Kylin 工作原理(二)
什么是 Cube 和 Cuboid
给定一个数据模型,我们可以对其上所有维度进行组合。对于 N 个维度来说,有组合的可能性为 2 的 N 次方种。对每一种维度的组合,将度量做聚合运算,运算的结果保存为一个物理视图,称为 Cuboid。
将所有维度组合的 Cuboid 作为一个整体,被称为 Cube。
简单来说,一个 Cube 就是许多按维度聚合的物化视图的集合。
举例
假定有一个电商的销售数据集,其中维度的时间(Time)、商品(Item)、地点(Location)和供应商(Supplier),度量有销售额(GMV),那么所有维度的组合就有 2 的 4 次方 16 种。
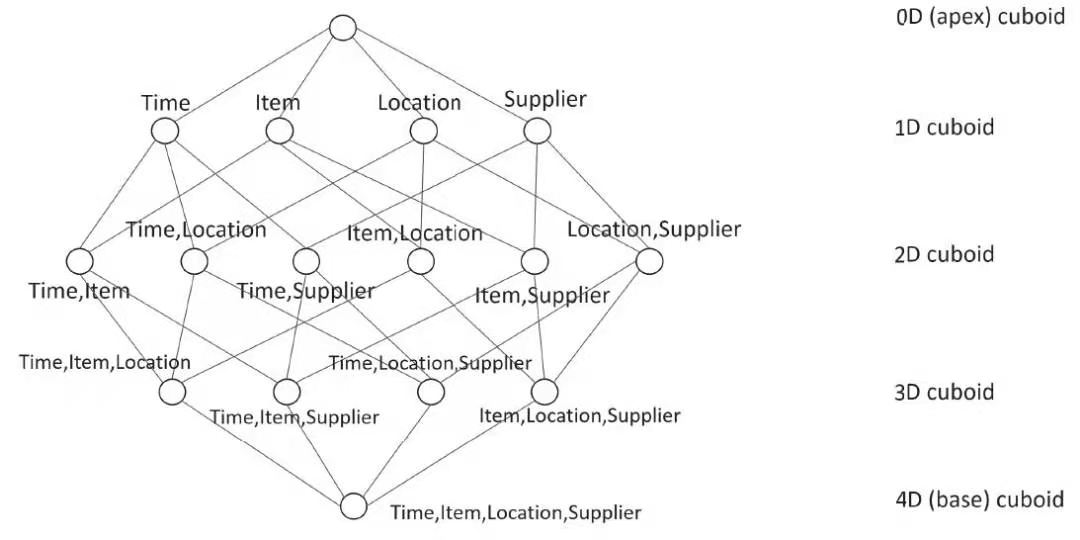
如果用 SQL 来表达计算 Cuboid[Time,Location],那就是
select Time,Location,Sum(GMV) as GMV from Sales group by Time,Location
将计算结果保存为物化视图,所有 Cuboid 物化视图的总称就是 Cube。
工作原理
Kylin 的工作原理就是对数据模型做 Cube 预计算,并利用计算的结果加速查询。
Kylin 工作过程如下:
- 指定数据模型,定义维度和度量
- 预计算 Cube,计算所有 Cuboid 并将其保存为物化视图
- 执行查询时,读取 Cuboid,进行加工运算产生查询结果
由于 Kylin 的查询过程不会扫描原始记录,而是通过预计算完成表的关联、聚合等复杂运算,并利用预计算的结果来执行查询,因此其速度相比非预计算的查询技术一般要快一个到两个数量级,并且在超大数据集上其优势更明显。当数据集达到千亿乃至万亿级别时, Kylin 的速度甚至可以超越其他非预计算技术 1000 倍以上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号