Azkaban 简介(一)
什么是任务调度
大数据平台技术框架支持的开发语言多种多样,开发人员的背景差异也很大,这就产生出很多不同类型的程序(任务)运行在大数据平台之上,如:MapReduce、Hive、Pig、Spark、Java、Shell、Python 等。
这些任务需要不同的运行环境,并且除了定时运行,各种类型之间的任务存在依赖关系,一张简单的任务依赖图如下:
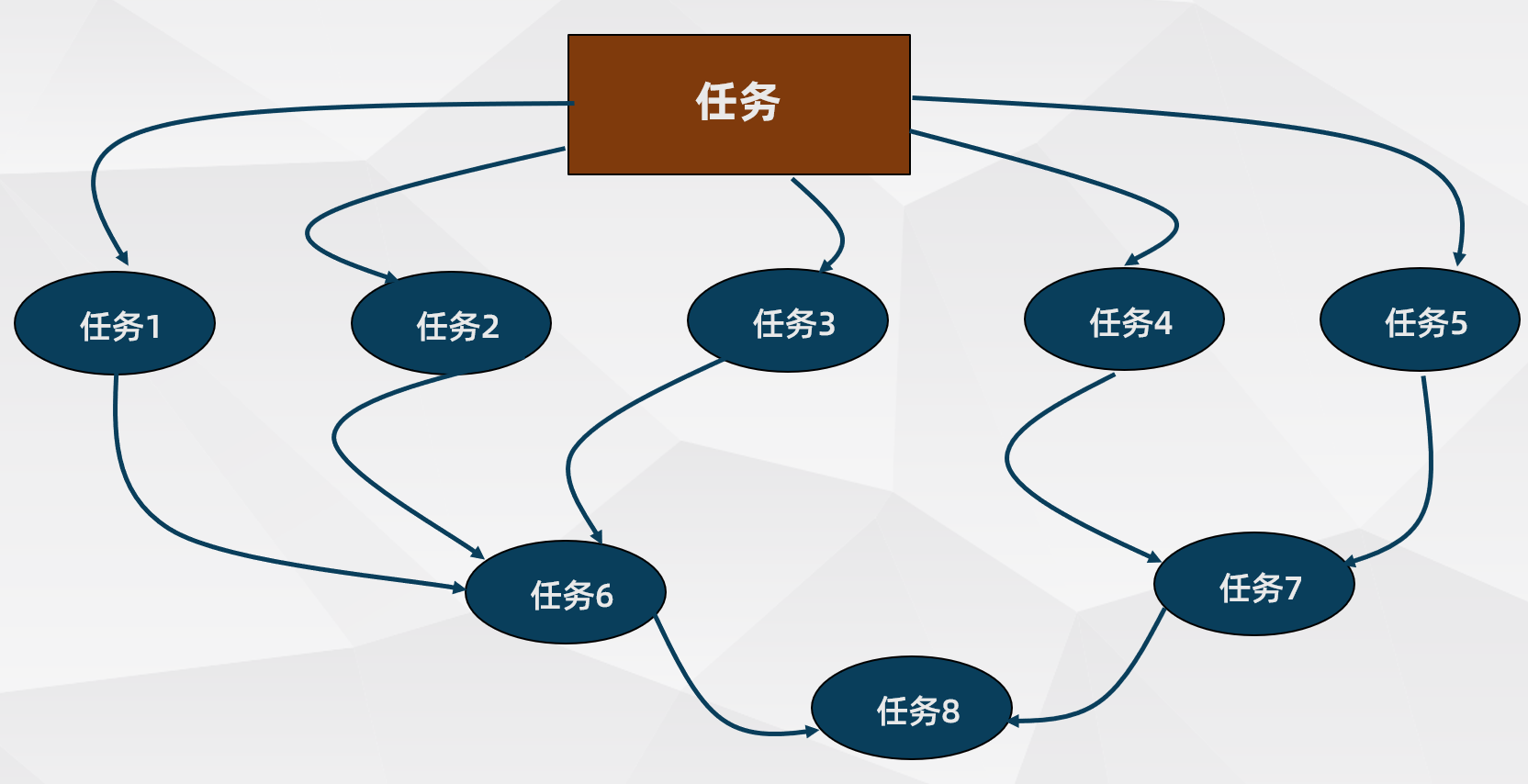
常见任务调度工具
- crontab (Linux 自带命令,使用方式简单,适合不是非常复杂的场景,比如只按照时间来调度)
- oozie( Hadoop 自带的开源调度系统,使用方式比较复杂,适合大型项目场景)
- azkaban(一个开源调度系统,使用方式比较简单,适合中小型项目场景)
- 企业定制开发(企业自研的调度系统,不开源)
Azkaban 是什么
Azkaban 是由 Linkedin 公司推出的一个批量工作流任务调度器,Azkaban 使用 job 文件建立任务之间的依赖关系,并提供 Web 界面供用户管理和调度工作流
Azkaban 特点
Azkaban 是由 Linkedin 开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban 定义了一种 KV 文件格式来建立任务之间的依赖关系,并提供一个易于使用的 web 用户界面维护和跟踪你的工作流。
它有如下功能特点:
- Web 用户界面
- 方便上传工作流
- 方便设置任务之间的关系
- 调度工作流
- 认证/授权(权限的工作)
- 能够杀死并重新启动工作流
- 模块化和可插拔的插件机制
- 项目工作区
- 工作流和任务的日志记录和审计
Azkaban 与 Oozie 对比
Azkaban 和 Oozie 是市面上最流行的两种调度器。总体来说,Ooize 相比 Azkaban 是一个重量级的任务调度系统,功能全面,但部署和使用也更复杂,比较适合作为大型项目的任务调度系统。而 Azkaban 相对而言,配置和使用更为简单,能够满足常见的任务调度,比较适合作为中小型项目的任务调度系统。
Azkaban 和 Oozie 详情对比如下:
-
功能
两者均可以调度 mapreduce,pig,java,脚本工作流任务
两者均可以定时执行工作流任务 -
工作流定义
Azkaban 使用 Properties 文件定义工作流
Oozie 使用 XML 文件定义工作流 -
工作流传参
Azkaban 支持直接传参
Oozie 支持参数和 EL 表达式
-
定时执行
Azkaban 的定时执行任务是基于时间的
Oozie 的定时执行任务基于时间和输入数据 -
资源管理
Azkaban 有较严格的权限控制,如用户对工作流进行读/写/执行等操作
Oozie 暂无严格的权限控制 -
工作流执行
Azkaban 有两种运行模式,分别是单机模式和集群模式
Oozie 作为工作流服务器运行,支持多用户和多工作流 -
工作流管理
Azkaban 支持浏览器以及 ajax 方式操作工作流
Oozie 支持命令行、HTTP REST、Java API、浏览器操作工作流
Azkaban 运行模式及架构
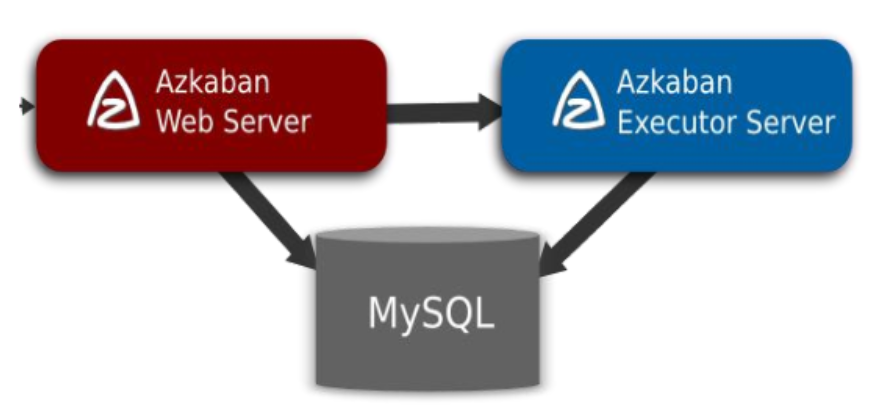
Azkaban 三大核心组件
- 关系型元数据库(MySQL)
- Azkaban Web Server
- Azkaban Executor Server
Azkaban有两种部署方式
-
solo server mode(单机模式)
WebServer 和 ExecutorServer 在同一个进程
-
cluster server mode(集群模式)
WebServe r和 ExecutorServer 运行在不同进程,并用数据库保存定义及状态
- 单个Executor
- 多个Executor
Azkaban Web Server
AzkabanWebServer 是 Azkaban 的主要管理者,负责项目管理、身份验证、调度和监控执行,并且为用户界面
Azkaban Executor
提交和执行工作流,记录工作流日志,和 Azkaban WebServer 可以在同一台服务器,也可部署在独立的机器。把 Executor 单独分开有几个好处:
- 在多 Executor 模式下可以方便扩展
- 工作流在某一个 Executor 挂掉,可以在另一个 Executor 上重试
- 可以滚动升级,从而不影响调度
Azkaban 元数据库
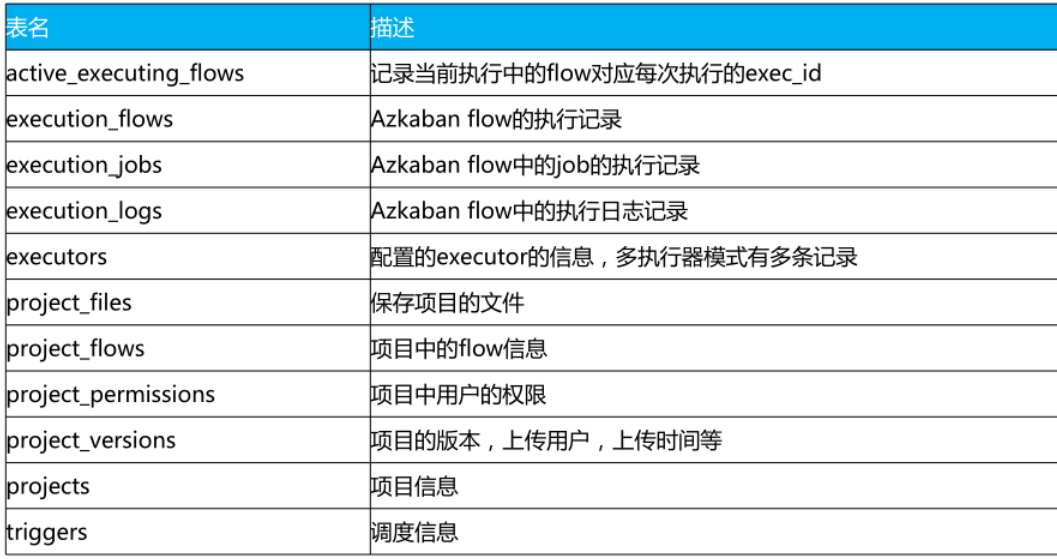
Azkaban 任务调度步骤
- Azkaban 新建项目
- 在 Azkaban Web 界面创建 Project
- 创建 job 文件
- 将文件压缩为 zip 文件
- 上传 zip 文件到 Web 界面
- 执行调度
Azkaban 常见任务类型
执行 shell 命令
type=command
command=echo 'hello'
执行 shell 脚本
type=command
command=sh hello.sh
执行 Spark 程序
type=command
command=/usr/install/spark/bin/spark-submit --class com.test.AzkabanTest test-1.0-SNAPSHOT.jar
hive 命令\脚本
type=command
command=beeline -u jdbc:hive2://localhost:10000 -n hive -p hive -f 'test.sql'
执行 MapReduce 程序
type=command
command=${HADOOP_HOME}bin/hadoop jar hadoop-mapreduce-examples-2.8.0.jar
wordcount ${input} ${output}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号