Spark 集群安装部署
安装准备
Spark 集群和 Hadoop 类似,也是采用主从架构,Spark 中的主服务器进程就叫 Master(standalone 模式),从服务器进程叫 Worker
Spark 集群规划如下:
- node-01:Master
- node-02:Worker
- node-03:Worker
安装步骤
1. 上传并解压 Spark 安装文件
将 spark-2.4.7-bin-hadoop2.7.tgz 安装包上传到 node-01 的 /root 目录下,并将其解压
# 解压到 /apps 目录中
[root@node-01 ~]# tar -zxvf spark-2.4.7-bin-hadoop2.7.tgz -C apps/
# 删除安装压缩包
[root@node-01 ~]# rm -rf spark-2.4.7-bin-hadoop2.7.tgz
[root@node-03 ~]# cd /root/apps/
# 改名
[root@node-01 apps]# mv spark-2.4.7-bin-hadoop2.7/ spark-2.4.7
2. 配置环境变量
[root@node-01 ~]# vim /etc/profile
#行尾添加
export SPARK_HOME=/root/apps/spark-2.4.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
[root@node-01 ~]# source /etc/profile
3. 配置运行环境
[root@node-01 ~]# cd /root/apps/spark-2.4.7/conf/
# 改名(去掉后面的 template 模板后缀名)
[root@node-01 conf]# mv spark-env.sh.template spark-env.sh
[root@node-01 conf]# vi spark-env.sh
# 行尾添加
export JAVA_HOME=/root/apps/jdk1.8.0_141/
# 设置 Spark Master 所在的主机名(或IP地址)
export SPARK_MASTER_HOST=node-01
export SPARK_MASTER_PORT=7077
4. 修改 slaves 配置
该脚本文件用于设置 Master 下面的 Worker 的主机名(或IP地址)
[root@node-01 ~]# cd /root/apps/spark-2.4.7/conf/
# 改名(去掉后面的 template 模板后缀名)
[root@node-01 conf]# mv slaves.template slaves
[root@node-01 conf]# vi slaves
node-02
node-03
5. 创建启动和关闭 Spark 集群脚本软连接
创建软连接的原因是 hadoop/sbin 目录和 spark/sbin 目录脚本可能命名相同,导致执行命令冲突
[root@node-01 ~]# cd /root/apps/spark-2.4.7/sbin/
[root@node-01 sbin]# ln -s start-all.sh start-all-spark.sh
[root@node-01 sbin]# ln -s stop-all.sh stop-all-spark.sh
5. 将 Spark 安装包复制到集群其他主机上
[root@node-01 ~]# cd /etc
[root@node-01 etc]# scp profile node-02:$PWD
[root@node-01 etc]# scp profile node-03:$PWD
[root@node-02 ~]# source /etc/profile
[root@node-03 ~]# source /etc/profile
[root@node-01 ~]# cd apps/
[root@node-01 apps]# scp -r spark-2.4.7/ node-02:$PWD
[root@node-01 apps]# scp -r spark-2.4.7/ node-03:$PWD
6. 启动 Spark 集群
Spark 的 sbin 目录(里面存放各种 Spark 操作命令)
[root@node-01 ~]# start-all-spark.sh
starting org.apache.spark.deploy.master.Master, logging to /root/apps/spark-2.4.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-hdp-01.out
hdp-03: starting org.apache.spark.deploy.worker.Worker, logging to /root/apps/spark-2.4.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hdp-03.out
hdp-02: starting org.apache.spark.deploy.worker.Worker, logging to /root/apps/spark-2.4.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hdp-02.out
[root@hdp-01 sbin]# jps
1690 Master
1742 Jps
再去查看 node-02 和 node-03
[root@node-02 ~]# jps
1557 Jps
1512 Worker
[root@node-03 ~]# jps
1538 Worker
1583 Jps
说明 Spark 集群已经启动成功
- 单独启动 Master:# start-master.sh
- 单独启动 Worker:# start-slave.sh spark://node-01:7077
6. 启动 Spark 的浏览器 Web 页面
这里 Web 的服务器端口号是 8080(端口号 7077 是 RPC 远程调用的通信端口)
打开浏览器输入:http://node-01:8080/ 回车
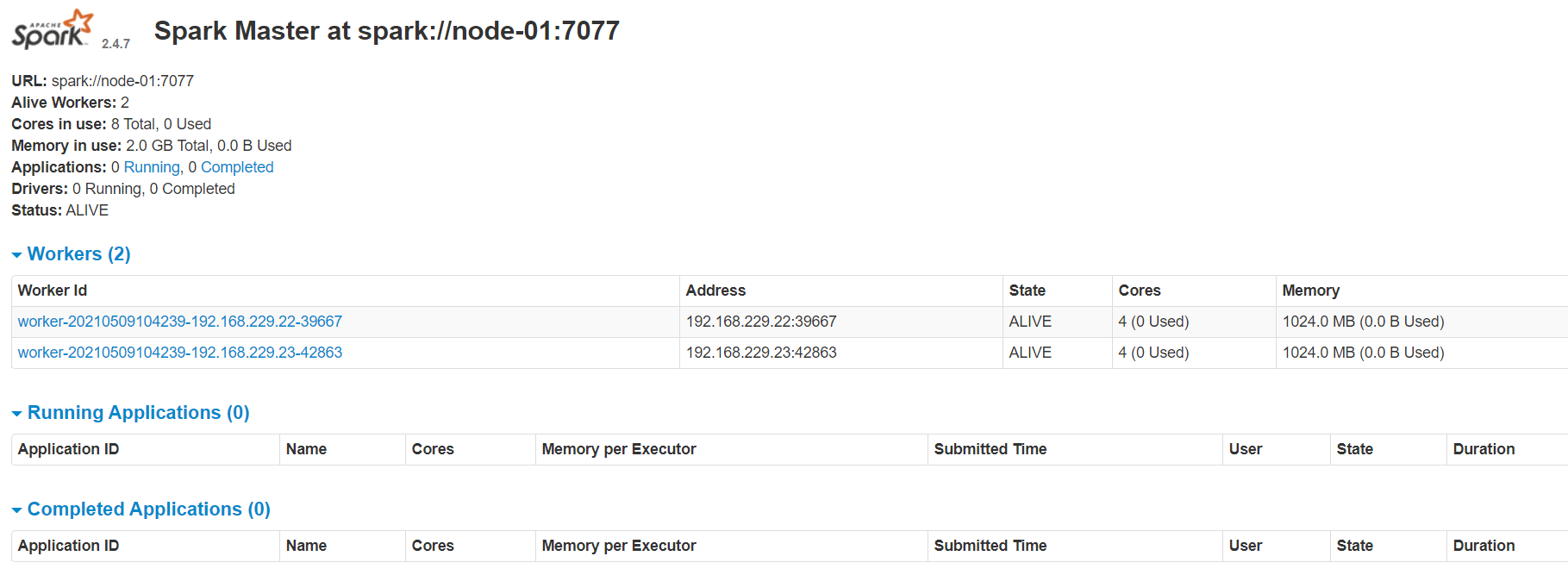
默认情况下 Spark 会占用机器上的所有 cores(CPU)和 memory(内存)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号