
后端存储技术研究
一、NewSQL
兼容Old SQL和No SQL特性
Old SQL:数据库支持ACID和强大SQL查询能力
No SQL:Redis等KV存储,性能超过数据库10倍级别,容易组成分布式集群,支持水平扩展、高可靠、高可用
方案:
Google:Cloud Spanne
国产:OceanBase、CockroachDB(小强数据库)
腾讯:TiDB
CockroachDB架构
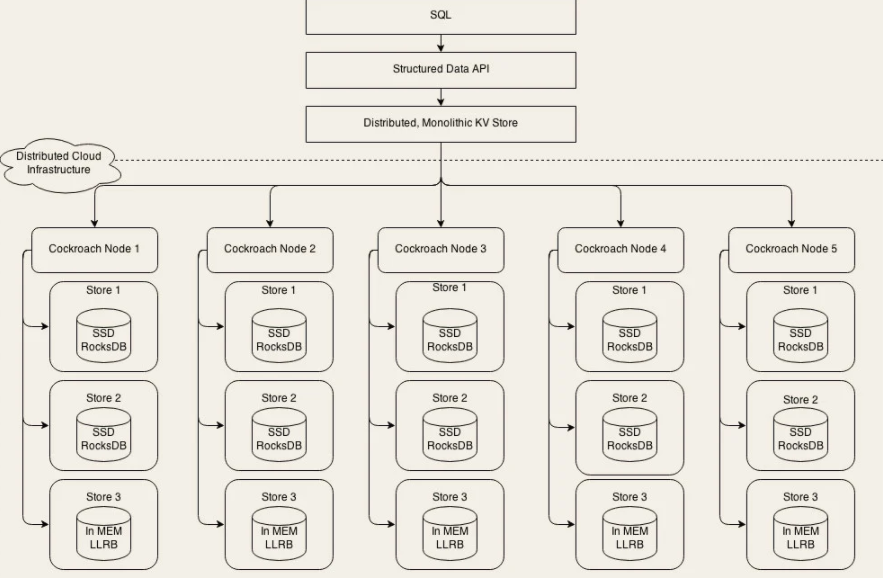
Distributed, Monolithic KV Store:分布式 KV 存储系统
分片算法:范围分片, 采用Raft一致性协议实现每个分片的高可靠、高可用和强一致
Raft协议:复制状态机理论上,实现了集群自我监控和自我选举来解决高可用的问题
用复制状态机来解决多个副本数据一致的问题,保证日志复制到半数以上节点才给客户端返回成功。并且,引入了主从心跳机制,当主节点故障时,其它节点能主动发起选举,选出新的主节点。通过复制状态机、心跳和选举机制,来保证集群数据的高可用、高可靠和强一致
Gossip传播协议: 元数据直接分布在所有的存储节点上
二、RocksDB
1、RocksDB是什么?有谁使用它
RocksDB:不丢数据高性能KV存储
Myrocks:RocksDB作为存储引擎,取代InnoDB 存储引擎
Flink 的 State 就是一个 KV 的存储,它使用的也是 RocksDB
2、读写性能分析 20W次/s , 秒杀MySQL 1W次/s
|
KV存储产品 |
性能 |
|
Redis |
内存数据库, 随机读写性能大约在 50 万次 / 秒左右 |
|
RocksDB |
数据库存储引擎, 随机读写性能大约在 20 万次 / 秒左右 正常正常MySQL 1W次/s ,内存和磁盘差1个数量级 |
结论:RocksDB和Redis在读写性能上达到差不多量级
3、如此快的读写性能实现原理是什么?
RocksDB存储结构(内存+磁盘):内存加快读写,磁盘保证数据可靠存储
加快读取:读内存,写磁盘性能如此高实现原理是什么?
|
写存储结构 |
分析 |
原因 |
|
B+树、哈希表 |
写入固定节点或哈希槽位 |
随机写:磁盘跳来跳去写 |
|
RocksDB |
LSM-Tree特殊数据结构 |
顺序写 |
LSM-Tree特殊数据结构
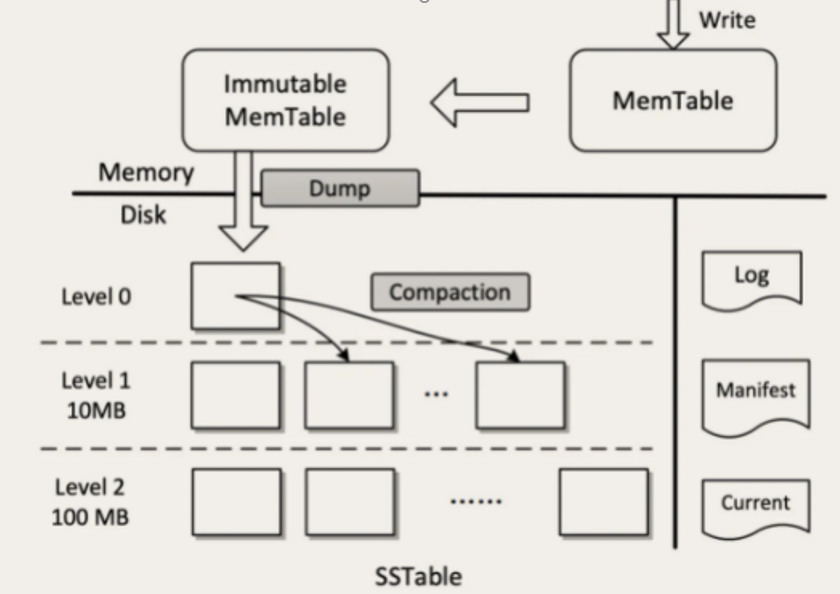
包含 WAL(Write Ahead Log)、跳表(SkipList)和一个分层的有序表(SSTable,Sorted String Table)
写原理
1、 先写WAL Log日志 =》保证数据可靠性,出现问题可恢复
顺序写磁盘性能很好,日志作用用于故障恢复,一旦系统宕机,可以把内存中还未写入磁盘的数据恢复出来 =》复制状态机理论,满足数据可靠性
2、 写入内存MemTable(32MB), 写入成功即返回 =》 写入内存即返回,最快性能
MemTable: 按照 Key 组织的跳表(SkipList)
注意点:直接写入MemTable,不判断是否存在
3、 MemTable 32MB满后,转换成 Immutable MemTable(只读不允许写)=》数据满后直接转换,再创建新内存空间
再创建新的MemTable
4、 后台线程把Immutable MemTable不停复制到磁盘文件,然后释放内存空间 =》 后台线程将内存数据(有序表)Flush到磁盘
每个Immutable MemTable对应1个磁盘文件。MemTable 的数据结构跳表是有序表,写入的文件也是一个按 Key 排序的结构,这些文件是 SSTable。
把 MemTable 写入 SSTable 这个写操作,因为它是把整块内存写入到整个文件中,这同样是一个顺序写操作
5、 文件内有序,但是文件间无序,没法查找。SSTable分层设计 =》 分层文件设计,上层满后写下层,下层合并过程包含排序过程
SSTable 被分为很多层,越往上层,文件越少,越往底层,文件越多。每一层的容量都有一个固定的上限,一般来说,下一层的容量是上一层的 10 倍。
当某一层写满了,就会触发后台线程往下一层合并,数据合并到下一层之后,本层的 SSTable 文件就可以删除掉了。合并的过程也是排序的过程,除了
Level 0(第 0 层,也就是 MemTable 直接 dump 出来的磁盘文件所在的那一层。)以外,每一层内的文件都是有序的,文件内的 KV 也是有序的,这样就比较便于查找了
查原理
1、去内存中的 MemTable 和 Immutable MemTable 中找,然后再按照顺序依次在磁盘的每一层 SSTable 文件中去找,只要找到了就直接返回:
越是被经常读写的热数据,它在这个分层结构中就越靠上,对这样的 Key 查找就越快。
2、缓存 SSTable 文件的 Key,用布隆过滤器避免无谓的查找等来加速查找过程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号