
分布式文件系统原理
文件系统架构原理
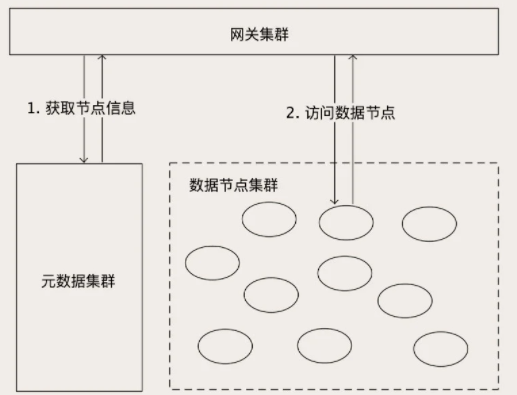
1、元数据 (Metadata):存储节点信息、文件信息和它们的映射关系 =》 使用ZooKeeper或etcd存储
2、网关:
a、收到对象读写请求后,先拿请求Key,去元数据集群查找Key的元数据
b、根据key元数据记载的对象长度,计算对象有多少块;
c、根据分块并行处理,每块需再查元数据,找到它对应的容器,最终合并所有块数据,返回客户端
文件对象如何拆分和保存
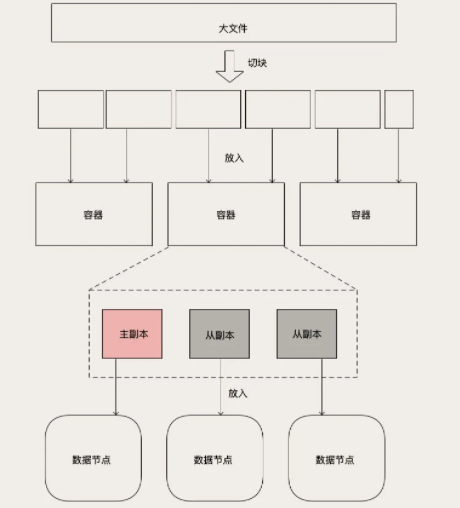
1、大文件拆分块(Block): 每块几十KB到几个MB
目的:提升读写性能,分散到不同数据节点,可并行读写;文件拆分相同大小块,并于维护管理
2、容器:将不同块聚合一组,并于元数据管理 =》类似于MySQL和Redis提到的分片,都是复制和迁移的基本单位
容灾:每个容器有N个副本,副本数据一样;主副本复制写,从副本去主副本上复制数据,保证数据一致。
复制:主从复制,复制的不是日志,而是整块数据,不同MySQL Binlog日志
a、性能考虑:
数据库每次更新数据量少,先记录操作日志,在更新存储引擎的数据,相当于磁盘串写2次数据;
文件系统每次写入块很大,两次磁盘IO开销不值得 =》
b、存储结构简单: 按顺序整块复制数据,依旧能保证主从副本一致性
总结
对象存储是最简单的分布式存储系统,主要由数据节点集群、元数据集群和网关集群(或者客户端)三部分构成。
数据节点集群负责保存对象数据,元数据集群负责保存集群的元数据,网关集群和客户端对外提供简单的访问 API,对内访问元数据和数据节点读写数据。
为了便于维护和管理,大的对象被拆分为若干固定大小的块儿,块儿又被封装到容器(也就分片)中,每个容器有一主 N 从多个副本,这些副本再被分散到集群的数据节点上保存。
对象存储虽然简单,但是它具备一个分布式存储系统的全部特征。
所有分布式存储系统共通的一些特性,对象存储也都具备,比如说数据如何分片,如何通过多副本保证数据可靠性,如何在多个副本间复制数据,确保数据一致性。
版本号选举技术
问题:对象存储并不是基于日志来进行主从复制的。假设我们的对象存储是一主二从三个副本,采用半同步方式复制数据,也就是主副本和任意一个从副本更新成功后,就给客户端返回成功响应。主副本所在节点宕机之后,这两个从副本中,至少有一个副本上的数据是和宕机的主副本上一样的,我们需要找到这个副本作为新的主副本,才能保证宕机不丢数据。但是没有了日志,如果这两个从副本上的数据不一样,如何确定哪个上面的数据是和主副本一样新呢?
解决方案:都是基于版本号来解决,在Leader上,KEY每更新一次,KEY的版本号就加1,版本号作为KV的一个属性,一并复制到从节点上,通过比较版本号就可以知道哪个节点上的数据是最新的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号