器 print(ret) #<callable_iterator object at 0x000000DA1B8E0F98> 可调用的迭代器 print(next(ret).group()) #9 print(next(ret).group()) #9 print(next(ret).group()) #9 print(next(ret).group()) #8 print(next(ret).group()) #8 # 我们需要注意一下 ret = re.findall("www.(baidu|oldboy).com","www.oldboy.com") print(ret)#['oldboy'] 因为findall会优先把匹配结果放在组里将内容返回,如果想要匹配完整结果,取消权限即可 ret = re.findall("www.(?:baidu|oldboy).com","www.oldboy.com") #加上了?:取消了分组的权限 print(ret)#['www.oldboy.com']
posted on 2017-04-27 20:29 bigdata_devops 阅读(261) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号