设计模式之美 - 原型模式
设计模式之美 - 原型模式
设计模式之美目录:https://www.cnblogs.com/binarylei/p/8999236.html
原型模式:如果对象的创建成本比较大,可以基于已有的原型对象来创建新的对象。
对于熟悉 JavaScript 语言的前端程序员来说,原型模式是一种比较常用的开发模式。这是因为,有别于 Java、C++ 等基于类的面向对象编程语言,JavaScript 是一种基于原型的面向对象编程语言。即便 JavaScript 现在也引入了类的概念,但它也只是基于原型的语法糖而已。
1. 原型模式的结构
原型模式怎么实现的,其实只要想一想 Java Object#clone 方法就清楚了。原型模式有两种表现形式: 简单形式和登记形式。
1.1 简单原型模式
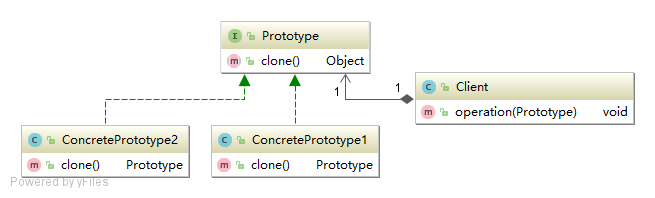
这种形式涉及到三个角色:
(1)客户(Client)角色:客户类提出创建对象的请求。
(2)抽象原型(Prototype)角色:这是一个抽象角色,通常由一个 Java 接口或 Java 抽象类实现。此角色给出所有的具体原型类所需的接口。
(3)具体原型(Concrete Prototype)角色:被复制的对象。此角色需要实现抽象的原型角色所要求的接口。
1.2 登记式原型模式
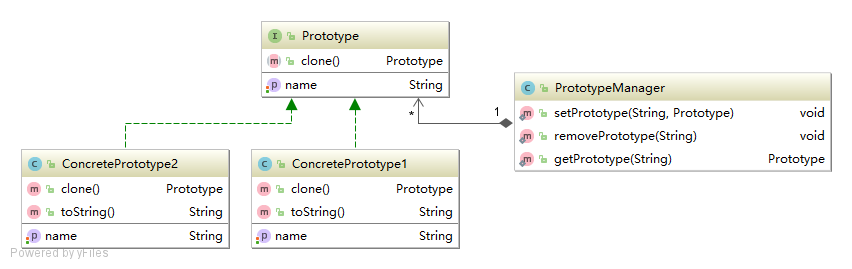
登记式原型模式相对于简单原型模式,多了一个原型管理器(PrototypeManager)角色,该角色的作用是:创建具体原型类的对象,并记录每一个被创建的对象。
1.3 简单原型 vs 登记式原型
简单原型和登记式原型模式各有其长处和短处。
- 简单原型:如果需要创建的原型对象数目较少而且比较固定的话,可以采取这种原型模式。在这种情况下,原型对象的引用可以由客户端自己保存。
- 登记式原型:如果要创建的原型对象数目不固定的话,可以采取登记式。此时,先从缓存中命中原型对象,如果没有则调用其 clone 方法创建对象。这是不是和我们常用的数据库连接池、线程池很像了呢?
1.4 原型模式 vs 单例模式
- 单例对象允许有限的多个:如数据库连接池、线程池等,是不是就变化成原型模式呢?
- 每种类型的单例对象只允许一个:如 Logger 日志,每个 class.getName 都创建一个实例,这其实也是单例模式的变种。
2. Java 中的克隆方法
Object 类提供 clone() 方法对对象进行复制,子类当然也可以把这个方法置换掉,提供满足自己需要的复制方法。对象的复制有一个基本问题,就是对象通常都有对其他的对象的引用。也就是说:Object#clone 方法是浅拷贝。
Java 语言提供的 Cloneable 接口只起一个作用,就是在运行时期通知 Java 虚拟机可以安全地在这个类上使用 clone() 方法。通过调用这个 clone() 方法可以得到一个对象的复制。由于 Object 类本身并不实现 Cloneable 接口,因此如果所考虑的类没有实现 Cloneable 接口时,调用 clone() 方法会抛出 CloneNotSupportedException 异常。
2.1 克隆满足的条件
clone() 方法将对象复制了一份并返还给调用者。所谓“复制”的含义与 clone() 方法是怎么实现的。一般而言,clone() 方法满足以下的描述:
(1)对任何的对象 x,都有:x.clone() != x。换言之,克隆对象与原对象不是同一个对象。
(2)对任何的对象 x,都有:x.clone().getClass() == x.getClass(),换言之,克隆对象与原对象的类型一样。
(3)如果对象 x 的 equals() 方法定义其恰当的话,那么 x.clone().equals(x) 应当成立的。
在 JAVA 语言的 API 中,凡是提供了 clone() 方法的类,都满足上面的这些条件。JAVA 语言的设计师在设计自己的 clone() 方法时,也应当遵守着三个条件。一般来说,上面的三个条件中的前两个是必需的,而第三个是可选的。
2.2 浅克隆和深克隆
无论你是自己实现克隆方法,还是采用 Java 提供的克隆方法,都存在一个浅度克隆和深度克隆的问题。
-
浅度克隆:只负责克隆按值传递的数据(比如基本数据类型、String类型),而不复制它所引用的对象,换言之,所有的对其他对象的引用都仍然指向原来的对象。
-
深度克隆:除了浅度克隆要克隆的值外,还负责克隆引用类型的数据。那些引用其他对象的变量将指向被复制过的新对象,而不再是原有的那些被引用的对象。换言之,深度克隆把要复制的对象所引用的对象都复制了一遍,而这种对被引用到的对象的复制叫做间接复制。
深度克隆要深入到多少层,是一个不易确定的问题。在决定以深度克隆的方式复制一个对象的时候,必须决定对间接复制的对象时采取浅度克隆还是继续采用深度克隆。因此,在采取深度克隆时,需要决定多深才算深。此外,在深度克隆的过程中,很可能会出现循环引用的问题,必须小心处理。
2.3 利用序列化实现深度克隆
把对象写到流里的过程是序列化(Serialization)过程;而把对象从流中读出来的过程则叫反序列化(Deserialization)过程。在 Java 语言里深度克隆一个对象,可以先使对象实现 Serializable 接口,然后把对象(实际上只是对象的拷贝)写到一个流里(序列化),再从流里读回来(反序列化),便可以重建对象。
public Object deepClone() throws IOException, ClassNotFoundException{
//将对象写到流里
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
//从流里读回来
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return ois.readObject();
}
说明: 这样做的前提就是对象以及对象内部所有引用到的对象都是可序列化的,否则,就需要仔细考察那些不可序列化的对象可否设成 transient,从而将之排除在复制过程之外。有一些对象,比如 Thread 或 Socket 对象,是不能简单复制或共享的。不管是使用浅度克隆还是深度克隆,只要涉及这样的间接对象,就必须把间接对象设成 transient 而不予复制。
3. 什么时候使用原型模式
如果对象的创建成本比较大,而同一个类的不同对象之间差别不大,在这种情况下,我们可以利用对已有对象(原型)进行复制(或者叫拷贝)的方式来创建新对象,以达到节省创建时间的目的。那何为 "对象的创建成本比较大"?
-
实际上,创建对象包含的申请内存、给成员变量赋值这一过程,本身并不会花费太多时间,或者说对于大部分业务系统来说,这点时间完全是可以忽略的。应用一个复杂的模式,只得到一点点的性能提升,这就是所谓的过度设计,得不偿失。这种情况,不建议使用原型模式。
-
如果对象中的数据需要经过复杂的计算才能得到(比如排序、计算哈希值),或者需要从 RPC、网络、数据库、文件系统等非常慢速的 IO 中读取,这种情况下,我们就可以利用原型模式,从其他已有对象中直接拷贝得到,而不用每次在创建新对象的时候,都重复执行这些耗时的操作。此时,建议使用原型模式,如数据库连接池、线程池等各种资源池。
每天用心记录一点点。内容也许不重要,但习惯很重要!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号