概述
Profiler是一个时间统计程序,他通过在程序中埋点,将埋点时间记录入线程变量中以实现革离,最后dump出结果,得出埋点时间树。
Profiler常用方法
- Start:
当前线程埋点计时的开始,标识当前埋点的开始时间,每个埋点产生一个Entry,被压入线程变量中的栈中,当start方法被调用时,就是一个时间点栈的开始,如果start方法被重复调用,则覆盖前面被放入线程变量的栈,每个线程只允许一个栈的存在。该方法的参数标识该Entry信息。 - Enter:
向线程变量中的栈压入当前埋点信息,标识当前埋点的开始时间,如果此线程此前未调用start方法,则此方法调用不执行任何操作。 - Release:
结束栈里当前Entry时间,打上结束时间标识。 - GetDuration:
获取耗费的总时间,是从start到当前的中时间,如果start的Entry没有被release,则getDuration的结果为-1,所以只有栈的最底层的Entry被release后getDuration得到的数值才有意义。 - Dump:
当线程内的所:有Entry被release后,通过dump的到整个线程内埋点的时间树。 - Reset:
清除当前线程内的计数器栈。当一次调用完成后,在dump出时间树后应该将其清除。
Profiler埋点方式
在消息中心项目中主要采用两种埋点方式,一种是业务程序中直接埋入Profiler代码,另一种是利用Spring方法拦截器,将Profiler代码埋入拦截器中。两种方法各有优劣,所以在项目中两种方式综合应用,相互补充。
直接埋点
优点是在业务代码中埋点可以设置任意粒度,能够显示程序中微小范围内的时间变化。缺点是Profiler耦合进了业务代码,埋点分布于业务程序的各处,不便于阅读和修改,同时由于其要带try{}finally{}块,将业务代码分割的支离破碎,造成业务代码的断层。用例如下:
public void sendWithChannels(final MessageTaskDO messageTask,
final MessageTypeDO messageType,final UserInfoDO userInfo,
final int chs) throws MessageException{
int channelInt = chs;
UserInfoFuture userInfoFuture = null;
Profiler.start("TagTask isFinish");
try{
if (messageTask.getTaskPreStatus() == MessageTaskDO.FALURE_NOTSEND_RETRY
&& messageStatusDAO.isFinish(messageTask.getTaskID(), userInfo.getTargetID())){
return;
}
Profiler.enter("Task Filter");
try{
channelInt = getChannelsAfterFilter(messageType, userInfo, channelInt);
}finally{
Profiler.release();
}
Profiler.enter("Task Fill UserInfo");
try{
channelInt = getChannelsAfterUInfoFilled(userInfo, userInfoFuture, channelInt);
}finally{
Profiler.release();
}
List<Channel> channels = null;
Map<Channel, Integer> channelTemplateId = null;
Map<String, String> mapContext = null;
Profiler.enter("Task Fill Context");
try{
channels = Channel.parseChannels(channelInt);
}finally{
Profiler.release();
}
Profiler.enter("Task Send with Channels");
try{
for (final Channel channel : channels){
final boolean couldSend = true;
String sendToAddress = "";
if (couldSend){
Profiler.enter("send of Channel choose");
if (channel == Channel.WANGWANG){
sendToAddress = userInfo.getUserNick();
}else{
logger.error("MessageTask:" + messageTask.getTaskID() + " is not channel");
continue;
}
final Integer templetId = channelTemplateId.get(channel);
final String replyTo = "taobao@taobao.com";
Profiler.release();
}
}
}finally{
Profiler.release();
}
}finally{
Profiler.release();
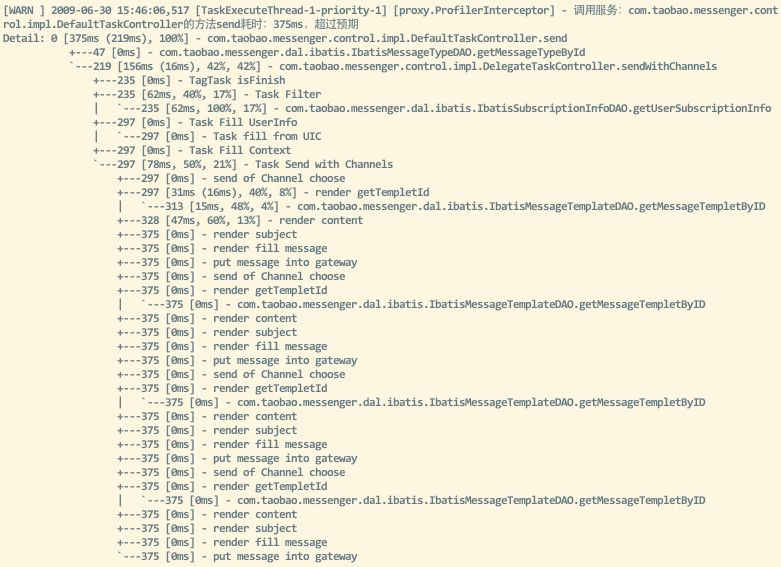
final String detail = Profiler.dump("Detail: ", " ");
logger.warn(String.format("调用服务:%s的方法%s耗时:%dms,超过预期\n%s\n",
new Object[] {invocation.getThis().getClass().getName(),
invocation.getMethod().getName(),duration, detail }));
Profiler.reset();
}
}
通过上面代码可以看出,直接埋点虽然可以控制到很小的粒度,但埋点代码混杂于业务代码,将业务代码分割的支离破碎,是一种很不优雅的用法。
Spring拦截器埋点
优点是和业务代码解耦,要统计哪个方法的耗时只需要修改拦截器配置文件和拦截器中的埋点代码即可,和业务代码完全无关。缺点是埋点粒度只能到方法这个级别,方法内部的耗时统计就无法完成,同时只能拦截Spring Bean的方法,Bean内部间方法调用无法拦截,只能拦截外部调用Bean的方法。用例如下:
xml配置如下:
<!-- 自动代理所有的advisor -->
<bean id="autoProxyCreator" class="org.springframework.aop.framework.autoproxy.DefaultAdvisorAutoProxyCreator">
<property name="proxyTargetClass" value="true"/>
</bean>
<bean id="interceptorAdvisor" class="org.springframework.aop.support.RegexpMethodPointcutAdvisor">
<!-- 业务实现方法名匹配 -->
<property name="patterns">
<list>
<value>com.taobao.messenger.dal.*DAO.*</value>
<value>com.taobao.messenger.service.*</value>
</list>
</property>
<property name="advice">
<ref bean="interceptorAdvice" />
</property>
</bean>
<bean id="interceptorAdvice" class="com.taobao.messenger.proxy.ProfilerInterceptor"></bean>
java代码如下:
public Object invoke(final MethodInvocation invocation) throws Throwable {
final String key = invocation.getThis().getClass().getName()
+MessageConstants.DOT_SPLIT+invocation.getMethod().getName();
boolean resetFlag = false;
if(Profiler.getEntry() == null || (key.equals(TagTaskDispatcher.class.getName()
+MessageConstants.DOT_SPLIT+"sendMessage"))){
Profiler.start(key);
resetFlag = true;
}else{
Profiler.enter(key);
}
Object result = null;
try{
result = invocation.proceed();
} finally{
Profiler.release();
if(resetFlag || (key.equals(TagTaskDispatcher.class.getName()
+MessageConstants.DOT_SPLIT+"sendMessage"))){
try{if(threshold.containsKey(key)){
final Long duration = Profiler.getDuration();
if(duration>threshold.get(key)){
final String detail = Profiler.dump("Detail: ", " ");
logger.warn(String.format("调用服务:%s的方法%s耗时:%dms,超过预期\n%s\n",
new Object[] {
invocation.getThis().getClass().getName(),
invocation.getMethod().getName(),duration, detail }));
}
}
} finally{
Profiler.reset();
}}
}
return result;
}
通过上面代码可以看出,Profiler代码和业务代码从表象上看完全无关,从结构上和管理上都比较不错。
Profiler使用中的问题
- 【埋点方式的问题】:
通过上面埋点方式的分析,两种方式都有自己的优缺点,所以我们采用两种方式综合使用的方针,以Spring拦截器埋点方式为主,在需要被埋点的重要关节,程序实现的同时尽量将要监控的点放到不通的类里面,被监控的方法粒度尽可能的小,便于配置Spring进行监控。有些相互间关系比较紧密的不容易分割的点和在debug阶段需要临时监控的点使用直接埋点的方式,进行细粒度的监控,在系统稳定后注释掉临时监控点,保留仍需后续监控的直接埋点,但这种埋点要尽可能的少。 - 【内存泄露的问题】:
一定要将Profiler.start()方法和Profiler.reset()方法写入try{}finally{}块中,确保Profiler.reset()方法一定被调用来释放资源,否则如果中间出现异常跳过资源释放操作将引发内存泄露。同理Profiler.release()方法也应该写入finally块里,跳过虽然不会引发内存泄露,但会导致埋点时间计算错误。这点用Spring拦截器比较好控制,只要控制住出口和入口就行。 - 【时间树输出的问题】:
在多线程环境下一般在在线程的出口输出时间树即可,在线程中间(非start方法对应的栈)不要用getDuration获取总耗时,此时只能得到-1,因为getDuration是求最底层Entry的耗时的,中间状态通常最底层的Entry没被release,没办法获得耗时。 - 【方法对】:
Profiler.start() 和 Profiler.reset()要成对出现,reset()及时释放内存,防止内存泄露;
Profiler.enter() 和 Profiler.release() 要成对出现,release()是时间段结束埋点,内存中打上此enter结束的时间点。
使用Profile后产生的结果树如下: