
Hadoop MapReduce原理、序列化
一、MapReduce过程
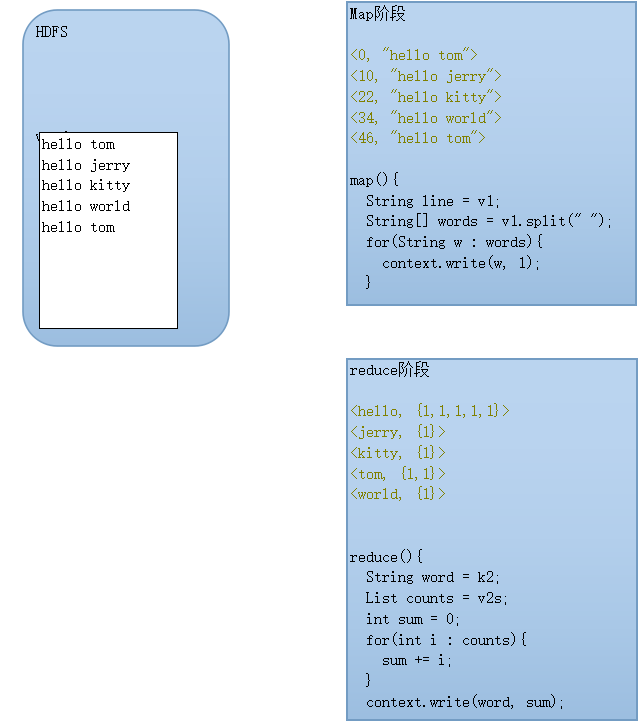
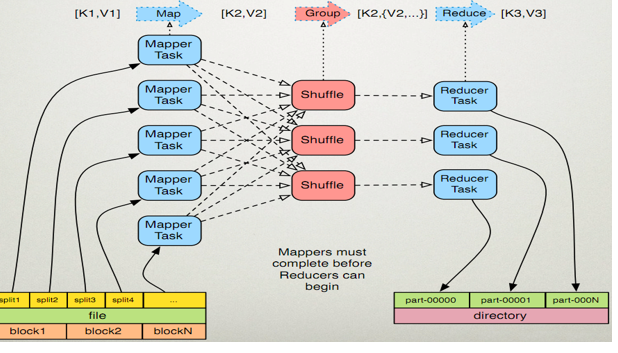
二、原理
三、wordCount
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInt("mapreduce.client.submit.file.replication", "20");
Job job = Job.getInstance(conf);
//notice
job.setJarByClass(WordCount.class);
//set mapper`s property
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path("/root/words.txt"));
//set reducer`s property
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileOutputFormat.setOutputPath(job, new Path("/root/wcout"));
//submit
job.waitForCompletion(true);
}
}
// key1,value1,key2,value2; key1行号无意义,value2计算单词个数
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//accept
String line = value.toString();
//split
String[] words = line.split(" ");
//loop
for(String w : words){
//send
context.write(new Text(w), new LongWritable(1));
}
}
}
public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
//define a counter
long counter = 0;
//loop
for(LongWritable l : values){
counter += l.get();
}
//write
context.write(key, new LongWritable(counter));
}
}
生成jar包
E:\J2EE_workspace\Test\src>javac -cp .;D:\maven-repository\commons-cli\commons-cli\1.2\commons-cli-1.2.jar;D:\maven-repository\org\apache\hadoop\hadoop-client\3.2.0\hadoop-client-3.2.0.jar;D:\maven-repository\org\apache\hadoop\hadoop-common\3.2.0\hadoop-common-3.2.0.jar;D:\maven-repository\org\apache\hadoop\hadoop-hdfs-client\3.2.0\hadoop-hdfs-client-3.2.0.jar;D:\maven-repository\org\apache\hadoop\hadoop-mapreduce-client-core\3.2.0\hadoop-mapreduce-client-core-3.2.0.jar WordCount.java
E:\J2EE_workspace\Test\src>jar -cvf wc3.jar *.class
已添加清单
正在添加: WordCount$IntSumReducer.class(输入 = 1739) (输出 = 739)(压缩了 57%)
正在添加: WordCount$TokenizerMapper.class(输入 = 1736) (输出 = 754)(压缩了 56%)
正在添加: WordCount.class(输入 = 3037) (输出 = 1619)(压缩了 46%)
sudo -u hdfs hadoop jar /root/songzehao/data/wc3.jar WordCount /tmp/songzehao/words_input /tmp/songzehao/words_output
四、序列化
a、定义class继承Writable
public class DataBean implements Writable{
private String tel;
private long upPayLoad;
private long downPayLoad;
private long totalPayLoad;
public DataBean(){}
public DataBean(String tel, long upPayLoad, long downPayLoad) {
super();
this.tel = tel;
this.upPayLoad = upPayLoad;
this.downPayLoad = downPayLoad;
this.totalPayLoad = upPayLoad + downPayLoad;
}
@Override
public String toString() {
return this.upPayLoad + "\t" + this.downPayLoad + "\t" + this.totalPayLoad;
}
// notice : 1 type 2 order
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(tel);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
out.writeLong(totalPayLoad);
}
@Override
public void readFields(DataInput in) throws IOException {
this.tel = in.readUTF();
this.upPayLoad = in.readLong();
this.downPayLoad = in.readLong();
this.totalPayLoad = in.readLong();
}
public String getTel() {
return tel;
}
public void setTel(String tel) {
this.tel = tel;
}
public long getUpPayLoad() {
return upPayLoad;
}
public void setUpPayLoad(long upPayLoad) {
this.upPayLoad = upPayLoad;
}
public long getDownPayLoad() {
return downPayLoad;
}
public void setDownPayLoad(long downPayLoad) {
this.downPayLoad = downPayLoad;
}
public long getTotalPayLoad() {
return totalPayLoad;
}
public void setTotalPayLoad(long totalPayLoad) {
this.totalPayLoad = totalPayLoad;
}
}
b、编写Map、Reduce和调用类
public static class DCMapper extends Mapper<LongWritable, Text, Text, DataBean>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//accept
String line = value.toString();
//split
String[] fields = line.split("\t");
String tel = fields[1];
long up = Long.parseLong(fields[8]);
long down = Long.parseLong(fields[9]);
DataBean bean = new DataBean(tel, up, down);
//send
context.write(new Text(tel), bean);
}
}
public static class DCReducer extends Reducer<Text, DataBean, Text, DataBean>{
@Override
protected void reduce(Text key, Iterable<DataBean> values, Context context)
throws IOException, InterruptedException {
long up_sum = 0;
long down_sum = 0;
for(DataBean bean : values){
up_sum += bean.getUpPayLoad();
down_sum += bean.getDownPayLoad();
}
DataBean bean = new DataBean("", up_sum, down_sum);
context.write(key, bean);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(DataCount.class);
job.setMapperClass(DCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DataBean.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
job.setReducerClass(DCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DataBean.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号