
Hadoop 系列(一)基本概念
Hadoop 系列(一)基本概念
一、Hadoop 简介
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构,它可以使用户在不了解分布式底层细节的情況下开发分布式程序,充分利用集群的威力进行高速运算和存储。
从其定义就可以发现,它解決了两大问题:大数据存储、大数据分析。也就是 Hadoop 的两大核心:HDFS 和 MapReduce。
-
HDFS(Hadoop Distributed File System)是可扩展、容错、高性能的分布式文件系统,异步复制,一次写入多次读取,主要负责存储。
-
MapReduce 为分布式计算框架,包含map(映射)和 reduce(归约)过程,负责在 HDFS 上进行计算。
我们先来了解下 Hadoop 的发展历史,如图 1-1 所示。
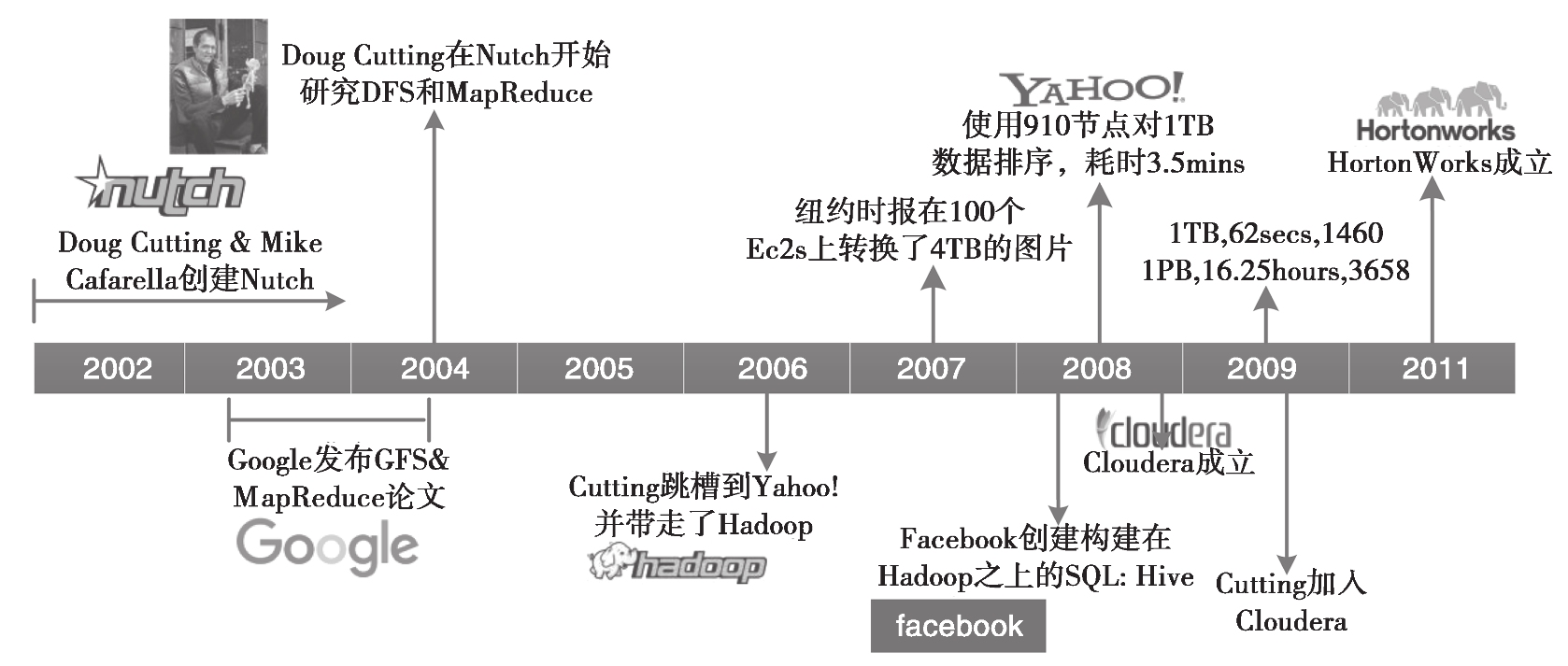
2002~2004 年,第一轮互联网泡沫刚刚破灭,很多互联网从业人员都失业了。我们们的“主角" Doug Cutting 也不例外,他只能写点技术文章赚点稿费来养家糊口。但是 Doug Cutting 不甘寂寞,怀着对梦想和未来的渴望,与他的好朋友 Mike Cafarella 一起开发出一个开源的搜索引擎 Nutch,并历时一年把这个系统做到能支持亿级网页的搜索。但是当时的网页数量远远不止这个规模,所以两人不断改进,想让支持的网页量再多一个数量级。
在 2003 年和 2004 年, Googles 分別公布了 GFS 和 Mapreduce 两篇论文。 Doug Cutting 和 Mike Cafarella 发现这与他们的想法不尽相同,且更加完美,完全脱离了人工运维的状态,实现了自动化。
在经过一系列周密考虑和详细总结后,2006 年, Dog Cutting 放奔创业,随后几经周折加入了 yahoo 公司(Nutch 的部分也被正式引入),机绿巧合下,他以自己儿子的一个玩具大象的名字 Hadoop 命名了该项。
当系统进入 Yahoo 以后,项目逐渐发展并成熟了起来。首先是集群规模,从最开始几十台机器的规模发展到能支持上千个节点的机器,中间做了很多工程性质的工作;然后是除搜索以外的业务开发, Yahoo 逐步将自己广告系统的数据挖掘相关工作也迁移到了 Hadoop 上,使 Hadoop 系统进一步成熟化了。
2007 年,纽约时报在 100 个亚马逊的虚拟机服务器上使用 Hadoop 转换了 4TB 的图片数据更加加深了人们对 Hadoope 的印象。
在 2008 年的时侯,一位 Google 的工程师发现要把当时的 Hadoop 放到任意一个集群中去运是一件很困难的事情,所以就与几个好朋友成立了ー个专门商业化 Hadoop 的公司 Cloudera。同年, Facebook 团队发现他们很多人不会写 Hadoop 的程序,而对 SQL 的一套东西很熟,所以他们就在 Hadoop 上构建了一个叫作 Hive 的软件,专把 SQL 转换为 Hadoop 的 Mapreduce 程序。
2011年, Yahoo 将 Hadoop 团队独立出来,成立了ー个子公司 Hortonworks,专门提供 Hadoop 相关的服务。
说了这么多,那 Hadoop 有哪些优点呢?
Hadoop 是一个能够让用户轻松架构和使用的分布式计算的平台。用户可以轻松地在 Hadoop 发和运行处理海量数据的应用程序。其优点主要有以下几个:
(1) 高可靠性 : Hadoop 按位存储和处理数据的能力值得人们信赖。
(2) 高扩展性 : Hadoop 是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以干计的节点中。
(3) 高效性 : Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
(4) 高容错性 : Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分。
(5) 低成本 : 与一体机、商用数据仓库以及 QlikView、 Yonghong Z- Suites 等数据集市相比,Hadoop 是开源的,项目的软件成本因此会大大降低。
Hadoop 带有用 Java 语言编写的框架,因此运行在 linux 生产平台上是非常理想的, Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。
二、Hadoop 存储 - HDFS
Hadoop 的存储系统是 HDFS(Hadoop Distributed File System)分布式文件系统,对外部客户端而言,HDFS 就像一个传统的分级文件系统,可以进行创建、删除、移动或重命名文件或文件夹等操作,与 Linux 文件系统类似。
但是,Hadoop HDFS 的架构是基于一组特定的节点构建的(见图s),这些节称节点(NameNode,仅一个),它在 HDFS 内部提供元数据服务;第二名称节点(Secondary NameNode),名称节点的帮助节点,主要是为了整合元数据操作(注意不是名称节点的备份);数据节点(DataNode),它为 HDFS 提供存储块。由于仅有一个 NameNode,因此这是 HDFS 的一个缺点(单点失败,在 Hadoop2.x 后有较大改善)。
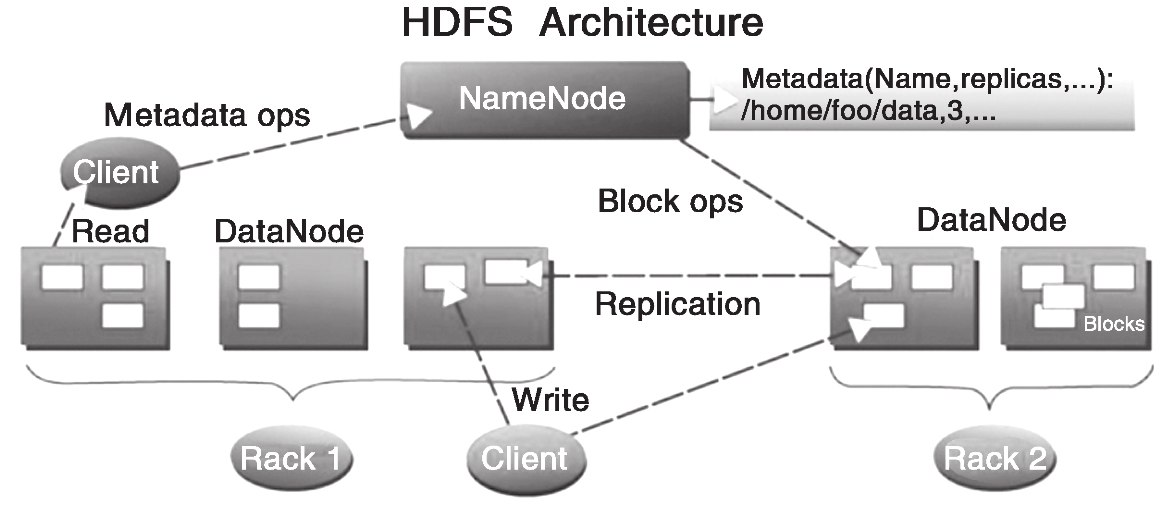
存储在 HDFS 中的文件被分成块,然后这些块被复制到多个数据节点中(DataNode),这与传统的 RAID 架构大不相同。块的大小(通常为 128M)和复制的块数量在创建文件时由客户机决定。名称节点可以控制所有文件操作。HDFS 内部的所有通信都基于标准的 TCP/IP 协议。
关于各个组件的具体描述如下所示:
(1)名称节点(NameNode)
它是一个通常在HDFS架构中单独机器上运行的组件,负责管理文件系统名称空间和控制外部客户机的访问。NameNode决定是否将文件映射到DataNode上的复制块上。对于最常见的3个复制块,第一个复制块存储在同一机架的不同节点上,最后一个复制块存储在不同机架的某个节点上。
(2)数据节点(DataNode)
数据节点也是一个通常在HDFS架构中的单独机器上运行的组件。Hadoop集群包含一个NameNode和大量DataNode。数据节点通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。
数据节点响应来自HDFS客户机的读写请求。它们还响应来自NameNode的创建、删除和复制块的命令。名称节点依赖来自每个数据节点的定期心跳(heartbeat)消息。每条消息都包含一个块报告,名称节点可以根据这个报告验证块映射和其他文件系统元数据。如果数据节点不能发送心跳消息,名称节点将采取修复措施,重新复制在该节点上丢失的块。
(3)第二名称节点(Secondary NameNode)
第二名称节点的作用在于为HDFS中的名称节点提供一个Checkpoint,它只是名称节点的一个助手节点,这也是它在社区内被认为是Checkpoint Node的原因。
如图 1-3 所示,只有在NameNode重启时,edits才会合并到fsimage文件中,从而得到一个文件系统的最新快照。但是在生产环境集群中的NameNode是很少重启的,这意味着当NameNode运行很长时间后,edits文件会变得很大。而当NameNode宕机时,edits就会丢失很多改动,如何解决这个问题呢?
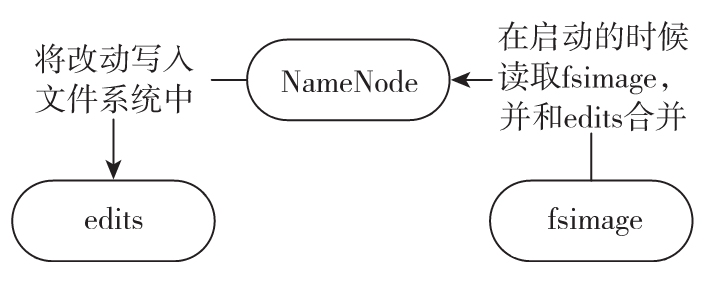
fsimage 是 NameNode 启动时对整个文件系统的快照;edits 是在 NameNode 启动后对文件系统的改动序列。
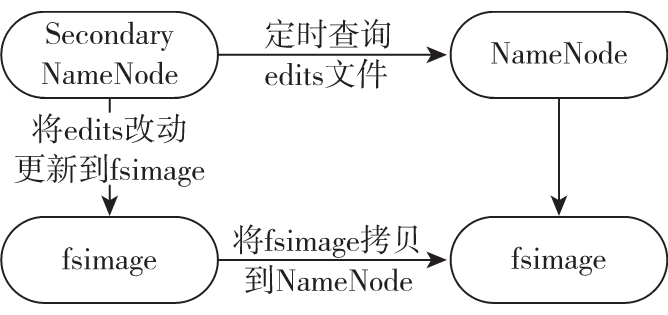
如图 1-4 所示,Secondary NameNode 会定时到 NameNode 去获取名称节点的 edits,并及时更新到自己 fsimage 上。这样,如果 NameNode 宕机,我们也可以使用 Secondary-NameNode 的信息来恢复 NameNode。并且,如果 Secondary NameNode 新的 fsimage 文件达到一定阈值,它就会将其拷贝回名称节点上,这样 NameNode 在下次重启时会使用这个新的 fsimage 文件,从而减少重启的时间。
举个数据上传的例子来深入理解下HDFS内部是怎么做的,如图 1-5 所示。
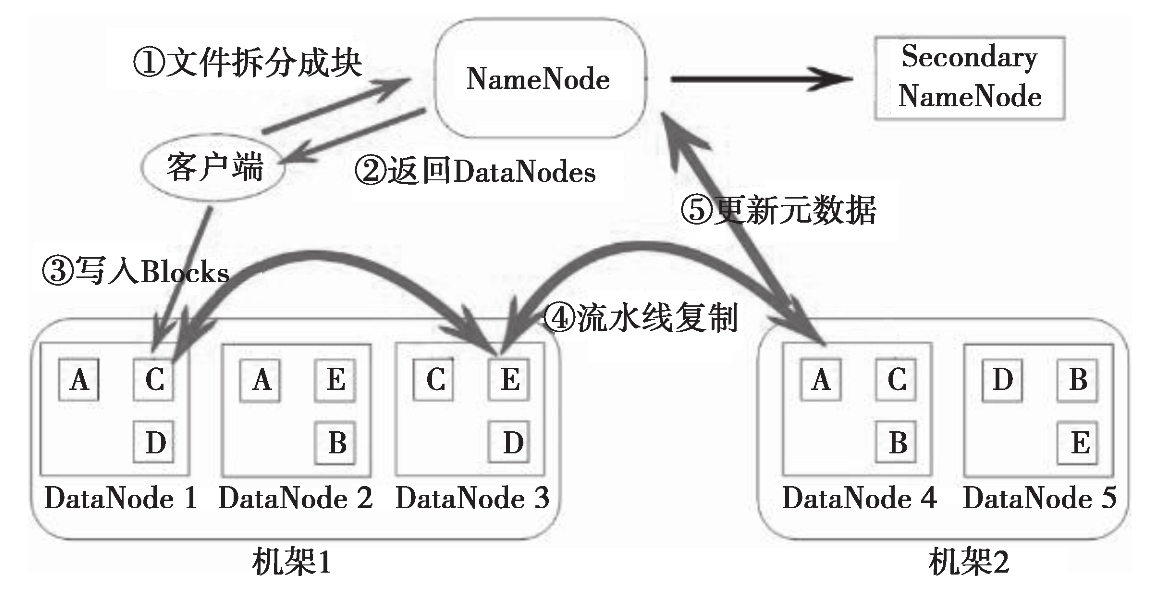
文件在客户端时会被分块,这里可以看到文件被分为 5 个块,分别是:A、B、C、D、E。同时为了负载均衡,所以每个节点有 3 个块。下面来看看具体步骤:
-
客户端将要上传的文件按 128M 的大小分块。
-
客户端向名称节点发送写数据请求。
-
名称节点记录各个 DataNode 信息,并返回可用的 DataNode 列表。
-
客户端直接向 DataNode 发送分割后的文件块,发送过程以流式写入。
-
写入完成后,DataNode 向 NameNode 发送消息,更新元数据。
这里需要注意:
-
写 1T 文件,需要 3T 的存储,3T 的网络流量。
-
在执行读或写的过程中,NameNode 和 DataNode 通过 HeartBeat 进行保存通信,确定 DataNode 活着。如果发现 DataNode 死掉了,就将死掉的 DataNode 上的数据,放到其他节点去,读取时,读其他节点。
-
宕掉一个节点没关系,还有其他节点可以备份;甚至,宕掉某一个机架也没关系;其他机架上也有备份。
三、Hadoop 计算 — MapReduce
MapReduce 是 Google 提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。概念“Map(映射)”和“Reduce(归纳)”以及它们的主要思想,都是从函数式编程语言借来的,还有从矢量编程语言借来的特性。
当前的软件实现是指定一个 Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的 Reduce(归纳)函数,用来保证所有映射的键值对中的每一个共享相同的键组,如图 1-6 所示。

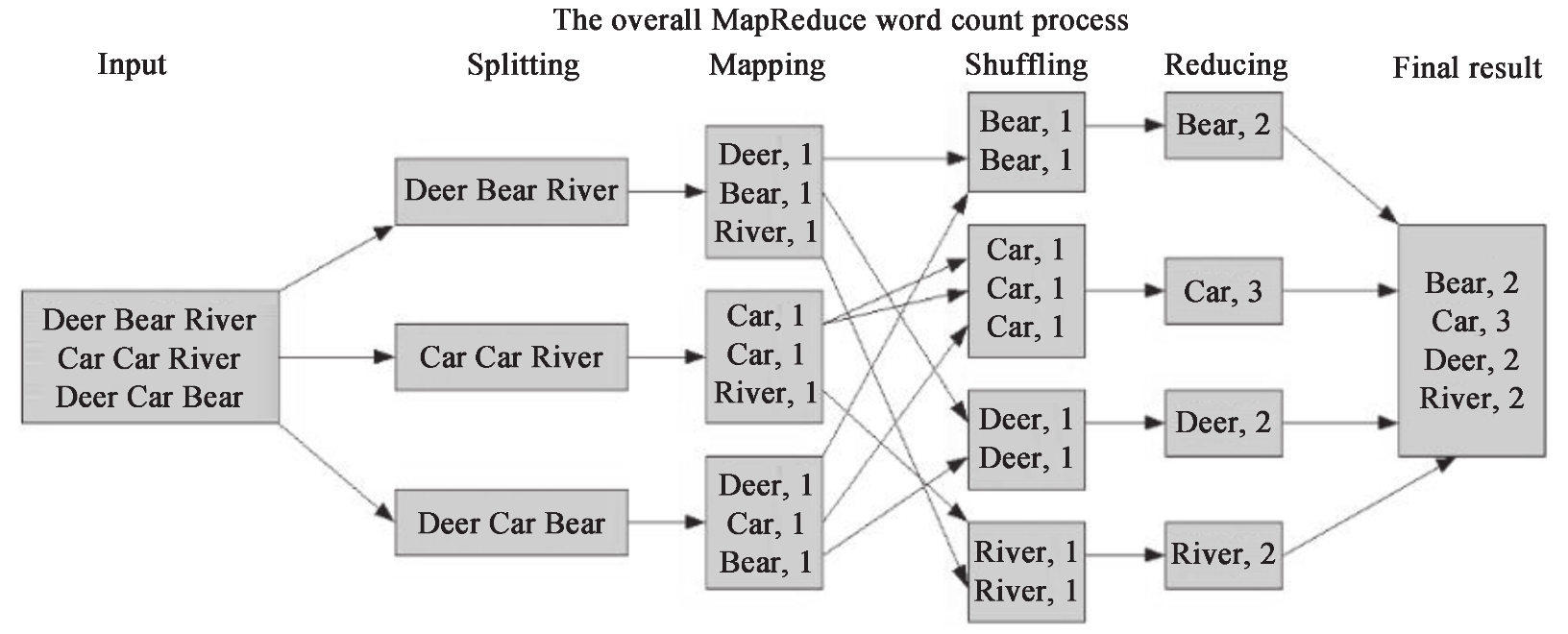
下面将以 Hadoop 的“Hello World”例程—单词计数来分析MapReduce的逻辑,如图 1-7 所示。一般的 MapReduce 程序会经过以下几个过程:输入(Input)、输入分片(Splitting)、Map阶段、Shuffle阶段、Reduce阶段、输出(Final result)。
-
输入就不用说了,数据一般放在 HDFS 上面就可以了,而且文件是被分块的。关于文件块和文件分片的关系,在输入分片中说明。
-
输入分片:在进行 Map 阶段之前,MapReduce 框架会根据输入文件计算输入分片(split),每个输入分片会对应一个 Map 任务,输入分片往往和 HDFS 的块关系很密切。例如,HDFS 的块的大小是 128M,如果我们输入两个文件,大小分别是 27M、129M,那么 27M 的文件会作为一个输入分片(不足 128M 会被当作一个分片),而 129MB 则是两个输入分片(129-128=1,不足 128M,所以 1M 也会被当作一个输入分片),所以,一般来说,一个文件块会对应一个分片。如图 1-7 所示,Splitting 对应下面的三个数据应该理解为三个分片。
-
Map 阶段:这个阶段的处理逻辑其实就是程序员编写好的 Map 函数,因为一个分片对应一个 Map 任务,并且是对应一个文件块,所以这里其实是数据本地化的操作,也就是所谓的移动计算而不是移动数据。如图 1-7 所示,这里的操作其实就是把每句话进行分割,然后得到每个单词,再对每个单词进行映射,得到单词和1的键值对。
-
Shuffle 阶段:这是“奇迹”发生的地方,MapReduce 的核心其实就是 Shuffle。那么 Shuffle 的原理呢?Shuffle 就是将 Map 的输出进行整合,然后作为 Reduce 的输入发送给 Reduce。简单理解就是把所有 Map 的输出按照键进行排序,并且把相对键的键值对整合到同一个组中。如图 1-7 所示,Bear、Car、Deer、River 是排序的,并且 Bear 这个键有两个键值对。
-
Reduce 阶段:与 Map 类似,这里也是用户编写程序的地方,可以针对分组后的键值对进行处理。如图 1-7 所示,针对同一个键 Bear 的所有值进行了一个加法操作,得到 <Bear,2> 这样的键值对。
-
输出:Reduce 的输出直接写入 HDFS 上,同样这个输出文件也是分块的。
说了这么多,其实 MapReduce 的本质用一张图可以完整地表现出来,如图 1-8 所示。
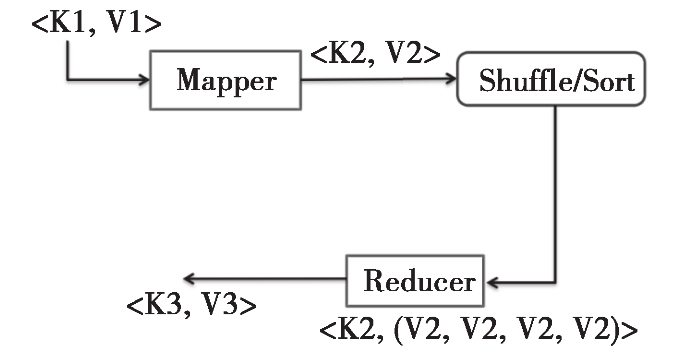
MapReduce 的本质就是把一组键值对 <K1,V1> 经过 Map 阶段映射成新的键值对 <K2,V2>;接着经过 Shuffle/Sort 阶段进行排序和“洗牌”,把键值对排序,同时把相同的键的值整合;最后经过 Reduce 阶段,把整合后的键值对组进行逻辑处理,输出到新的键值对 <K3,V3>。这样的一个过程,其实就是 MapReduce 的本质。
Hadoop MapReduce 可以根据其使用的资源管理框架不同,而分为 MR v1 和 YARN/MR v2 版本,如图 1-9 所示。
在 MR v1 版本中,资源管理主要是 Jobtracker 和 TaskTracker。Jobtracker 主要负责:作业控制(作业分解和状态监控),主要是 MR 任务以及资源管理;而 TaskTracker 主要是调度 Job 的每一个子任务 task;并且接收 JobTracker 的命令。
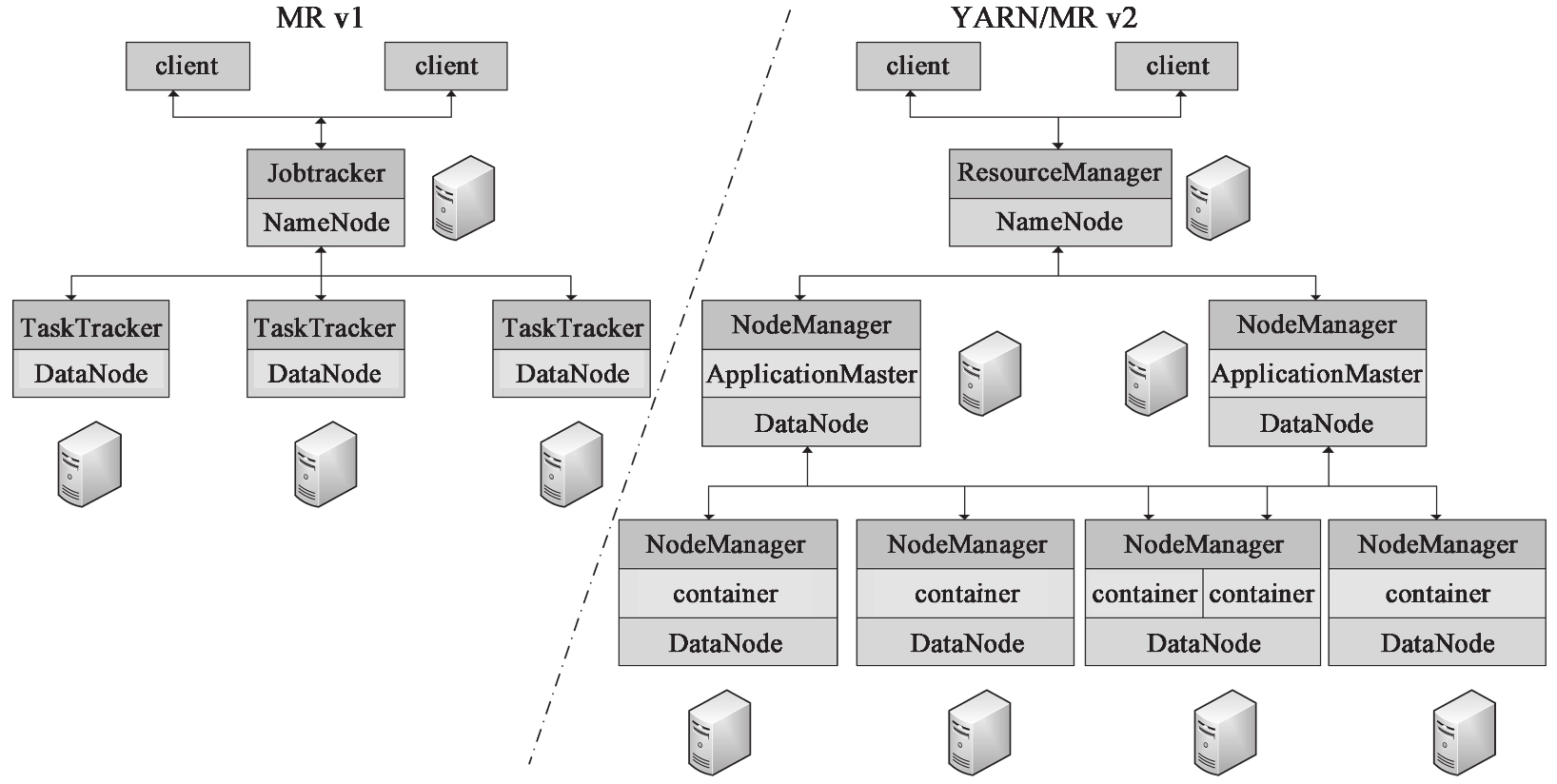
在 YARN/MR v2 版本中,YARN 把 JobTracker 的工作分为两个部分:
-
ResourceManager(资源管理器)全局管理所有应用程序计算资源的分配。
-
ApplicationMaster 负责相应的调度和协调。
NodeManager 是每一台机器框架的代理,是执行应用程序的容器,监控应用程序的资源(CPU、内存、硬盘、网络)使用情况,并且向调度器汇报。
四、Hadoop 资源管理 — YARN
在上一节中我们看到,当 MapReduce 发展到 2.x 时就不使用 JobTracker 来作为自己的资源管理框架,而选择使用 YARN。这里需要说明的是,如果使用 JobTracker 来作为 Hadoop 集群的资源管理框架的话,那么除了 MapReduce 任务以外,不能够运行其他任务。也就是说,如果我们集群的 MapReduce 任务并没有那么饱满的话,集群资源等于是白白浪费的。所以提出了另外的一个资源管理架构 YARN(Yet Another Resource Manager)。这里需要注意,YARN 不是 JobTracker 的简单升级,而是“大换血”。同时 Hadoop 2.X 也包含了此架构。Apache Hadoop 2.X 项目包含以下模块。
-
Hadoop Common:为 Hadoop 其他模块提供支持的基础模块。
-
HDFS:Hadoop:分布式文件系统。
-
YARN:任务分配和集群资源管理框架。
-
MapReduce:并行和可扩展的用于处理大数据的模式。
如图 1-10 所示,YARN 资源管理框架包括 ResourceManager(资源管理器)、Applica-tionMaster、NodeManager(节点管理器)。各个组件描述如下。
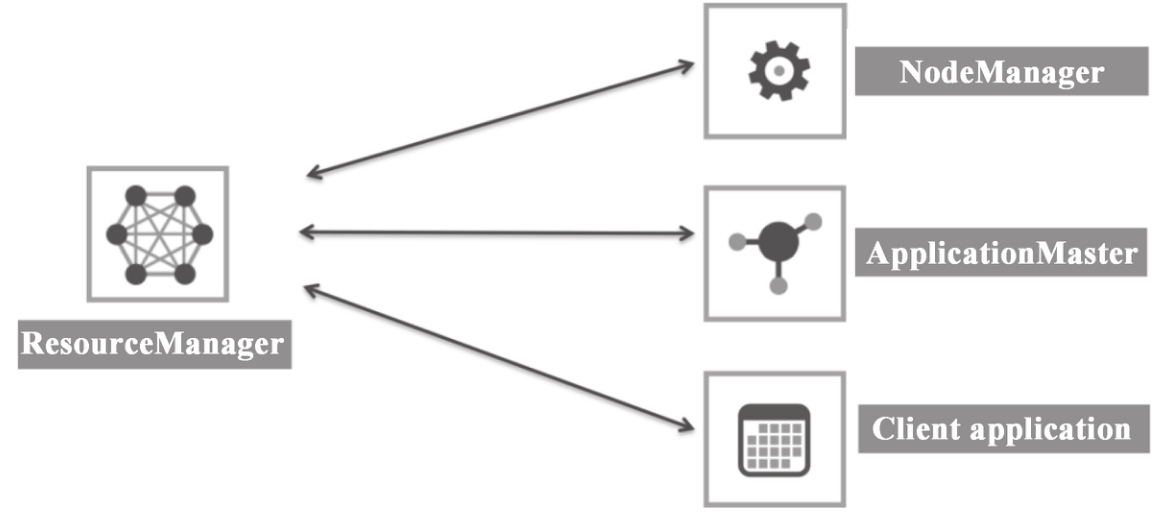
(1)ResourceManager
ResourceManager 是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(ApplicationManager,AM)。
Scheduler 负责分配最少但满足 Application 运行所需的资源量给 Application。Scheduler 只是基于资源的使用情况进行调度,并不负责监视/跟踪 Application 的状态,当然也不会处理失败的 Task。
ApplicationManager 负责处理客户端提交的 Job 以及协商第一个 Container 以供 App-licationMaster 运行,并且在 ApplicationMaster 失败的时候会重新启动 ApplicationMaster(YARN 中使用 Resource Container 概念来管理集群的资源,Resource Container 是资源的抽象,每个 Container 包括一定的内存、IO、网络等资源)。
(2)ApplicationMaster
ApplicatonMaster 是一个框架特殊的库,每个 Application 有一个 ApplicationMaster,主要管理和监控部署在 YARN 集群上的各种应用。
(3)NodeManager
主要负责启动 ResourceManager 分配给 ApplicationMaster 的 Container,并且会监视 Container 的运行情况。在启动 Container 的时候,NodeManager 会设置一些必要的环境变量以及相关文件;当所有准备工作做好后,才会启动该 Container。启动后,NodeManager 会周期性地监视该 Container 运行占用的资源情况,若是超过了该 Container 所声明的资源量,则会 kill 掉该 Container 所代表的进程。
如图 1-11 所示,该集群上有两个任务(对应 Node2、Node6 上面的 AM),并且 Node2 上面的任务运行有 4 个 Container 来执行任务;而 Node6 上面的任务则有 2 个 Container 来执行任务。
五、Hadoop 生态系统
如图 1-12 所示,Hadoop 的生态圈其实就是一群动物在狂欢。我们来看看一些主要的框架。

(1)HBase
HBase(Hadoop Database)是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用 HBase 技术可在廉价 PC Server 上搭建起大规模结构化存储集群。
(2)Hive
Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。
(3)Pig
Pig 是一个基于 Hadoop 的大规模数据分析平台,它提供的 SQL-LIKE 语言叫作 Pig Latin。该语言的编译器会把类 SQL 的数据分析请求转换为一系列经过优化处理的 Map-Reduce 运算。
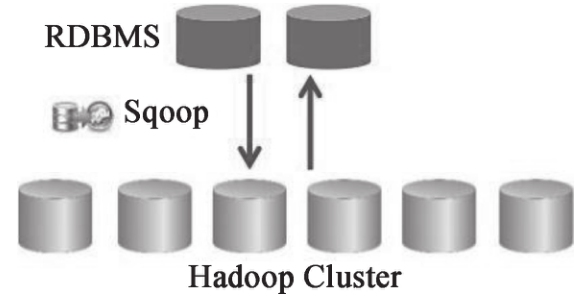
(4)Sqoop
Sqoop 是一款开源的工具,主要用于在 Hadoop(Hive)与传统的数据库(MySQL、post-gresql等)间进行数据的传递,可以将一个关系型数据库中的数据导入 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导入关系型数据库中,如图 1-13 所示。
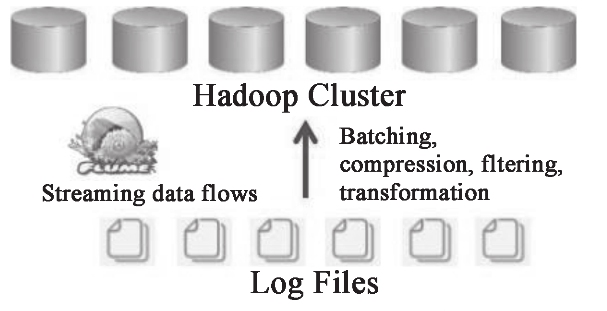
(5)Flume
Flume 是 Cloudera 提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据。同时,Flume 提供对数据进行简单处理并写到各种数据接受方(可定制)的能力,如图 1-14 所示。
(6)Oozie
Oozie 是基于 Hadoop 的调度器,以 XML 的形式写调度流程,可以调度 Mr、Pig、Hive、shell、jar 任务等。
主要的功能如下。
-
Workflow:顺序执行流程节点,支持 fork(分支多个节点)、join(将多个节点合并为一个)。
-
Coordinator:定时触发 Workflow。
-
Bundle Job:绑定多个 Coordinator。
(7)Chukwa
Chukwa 是一个开源的、用于监控大型分布式系统的数据收集系统。它构建在 Hadoop 的 HDFS 和 MapReduce 框架上,继承了 Hadoop 的可伸缩性和鲁棒性。Chukwa 还包含了一个强大和灵活的工具集,可用于展示、监控和分析已收集的数据。
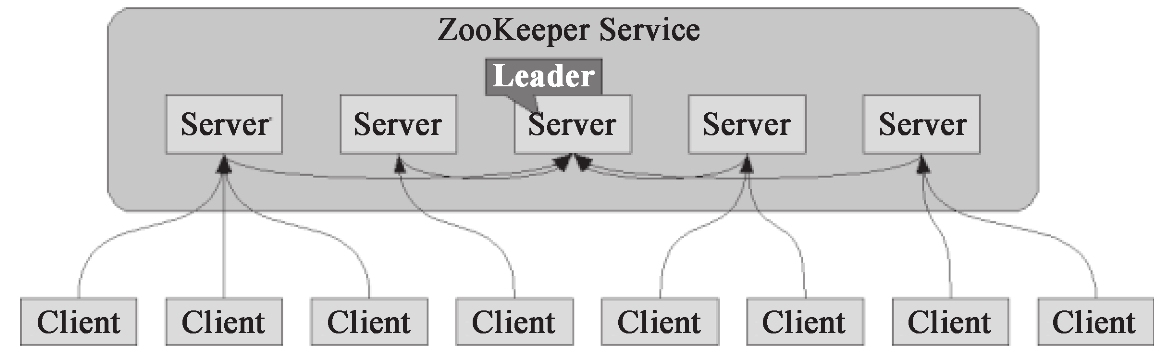
(8)ZooKeeper
ZooKeeper 是一个开放源码的分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现,是 Hadoop 和 Hbase 的重要组件,如图 1-15 所示。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
(9)Avro
Avro 是一个数据序列化的系统。它可以提供:丰富的数据结构类型、快速可压缩的二进制数据形式、存储持久数据的文件容器、远程过程调用 RPC。
(10)Mahout
Mahout 是 Apache Software Foundation(ASF)旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout 包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,可以有效地将 Mahout 扩展到云中。
每天用心记录一点点。内容也许不重要,但习惯很重要!
本文来自 《Hadoop与大数据挖掘》


 浙公网安备 33010602011771号
浙公网安备 33010602011771号