MySQL 查询操作
基本语法
select 查询的列 from 表名;
注意:
select 语句中不区分⼤⼩写,查询的结果放在⼀个表格中,表格的第1⾏称为列头,第2⾏开始是数据,类属于⼀个⼆维数组。
查询常量
select 常量值1,常量值2,常量值3;
mysql> select 1,'a';
+---+---+
| 1 | a |
+---+---+
| 1 | a |
+---+---+
1 row in set (0.00 sec)
查看表达式
select 表达式;
mysql> select 1+2,3*10,10/3;
+-----+------+--------+
| 1+2 | 3*10 | 10/3 |
+-----+------+--------+
| 3 | 30 | 3.3333 |
+-----+------+--------+
1 row in set (0.00 sec)
查询函数
select 函数;
mysql> select sum(1+2);
+----------+
| sum(1+2) |
+----------+
| 3 |
+----------+
1 row in set (0.00 sec)
查询指定字段
select 字段1,字段2,字段3 from 表名;
查询所有列
select * from 表名;
列别名
select 列 [as] 别名 from 表;
表别名
select 别名.字段,别名.* from 表名 [as] 别名;
注意
- 建议别名前⾯跟上 as 关键字
- 查询数据的时候,避免使⽤ select *,建议需要什么字段写什么字段
条件查询
select 列名 from 表名 where 列 运算符 值
条件查询运算符
- 等于(=)
- 不等于(<>、!=) # 两者意义相同,在可移植性上前者优于后者
- 大于(>) # 字符按照 ASCII 码对应的值进⾏⽐较,⽐较时按照字符对应的位置⼀个字符⼀个字符的⽐较。
- 小于(<)
- 小于等于(<=)
- 大于等于(>=)
逻辑查询运算符
-
AND(并且)
-
OR(或者)
-
like(模糊查询)
- %:表⽰匹配任意⼀个或多个字符
- _:表⽰匹配任意⼀个字符
-
BETWEEN ... AND(区间查询)# 可以提⾼语句的简洁度
-
IN 查询
- in 后⾯括号中可以包含多个值,对应记录的字段满⾜ in 中任意⼀个都会被返回
- in 列表的值类型必须⼀致或兼容
- in 列表中不⽀持通配符
-
NOT IN 查询:与 IN 查询相反
-
NULL 值专用查询
查询运算符、like 、between ... and 、in 、not in 对 NULL 值查询不起效
- IS NULL (返回值为空的记录):select 列名 from 表名 where 列 is null;
- IS NOT NULL(返回值不为空的记录):select 列名 from 表名 where 列 is not null;
-
<=> (安全等于):既可以判断NULL值,又可以判断普通的数值,可读性较低,⽤得较少
排序与分页
排序查询(order by)
select 字段名 from 表名 order by 字段1 [asc|desc], 字段2 [asc|desc];
- 需要排序的字段跟在 order by 之后;
- asc|desc 表⽰排序的规则(asc:升序,desc :降序,默认为 asc)
- ⽀持多个字段进⾏排序,多字段排序之间⽤逗号隔开
排序方式
- 单字段排序
- 多字段排序
- 按别名排序
- 按函数排序
limit
limit ⽤来限制 select 查询返回的⾏数,常⽤于分页等操作
select 列 from 表 limit [offset,] count;
limit 中 offset 和 count 的值不能⽤表达式,只能够跟明确的数字(不能为负数)
分页查询:select 列 from 表名 limit (page - 1) * pageSize, pageSize;
分组查询
SELECT column, group_function,... FROM table
[WHERE condition]
GROUP BY group_by_expression
[HAVING group_condition];
- group_function:聚合函数
- group by expression :分组表达式,多个之间⽤逗号隔开。
- group_condition :分组之后对数据进⾏过滤
分组中 select 后⾯只能有两种类型的列
- 出现在 group by 后的列
- 使⽤聚合函数的列
聚合函数
聚合函数对一组值执行计算并返回单一的值
- max:求最大值
- min:求最小值
- sum:求累加和
- avg:求平均值
- count:统计行的数量
单字段分组
GROUP BY X # 意思是将所有具有相同X字段值的记录放到一个分组里
多字段分组
GROUP BY X, Y # 意思是将所有具有相同X字段值和Y字段值的记录放到一个分组里
分组前筛选数据
分组前对数据进⾏筛选,使⽤ where 关键字
分组后筛选数据
分组后对数据筛选,使⽤having 关键字
where 和 having 的区别
- where 是在分组(聚合)前对记录进⾏筛选,⽽ having 是在分组结束后的结果⾥筛选,最
后返回整个 sql 的查询结果。- 可以把 having 理解为两级查询,即含having 的查询操作先获得不含 having ⼦句时的sql查询
结果表,然后在这个结果表上使⽤having 条件筛选出符合的记录,最后返回这些记录,因
此,having 后是可以跟聚合函数的,并且这个聚集函数不必与 select 后⾯的聚集函数相
同。
where & group by & having & order by & limit ⼀起协作
where、group by 、having 、order by 、limit 这些关键字⼀起使⽤时,先后顺序有明确的限
制,语法如下:
select 列 from
表名
where [查询条件]
group by [分组表达式]
having [ 分组过滤条件]
order by [排序条件]
limit [offset,] count;
注意:必须按照上⾯的顺序写 SQL 语句,否则报错
MySQL 常用函数汇总
MySQL 数值型函数
- abs:求绝对值
- sqrt:求二次方根
- mod:求余数
- ceil 和 ceiling:向上取整
- floor:向下取整
- rand:生成随机数
- round:四舍五入
- sign:返回参数的符号(正数:1 负数:-1 零:0)
- pow 和 power:次方
- sin:正弦
MySQL 字符串函数
- length:返回字符串字节长度
- concat:合并字符串
- insert:替换字符串
- lower:将字符串转换为小写
- upper:将字符串转换为大写
- left:从左侧截取字符串
- right:从右侧截取字符串
- trim:删除字符串两侧空格
- replace:字符串替换
- substr 和 substring:截取字符串
- reverse:反转字符串
MySQL 日期和时间函数
-
curdate 和 current_date:返回当前系统日期
mysql> select curdate(); +------------+ | curdate() | +------------+ | 2021-02-28 | +------------+ 1 row in set (0.01 sec) -
curtime 和 current_time:返回当前系统时间
mysql> select curtime(); +-----------+ | curtime() | +-----------+ | 20:02:42 | +-----------+ 1 row in set (0.00 sec) -
now 和 sysdate:返回当前系统日期和时间
mysql> select now(); +---------------------+ | now() | +---------------------+ | 2021-02-28 20:03:22 | +---------------------+ 1 row in set (0.00 sec) -
unix_timestamp:获取 UNIX 时间戳
mysql> select unix_timestamp(); +------------------+ | unix_timestamp() | +------------------+ | 1614513856 | +------------------+ 1 row in set (0.00 sec) # UNIX_TIMESTAMP(date) 若⽆参数调⽤,返回⼀个⽆符号整数类型的 UNIX 时间戳('1970-01-01 00:00:00'GMT 之后的秒数) -
from_unixtime:时间戳转日期
mysql> select from_unixtime(1614513856); +---------------------------+ | from_unixtime(1614513856) | +---------------------------+ | 2021-02-28 20:04:16 | +---------------------------+ 1 row in set (0.00 sec) -
month:获取指定日期月份
-
monthname:获取指定日期月份的英文名称
-
dayname:获取指定日期的星期名称
-
dayofweek:获取日期对应的周索引(1 表⽰周⽇,7 表⽰周六)
-
week:获取指定日期是一年的第几周
-
dayofyear:获取指定日期在一年中的位置
-
dayofmonth:获取指定日期在一个月中的位置
-
year:获取年份
-
time_to_sec:将时间转换为秒值
-
sec_to_time:将秒值转换为时间格式
-
date_add 和 adddate:日期加法运算
-
date_sub 和 subdate:日期减法运算
-
addtime:时间加法运算
-
subtime:时间减法运算
-
datediff:获取两个日期的时间间隔
-
date_format:格式化指定日期
mysql> select date_format(now(),'%Y-%m-%d %H:%i:%s') as time; +---------------------+ | time | +---------------------+ | 2021-02-28 20:16:11 | +---------------------+ 1 row in set (0.00 sec) -
weekday:获取指定日期在一周内的索引(0:星期⼀ 6:星期日)
MySQL 流程控制函数
-
if:判断
-
ifnull:判断是否为空
-
case:搜索语句,类似于java 中的if..else if..else
# ⽅式1: CASE <表达式> WHEN <值1> THEN <操作> WHEN <值2> THEN <操作> ... ELSE <操作> END CASE; # ⽅式2: CASE WHEN <条件1> THEN <命令> WHEN <条件2> THEN <命令> ... ELSE commands END CASE;子查询
嵌套在 select 语句中的 select 语句,称为⼦查询或内查询。外部的 select 查询语句,称为主查询或外查询。
子查询分类
按结果集的⾏列数不同分类
-
标量子查询(结果集中只有一行一列)
SELECT * FROM employees a WHERE a. salary > (SELECT salary FROM employees WHERE last_name = 'Abel'); -
列子查询(结果集中只有一列多行)
SELECT a.last_name FROM employees a WHERE a. department_id IN (SELECT DISTINCT department_id FROM departments WHERE location_id IN (1400, 1700)); -
行子查询(结果集中只有一行多列)
SELECT * FROM employees a WHERE a. employee_id = (SELECT min (employee_id) FROM employees) AND salary = (SELECT max (salary) FROM employees); -
表子查询(结果集中有多行多列)
按⼦查询出现在主查询中的不同位置分类
-
select 后⾯:仅仅⽀持标量⼦查询
SELECT a.*, (SELECT count(*) FROM employees b WHERE b. department_id = a.department_id ) AS employee_num FROM departments a; -
from 后⾯:⽀持表⼦查询
将⼦查询的结果集充当⼀张表,要求必须起别名,否者这个表找不到。然后将真实的表和⼦查询结果表进⾏连接查询。
SELECT t1.department_id,sa AS '平均⼯资',t2.grade_level FROM (SELECT department_id, avg (a. salary ) sa FROM employees a GROUP BY a.department_id ) t1, job_grades t2 WHERE t1.sa BETWEEN t2.lowest_sal AND t2. highest_sal ; -
where 或 having 后⾯:⽀持标量⼦查询(单列单⾏)、列⼦查询(单列多⾏)、⾏⼦查询(多列多⾏)
in ,any ,some,all分别是⼦查询关键词之⼀
- in :in 常⽤于 where 表达式中,其作⽤是查询某个范围内的数据
- any 和 some⼀样:可以与 =、>、>=、<、<=、<> 结合起来使⽤,分别表⽰等于、⼤于、⼤于等于、⼩于、⼩于等于、不等于其中的任何⼀个数据
- all:可以与=、>、>=、<、<=、<>结合是来使⽤,分别表⽰等于、⼤于、⼤于等于、⼩于、⼩于等于、不等于其中的其中的所有数据
-
exists 后⾯(即相关⼦查询):表⼦查询(多⾏、多列)
- exists查询结果:1 或 0,exists 查询的结果⽤来判断⼦查询的结果集中是否有值;⼀般来说,能⽤exists的⼦查询,绝对都能⽤ in 代替,所以 exists ⽤的少
- 和前⾯的查询不同,这先执⾏主查询,然后主查询查询的结果,在根据⼦查询进⾏过滤,⼦查询中涉及到主查询中⽤到的字段,所以叫相关⼦查询
SELECT exists (SELECT employee_id FROM employees WHERE salary = 300000 ) AS 'exists返回1或者0';
注意⼦查询中列的值为 NULL 的时候,外查询的结果为空(大坑)
连接查询
笛卡尔积(交叉连接)
有两个集合 A 和 B,笛卡尔积表⽰ A 集合中的元素和 B 集合中的元素,任意相互关联产⽣的所有可能的结果。
select 字段 from 表1,表2[, 表N]; # 隐式交叉连接 或者 select 字段 from 表1 join 表2 [join 表N]; # 显示交叉连接内连接
内连接相当于在笛卡尔积的基础上加上了连接的条件。当没有连接条件的时候,内连接上升为笛卡尔积。
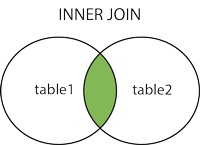
select 字段 from 表1 inner join 表2 on 连接条件; 或 select 字段 from 表1 join 表2 on 连接条件; 或 select 字段 from 表1, 表2 [where 关联条件];内连接也称为等值连接,结果为返回两张表都满足条件的部分
外连接
外连接涉及到 2 个表,分为:主表和从表,要查询的信息主要来⾃于哪个表,谁就是主表。外连接查询结果为主表中所有记录。如果从表中有和它匹配的,则显⽰匹配的值,这部分相当于内连接查询出来的结果;如果从表中没有和它匹配的,则显⽰ null 。
外连接查询结果 = 内连接的结果 + 主表中有的⽽内连接结果中没有的记录
左外连接
取左边的表的全部,右边的表按条件,符合的显示,不符合则显示 null
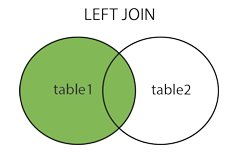
select 列 from 主表 left join 从表 on 连接条件;右外连接
取右边的表的全部,左边的表按条件,符合的显示,不符合则显示 null
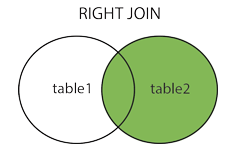
select 列 from 从表 right join 主表 on 连接条件;全连接
使用 full join 关键字,全连接返回左外连接和右外连接的结果
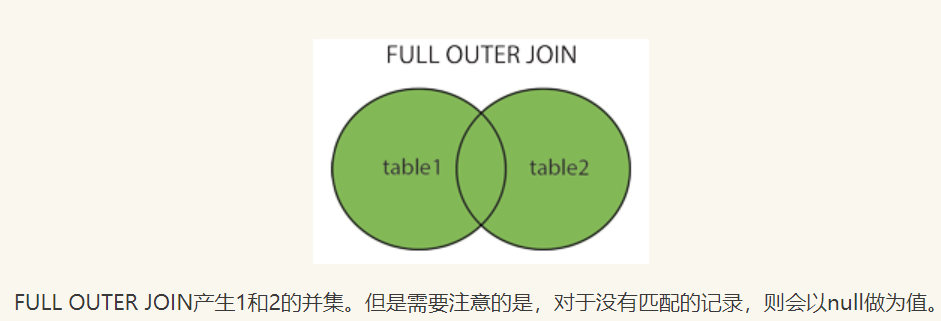
select 列 from 从表 full join 主表 on 连接条件;自连接
自连接是指使用表的别名实现表与其自身连接的查询方法。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号